In this chapter, you will understand and demonstrate knowledge in the following areas:
| Tuning for differing application requirements | |
| How to tune applications |
The first areas of any database that require tuning, in most cases, are the queries and applications that access the database. By far, the greatest improvement to performance that can be made is achieved through this critical tuning step. Other areas of tuning, like memory and disk usage, though beneficial to the database as a whole, don’t have as dramatic results as a change in the SQL statements of an application. When there is a performance issue on the machine, the DBA’s first inclination should be to work with the application developer. In fact, this material may actually be of more use to developers than DBAs. However, the DBA should grow accustomed to serving in the role of Oracle guru around the office. And, of course, the OCP certification series for DBAs requires that the DBA know how to tune applications—about 10 percent of OCP Exam 4 content will be on these areas of performance tuning.
In this section, you will cover the following topics related to tuning for different application requirements:
| Demands of online transaction processing systems | |
| Demands of decision support systems | |
| The requirements of client/server environments | |
| Configuring systems temporarily for particular needs |
The design of a database should take into consideration as many aspects of how the production system will work as possible. This discussion will focus on the design characteristics of different types of databases that facilitate those strategies already covered. First, understand some different types of applications organizations use in conjunction with Oracle. Three common ones are online transaction processing applications, decision support systems, and client/server applications.
Online transaction processing, or OLTP, is a common system in many organizations. When you think about data entry, you are thinking about OLTP. These types of applications are characterized by high data change activity, such as inserts or updates, usually performed by a large user base. Some examples of this type of system include order entry systems, ticketing systems, timesheet entry systems, payments received systems, and other systems representing the entry and change of mass amounts of data. Figure 17-1 shows information about data volume and direction on OLTP systems.
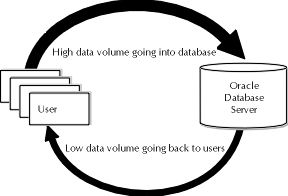
Figure 1: Data volume and direction in OLTP applications
Data in these systems is highly volatile. Because data changes quickly and frequently, one design characteristic for OLTP systems is the ability to enter, change, and correct data quickly without sacrificing accuracy. Since many users of the system may manipulate the same pieces or areas of data, mechanisms must exist to prevent users from overwriting one another’s data. Finally, because users may make changes or additions to the database based on existing data, there must be mechanisms to see changes online quickly.
There are several design paradoxes inherent in OLTP systems. First, OLTP systems need to be designed to facilitate fast data entry without sacrificing accuracy. Any mechanism that checks the data being entered will cause some performance degradation. Oracle provides a good structure for checking data entry in the form of integrity constraints, such as check constraints and foreign keys. Since these mechanisms are built into the data definition language, they are more efficient than using table triggers to enforce integrity. Oracle then solves this paradox for all but the most complex business rules that must be enforced with triggers.
Typically, OLTP systems have a need to see the data in real time, which creates one of the largest design paradoxes in OLTP systems. Oracle uses several mechanisms to facilitate data retrieval. Those mechanisms are indexes and clusters. Indexes and clusters work better on tables that experience infrequent data change. This is true for indexes because every table data change on an indexed column means a required change to the index. In the case of clusters, since the cluster must be carefully sized to allow so much data to hang off the cluster index, data changes in clustered tables can lead to row migration and chaining—two effects that will kill any performance gains the cluster may give. However, data change is the primary function of an OLTP system. The designers and DBAs of such systems then must work with users to create an effective trade-off between viewing data quickly and making data changes quickly.
This goal can be accomplished through data normalization. By reducing functional dependency between pieces of information as part of the normalization process, the database can store pieces of data indexed on the table’s primary key. This design feature, used in combination with a few appropriately created foreign keys to speed table joins, will provide data retrieval performance that is acceptable in most cases.
If possible, DBAs should participate in the data modeling process to better understand which tables are frequently updated. In general, it is wise for the DBA to put tables that are frequently updated in a special data tablespace that is backed up frequently. Also, that tablespace can have default settings for data blocks with a high pctfree and a low pctused to reduce the chances of data migration and row chaining. Although configuring data blocks in this way can waste disk space, for reasons to be explained later, the desired effect of preventing row migration is obtained. Finally, keep use of indexes as low as possible to prevent the overhead involved in updating both the table and the index.
Decision support systems, sometimes referred to as DSS, offer some challenges that are different from OLTP systems. Decision support systems are used to generate meaningful report information from large volumes of data. A DSS application may often be used in conjunction with an OLTP system, but since their design needs differ greatly, it is often a bad idea to use an OLTP system for decision support needs. Whereas the user population for an OLTP system may be large, the user population for a DSS application is usually limited to a small group. Some decision support system examples include cash flow forecasting tools that work in conjunction with order entry systems that help an organization determine how large a cash reserve they should hold against anticipated returns. Another example is a marketing tool working in conjunction with an order entry system.
The key feature of a decision support system is fast access to large amounts of data. The trade-off between accessing data quickly and updating it quickly is a key point from OLTP systems that should be discussed here. As part of the design process, it should be determined what mechanisms will update the data in the decision support system. Usually, data flows from the OLTP system (or some other source) into the decision support system on a batch schedule. Users of the decision support system rarely, if ever, update or insert new data into the system, as it is designed for query access only. Figure 17-2 illustrates data volume and direction in DSS applications.
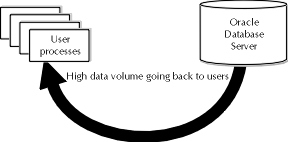
Figure 2: Data volume and direction in decision support systems
Since the decision support system data is updated on a regular batch schedule, the DBA has more options available for performance tuning. Heavy usage of indexes and clusters are both options because data updates happen less often. A process for re-creating indexes and clusters can be designed in conjunction with the batch update so as to prevent the ill effects of updating indexed or clustered data. In some cases, the DBA may find that some tables never change. If this is the case, the DBA may assess that it makes sense to gather those tables into a special tablespace and make the tablespace access read only.
The name "client/server" implies that there are two components for these types of systems. Those components are a client process and a server process. The term process is operative here. Client/server describes a relationship between two processes that are communicating with one another as they execute. These two processes can execute on separate machinery, utilizing the advantages inherent in having multiple CPUs dedicated to the task of solving problems and running the process. The client consists of user processes, executing most often on desktops, that may have some graphical user interface that enables the application to be more friendly in its interaction with users. The server, in this case, is the Oracle database with all of its background processes, memory areas, disk utilization, etc. Figure 17-3 illustrates the question of how many components comprise a client/server application.
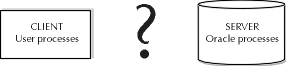
Figure 3: Are there two main components in client/server?
What is the missing link in Figure 17-3? The name "client/server" leaves out the most important facet of the client/server architecture—that unseen feature that allows for communication between the two processes. That feature is a network interface. The complete architecture must include a network component that allows for two processes to pass information back and forth between them. The completed architecture is given in Figure 17-4.

Figure 4: Three main components of client/server networks
With this three-piece architecture in mind, the discussion proceeds by identifying what role Oracle plays in the communication process. Simply having a TCP/IP network connection between the machine running client software and the machine running server software is incomplete. While the hardware and connectivity are there, a language barrier still prevents effective communication. Oracle offers a solution to this issue with a product called SQL*Net. This application is used by both clients and servers to communicate with one another. Without the SQL*Net layer acting as the interpreter, the client process and the server process are unable to interconnect.
Consider the client/server architecture created with the use of SQL*Net in some detail. The cornerstone of SQL*Net is a process called a listener. This process does just that--it listens to the network connection for requests from the client to come in and request data. A listener can be thought of as similar in many ways to a radio. The listener tunes into a particular "frequency" to listen for connections on the type of network being used, and "hears" requests issuing from only that network. In heterogeneous networking environments, there may be several different listeners in place on the machine running Oracle Server.
Once the listener "hears" a request for information, one of two things can happen, depending on whether the DBA has opted to use dedicated servers on the Oracle database, or whether the DBA has chosen to use the multithreaded server (MTS) option. In the dedicated server configuration, the user process that the listener has just "heard" is now routed to a server process. Recall in Unit II the discussion of the server process, which obtains data from disk on behalf of the user. In the dedicated server architecture, there is a one-to-one relationship between user processes and the server process, effectively giving every user its own server.
The dedicated server configuration can take a lot of memory to run on the Oracle database, particularly if a lot of users are connected. Oracle offers an alternative to the dedicated server option with the use of MTS. In the MTS architecture, Oracle has another process running called a dispatcher. When the SQL*Net listener hears a user request, it routes the user process to a dispatcher, which then finds a server process for the user process. One "shared" server process handles data requests for multiple user processes, thereby reducing the amount of memory required for server processes running on the Oracle database when a lot of users are connected. Figure 17-5 illustrates the path a user process will take from initially contacting Oracle with a data request, to being heard by the listener, to being given to a dispatcher, and being routed to a shared server. The rest of the discussion on client/server will assume the DBA is taking advantage of the MTS architecture.
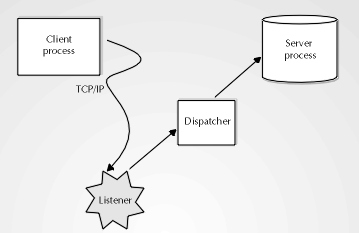
Figure 5: Interprocess communication
In client/server environments using MTS where listeners and dispatchers are used to broker database services to multiple client requests, the database can be optimized to handle those client requests with a minimal number of processes on the server. This task can be accomplished with the MTS option running on the Oracle database. More discussion on the multithreaded server option on the Oracle database will appear in Chapters 18, 20, and 25.
In general, the DBA will focus most of his or her tuning energy on tuning the production needs for a particular application. Sometimes, however, those systems will require some special tuning or configuration based on a temporary need. That need may take many forms. For example, an OLTP application may expect that there will be a window of time when usage will be particularly heavy. In this case, the DBA may plan in advance for that anticipated increase in user activity. Some steps the DBA might take could be to increase the number of rollback segments available on the system, reconfigure some initialization parameters related to redo log usage, etc.
One approach the DBA may take in preparing for the increase in database usage may be to alter the init.ora file to reflect the necessary parameters for the configuration change. However, making some changes to the database to suit anticipated needs of the system may not be in the best interests of the current needs of that system. In some cases, the DBA is better off waiting until the last possible moment to make the changes to suit a particular need.
The method a DBA may use in order to suit the different needs of the applications at different times is to place any DDL changes that need to happen in a script to be run when the time is right to make the changes, keeping another set of scripts on hand that will reverse the changes. This plan may include having a few different copies of the initialization script init.ora on hand, each with different settings appropriate to different usage situations, in order to facilitate the process of reconfiguring the database on short notice.
In order to reconfigure the database with a new set of parameters, the parameters should be placed in another version of init.ora that contains the specifications that must stay the same, such as DB_NAME, CONTROL_FILES, DB_BLOCK_SIZE, and other parameters that identify a unique database. When the database must be altered to handle a particular situation, the DBA can bring down the database instance and restart it using the copy of init.ora especially designed for the situation. Additionally, the DBA can execute the scripts prepared for altering other aspects of the database for the particular situation. When the need passes, the DBA can set the database to run as it did before by executing the scripts designed to reverse whatever alterations took place, bring down the database, and restart with the old init.ora file.
Another example of when the approach of having special init.ora files on hand to configure the database for specific needs is when the DBA needs to set up the database for maintenance. Since having the database tuned to handle online transaction processing, decision support, and other application needs could interfere with the upgrade or maintenance activities a DBA must perform, it is advisable to have a mechanism that easily reconfigures the database in such a way as to allow the DBA to perform maintenance quickly. Usually, DBAs have only a short time to perform maintenance activities like reorganizing tablespaces or distributing file I/O. The DBA should ensure the database is configured to make maintenance go quickly.
In this section, you will cover the following topics related to tuning applications:
| Tuning SQL statements | |
| Identifying inefficient SQL | |
| Using tools to diagnose problems | |
| Using the DBMS_APPLICATION_INFO package |
To highlight the importance of tuning applications, consider the following situation that actually happened to a Fortune 500 company that used Oracle. One of their applications was used by nearly two-thirds of the over 70,000 employees of this company, and had several batch processes feeding data into it. Over the course of several weeks, during which time several thousand employees were added to the system, the execution of one batch process went from 4 hours to 26 hours. The company had grown accustomed to long-running batch processes, but this process ran so long that it couldn’t be considered a daily job anymore. Apparently there were some poor comparison operations specified that caused a table to be joined to itself about 15 times before any results could be obtained. The solution wasn’t a famous "one-line code fix," but it didn’t take long to figure out what the solution was, and once implemented, the 26-hour process became a 30-minute one. One year later, the organization n doubled its user base, as well as the amount of data being fed through this batch process, and it still ran in under 40 minutes. Such is the power of application tuning.
Of all areas in performance tuning, none are more important than tuning the application. Often, the first and last word in turning an application that drags its feet and turning it into one that runs like a well-oiled machine is "TUNE SQL FIRST." Since the solution to most performance situations is a change in the query that causes poor performance, Oracle recommends that all DBAs consider any changes to the SQL statements themselves as the first step in every tuning situation, except ones that are obviously not related to specific SQL statements.
The reason that the importance of SQL statement tuning cannot be overstated is because most performance problems that occur can be solved with a change related to the statement. In fact, the largest performance improvements that can be gained in performance tuning are made when the DBA or developer analyzes how the SQL statement is executing and determines simply if an index can be used. By simply spending the time it takes to determine that a query is not using an index properly and changing the query so that it does, the DBA can prevent a frustrating trip through the SGA, disk I/O, and performance views related to contention, making sweeping changes that break other queries, only to find that the original problem was simply that an index was dropped causing the query to perform a full table scan on a table with 1,000,000 rows.
So, another important point to make about tuning SQL first is scope. Unless it can be determined that all SQL statements are affected by some adversity on the Oracle database configuration, the DBA should remain focused on limiting his or her scope to the possibility that this query is the only one having a problem, and should try to find a localized solution for that one query. Later in this section, some tools will be introduced to help the DBA do just that.
The final point to make about the importance of SQL statement tuning is one of user satisfaction. If queries are humming along, no one will complain. As soon as a query breaks, the user who was executing it will have a support issue. The faster the SQL statement can be fixed with minimal impact on everyone else on the database, the better off everyone using the system will be, including the DBA.
Several things are happening behind the scenes when Oracle is executing a SQL statement. First, the SQL engine takes the statement and breaks it into a set of operations Oracle will perform in order to obtain the data. Depending on how a table is configured, and on the SQL statement being performed, those activities may include the following:
| Table accesses | |
| Index accesses | |
| Data filters | |
| Operations to join multiple data | |
| Set operations like union, intersect, and minus | |
| Cluster and hash operations |
Oracle is highly flexible in that the user can specify the fast way and the slow way to select data in the system. The key to selecting data quickly every time is to have the data appropriately configured in the database for fast selection, and know how the data is configured for fast selection and use the access path laid out by that configuration. Generally, it is easier to set up an application that uses efficient SQL statements to select data than it is to allow users to select their own data using ad hoc queries. The developer can predict the behavior of an application’s query and plan the database for that activity better than he or she can predict how a user may want to perform self-written queries against the system.
The first possible cause for inefficient SQL activity in the database is when a database performs a full table scan to find the data requested by the query. Recall from Unit II that a full table scan is when Oracle goes through every row in a table to find the data a query is asking for. The full table scan is the ultimate level of nonselective data querying. The length of time required to execute this type of query is in direct proportion to the number of rows the table has. Obviously, queries that produce full table scans on large tables are going to see the biggest performance hit.
What are some reasons that a query’s execution produces a full table scan? A query that uses nonindexed columns in the where clause will produce a full table scan, as will a query that uses an indexed column but performs some operation on the column. For example, assume that table EMP has an index on column EMPID, which is of a VARCHAR2 datatype. The following statement will produce a full table scan, even though the appropriate column was indexed:
SELECT *
FROM emp
WHERE nvl(empid,‘00000’) = ‘65439’;
Even though the EMPID column was indexed, the index will not be used because the where clause performs a data operation on the indexed column. This operation forces Oracle to use a full table scan for that query. Other reasons a full table scan may occur include the lack of a where clause on the query, selecting an indexed column value based on an inequality or a comparison to NULL, and querying a table based on a composite index but placing the columns in the composite index in the wrong order (not the order they are stored in on the index). An example of misusing a composite index that results in a full table scan follows. If the EMP table has a three-column composite index defined as EMPID, LNAME, and FNAME, the query in the following code block will not use the index on the primary key:
SELECT *
FROM emp
WHERE lname = ‘FULLER’
AND empid = ‘439394’;
Oracle is very particular about order in cases where composite indexes are available. In order for the above query to use the index, the where clause should have the columns in the order that they are indexed.
SELECT *
FROM emp
WHERE empid = ‘439394’
AND lname = ‘FULLER’;
Queries that use full table scans decrease database performance in other ways. Recall the discussion in Unit II of the algorithm used to pull data blocks from disk. The server process moves blocks into the buffer cache from the table for the query. If there isn’t enough room, Oracle uses the least recently used (LRU) algorithm to determine which blocks to get rid of to make room for new buffers. Blocks selected for full table scans are placed at the end of that LRU list so that those blocks are paged out of memory first. Although this algorithm prevents blocks in use by other queries from being paged out of the buffer cache, it can also slow down other queries looking for blocks used in the full table scan. It may take multiple reads for other queries using the block’s data to keep the block in memory.
Some queries run inefficiently due to other reasons as well. A select statement that uses a B-tree index may still perform poorly if there are few unique values in the index. Recall the discussion for using B-tree and bitmap indexes in Unit I. Oracle refers to the uniqueness of values in an index as the index’s cardinality. An example of an index with low cardinality would be an index on employee gender, using the EMP table example. Since there can be only two unique values, male and female, the cardinality or uniqueness of values in this index would be low. In fact, in some cases a query may experience improved performance if the statement used a full table scan rather than the index with low cardinality. If you must index a column with low cardinality, do not use the traditional B-tree index. Instead, use a bitmap index.
Another cause for poor performance on a query can be the use of views in the query. In trying to obtain the data for a query that has reference to a view in conjunction with joins from other tables, sometimes Oracle will attempt to resolve the view before resolving the rest of the query. This act will produce a large result set for the view, to which Oracle will then apply the rest of the where clause as a filter. If the dataset produced by resolving the view is large, then the performance of the query will be poor.
There are several tools that help in the performance tuning process. These tools can be used to identify how the Oracle optimizer handles certain queries based on several criteria, such as the existence of indexes that can be used, whether the table is clustered, whether there are table performance statistics available, or whether rule-based or cost-based optimization is in use. One of the tools the DBA can use to tune Oracle queries has already been identified, the explain plan statement. In this section, more details about interpreting execution plans, along with common tuning techniques will be presented.
DBAs can use the explain plan statement to determine how the optimizer will execute the query in question. The DBA or developer can submit a query to the database using explain plan, and the database will list the plan of execution it determines it will take based on the many different factors listed at the beginning of the section. To use explain plan, a special table must exist in the user’s schema. The name of that special table is PLAN_TABLE. This table can be created in the user’s schema with the utlxplan.sql script provided in the rdbms/admin directory under the Oracle software home directory. Once the PLAN_TABLE is in place, the DBA is ready to begin using explain plan to optimize query performance.
The syntax requirements for explain plan are as follows. First, the explain plan clause identifies the statement as one that should have the execution plan created. The following clause is the set statement_id clause. It is used to identify the plan for later review. Neglecting to specify a STATEMENT_ID for the execution plan will make it difficult to obtain the plan. Finally, the into table_name for clause identifies the table into which explain plan will put the execution information. The explain plan statement needn’t use the PLAN_TABLE, so long as an alternate table is specified that contains the same columns specified as PLAN_TABLE.
EXPLAIN PLAN
SET STATEMENT_ID = ‘your_statement_id’
INTO plan_table FOR
SELECT *
FROM emp
WHERE empid = ‘43355’;
After executing the explain plan statement, the DBA can recall the execution plan from the PLAN_TABLE (or other appropriately defined location) using a query similar to the following, modified from a utility provided in the Oracle Server release software:
SELECT LPAD(‘ ’,2*level) || operation || ‘ ’
|| options || ‘ ’ || object_name AS query_plan
FROM plan_table
WHERE statement_id = ‘your_statement_id’
CONNECT BY PRIOR ID = parent_id and statement_id = ‘your_statement_id’
START WITH ID=1;
This query will produce the plan for the query just explained. The connect by clause joins the retrieved rows to the user in a hierarchical format. In the example used above, the resulting set that will come out of PLAN_TABLE when the retrieval query is executed will be similar in content to the listing that appears below:
query_plan
-----------------------------------------------
TABLE ACCESS EMP BY ROWID
INDEX RANGE SCAN PK_EMP_01
The execution plan is interpreted in the following way. Innermost rows are the first events taking place in the execution plan. From there, the plan is evaluated from inside out, with the result sets from inner operations feeding as input to the outer operations. For multiple hierarchies as indicated by an additional series of inserts, often appearing in execution plans for join queries, the resulting execution plan is also read from top to bottom. In our example above, we have good usage of an index driving the overall table access operation that will produce the data the query has asked for. If the query had not used an index, however, the execution plan would have consisted of one statement—a full table scan on table EMP.
To understand some other SQL statement processing operations that may appear in an execution plan, refer to the following listing:
| Operation | Meaning |
| TABLE ACCESS FULL | Oracle will look at every row in the table to find the requested information. This is usually the slowest way to access a table. |
| TABLE ACCESS BY ROWID | Oracle will use the ROWID method to find a row in the table. ROWID is a special column detailing an exact Oracle block where the row can be found. This is the fastest way to access a table. |
| INDEX RANGE SCAN | Oracle will search an index for a range of values. Usually, this event occurs when a range or between operation is specified by the query or when only the leading columns in a composite index are specified by the where clause. Can perform well or poorly, based on the size of the range and the fragmentation of the index. |
| INDEX UNIQUE SCAN | Oracle will perform this operation when the table’s primary key or a unique key is part of the where clause. This is the most efficient way to search an index. |
| NESTED LOOPS | Indicates that a join operation is occurring. Can perform well or poorly, depending on performance on the index and table operations of the individual tables being joined. |
Another method available for generating execution plans in Oracle is the set autotrace on command. Executing this command will effectively execute an explain plan for every SQL statement executed in the session for as long as the autotrace feature is set on. The primary difference between this feature and simply executing the explain plan feature is ease of use and availability of execution plan. Using autotrace for an entire SQL session with the Oracle database is much easier than manually keying in the explain plan syntax every time you execute a query, followed by actually executing the query against the database. Remember, when you specify a query using explain plan, you don’t actually execute the query against the database. However, there is a trade-off involved. When using autotrace, the execution plan for any query is not available for review until the actual query is complete. This fact somewhat defeats the purpose of performance tuning, because the DBA will not know what the execution plan for that query was until the database has actually executed the plan. Eventually, the DBA will know what went wrong, but not before the problem actually occurs. However, the ease of use that autotrace affords may outweigh the timeliness in which it provides execution plans.
The database provides a pair of tools to monitor query performance for tuning purposes called SQL Trace and TKPROF. SQL Trace puts hard numbers next to the execution plan of SQL statements to identify other problem areas in the system, creating a file detailing the appropriate statistical raw data. TKPROF is then executed on the output file, turning raw data into formatted output. SQL Trace provides the following pieces of information to aid in the SQL statement tuning process:
| parse, execute, fetch counts | Number of times the parse, execute, and fetch operations were processed in Oracle’s handling of this query |
| Processor time elapsed query time |
The CPU and real elapsed time for execution of this statement |
Physical/logical reads |
Total number of data blocks read from the datafiles on disks for parse, execute, and fetch portions of the query |
Rows processed |
Total number of rows processed by Oracle to produce the result set, excluding rows processed as part of subqueries |
Library cache misses |
Number of times the parsed statement had to be loaded into the library cache for usage |
SQL Trace can analyze SQL statements on a session-wide and instance-wide basis. If tracing is started instance-wide, then every session that connects to the instance will have tracing enabled for it. If tracing is started session-wide, then only the session that has enabled SQL Trace will have trace activity captured for it.
There are three initialization parameters that must be set properly in order for Trace to work effectively on the instance or session. The first parameter is TIMED_STATISTICS. This parameter must be set to TRUE in order to use SQL Trace either on an instance-wide or session-wide level. Without this parameter set to TRUE, the collection of CPU statistics and elapsed time will not be enabled for the trace. Since setting this statistic to TRUE causes some additional overhead at the processor level, some DBAs choose only to set this parameter to TRUE when statistics collection is necessary. As such, use of this parameter sets forth the whole idea of having multiple init.ora files for fast reconfiguration of the database when certain needs arise.
The next parameter that should be considered is MAX_DUMP_FILE_SIZE. Output file size for the session’s trace file is in operating system blocks. In some cases, the SQL Trace output trace file will not contain all data that is captured by the tracing utility and may appear truncated. The default value for this setting is 500, which can translates into 500 operating system blocks’ worth of bytes that can be stored in the trace file. If Trace is enabled on the database yet the desired statistics that it generates do not seem to be present, and if the file itself looks cut off, the DBA should adjust the value of this initialization parameter and try executing the tracing process again.
The final parameter is USER_DUMP_DEST. The parameter simply tells Oracle where to put the trace file (indeed, all dump files) on the machine’s filesystem. The key point of note here is that the destination should be specified as an absolute directory pathname.
Setting trace on an instance-wide level requires setting the SQL_TRACE parameter to TRUE in the init.ora file, and then restarting the instance. Setting Trace on a session-wide level overrides the instance-wide trace specification, and can be executed in several ways. The first way utilizes the alter session statement.
ALTER SESSION SET SQL_TRACE=TRUE;
The second method uses a special package available that is called DBMS_SESSION. Within this package is a special procedure called SET_SQL_TRACE. The user can execute this procedure in order to start tracing statistics on SQL statements in the session as well. Another method to set tracing in the current session, and the only non-instance-wide way to set tracing for sessions other than the current one is to execute another procedure in DBMS_SYSTEM, the set_sql_trace_in_session( ) procedure. The user executing this process should obtain the appropriate values in the SESSION_ID and SERIAL# columns from the V$SESSION view for the session to have tracing enabled. These two values must be passed into the procedure along with the SQL_TRACE setting (TRUE or FALSE).
After setting trace to run on the instance or session, Oracle will generate output to the trace file for all queries executed for the session. The trace file output will be hard to interpret by itself, so in conjunction with using Trace to gather statistics, the user should execute TKPROF to turn those statistics into answers to tuning questions. TKPROF tales the trace file and produces an output file named according to the specifications of the user. TKPROF has many options for its different features, including several used to specify sort order for query statistics and the capability to insert statistics records into the database. The typical output for TKPROF may consist of the following components. First is the SQL statement text and the execution plan. Next, TKPROF will display trace statistics such as CPU time and elapsed time, then rows fetched. Finally, TKPROF will display library cache misses for parsing and executing the statement.
In complex development environments, it can sometimes be hard to track the activities of certain stored procedures, packages, Pro*C programs, Oracle Forms programs, and more using conventional methods for performance tuning like explain plan and SQL Trace. Oracle provides enhanced features in a package called DBMS_APPLICATION_INFO that allow developers and DBAs the ability to track the performance of different applications using more advanced debugging techniques that utilize dynamic performance views native to the Oracle environment. The dynamic performance views that Oracle will use to track performance for these processes are V$SESSION and V$SQLAREA.
The process of employing the DBMS_APPLICATION_INFO features comprises an important development step known as registering the application with Oracle. Once the procedures of this package are utilized in the program, the DBA, developers, or other persons dedicated to the task of tuning can use this registration information to track the performance of registered applications and recommend areas for tuning improvement. The following subsections give the names of each procedure, the accepted parameters, and an example of the procedure in a sample PL/SQL block for the various procedures available in DBMS_APPLICATION_INFO. Please note that the functionality on the procedures can be duplicated with queries on the V$SQLAREA view using the MODULE column.
Identifies a module name for the block of code to Oracle.
Parameters
Module_name IN VARCHAR2
Action_name IN VARCHAR2
Module_name names the code block about to occur. Action_name identifies the SQL action taking place.
Example
DBMS_APPLICATION_INFO.SET_MODULE(
Module_name => ‘add empl expense info’,
Action_name => ‘update empl_exp table’);
Sets or alters the current action on the database.
Parameter
Action_name IN VARCHAR2
Action_name identifies the SQL action taking place.
Example
DBMS_APPLICATION_INFO.SET_ACTION(
Action_name => ‘delete temp_exp info’)
Allows supply of additional information about the code executed.
Parameter
Client_info IN VARCHAR2
Client_info allows 64 bytes of additional data about the action.
Example
DBMS_APPLICATION_INFO.SET_CLIENT_INFO(
Client_info => ‘Forms 4.5 app’);
Reads active module and action information for the current session.
Parameters
Module_name OUT VARCHAR2
Action_name OUT VARCHAR2
Module_name names the code block about to occur. Action_name identifies the SQL action taking place.
Example
DBMS_APPLICATION_INFO.READ_MODULE(
Module_name OUT VARCHAR2,
Action_name OUT VARCHAR2);
Reads active client information for the current session.
Parameter
Client_info OUT VARCHAR2
Client_info allows 64 bytes of additional data about the action.
Example
DBMS_APPLICATION_INFO.READ_CLIENT_INFO(This chapter covers material related to tuning for differing application needs and tuning SQL statements portions for OCP Exam 4. These areas comprise a total of 10 percent of the exam. Some of the application types covered were online transaction processing applications, decision support systems, and client/server applications. Online transaction processing (OLTP) applications are database change intensive, and commonly have a large user base driving those database changes. The performance need on these systems is for immediate response on queries that update, insert, or delete data on the database. This performance gain is made by reducing any overhead on those types of transactions. Some examples of performance overhead for updates, inserts, and deletes are heavy usage on indexes on tables being modified, as well as any issue causing slow performance on rollback segments and redo log entries.
Decision support systems (DSS) pose several different needs on the database than OLTP applications. Decision support systems typically store large amounts of data that is available for a small user base via reports. These reports may be intensive in the amount of CPU time they take to execute. Fast access to volumes of data and well-tuned SQL queries as the underlying architecture for reports are the keys to success in DSS applications. Mechanisms that enhance query performance, such as clustering and indexes, are commonly employed to produce reports quickly. Since data changes will most likely be handled by batch processes at off-peak usage times, the performance overhead on change activities will probably not affect database performance or user satisfaction. Decision support systems often coexist with OLTP systems, as a reporting environment, archive repository, or both.
The other major type of application discussed is the client/server application. Often in client/server architectures, there are many client processes attempting to request data from only one server. As such, DBAs often use the multithreaded server options that are available with Oracle Server. Although two of the major components in the client/server architecture are identified by the name, there is an unseen element to the architecture that is as important to the success of the system as the client and the server. That component is the network that transports communication between client and server processes. However, it was explained that simply having a connection between two machines isn’t enough; the processes require a common "language" to use for interprocess communication. Oracle offers a solution to this issue with SQL*Net, a program designed to facilitate communication at the network layer between clients and Oracle Server. One of the main components of SQL*Net is the listener process. This process is designed to listen to the network connection for incoming data requests from client processes.
When such a request comes across the network, the listener process takes the request and routes it along in the database to a server process that will handle such tasks as obtaining data from Oracle datafiles on behalf of the user process. There are two ways that server processes run in Oracle. The first way is known as dedicated servers. In the dedicated server configuration, every user process that access Oracle has its own server process handling disk reads and other Oracle database processing. The relationship between Oracle Server processes and user processes is therefore one to one. However, it was discussed that this configuration requires extra memory on the database. Another option is for the DBA to use the multithreaded server (MTS) configuration. In this architecture, Oracle has a limited number of server processes that handle disk reads for multiple user processes, such that the relationship between server processes and user processes is many to one. In the MTS architecture, access to the server processes are brokered by another process called a dispatcher. User processes are connected to the dispatcher by way of the listener, and the dispatcher connects the user process to a shared server process.
This chapter covered material related to tuning SQL statements and applications in the Oracle database. Since SQL tuning often produces the most noticeable benefits for an application or query, it is generally the best place to start when tuning for performance gains. It also is the best place to start because of scope reasons. The DBA should determine that everything has been done to optimize the SQL statement before making sweeping changes to memory-, I/O- and contention-related areas that have the potential to break the database in other areas. Simply adding an index or ensuring that an index is being used properly can save problems later. Potential causes for inefficient SQL start with ineffective use of indexes associated with large tables, or lack of existence of those indexes for large tables. If there is no index present for queries against large tables to use, or if all data is selected from the table, or if a data operation (such as nvl, upper, etc.) is performed on an indexed column name in the where clause, then the database will perform a full table scan against the database in order to obtain the requested information. The performance of this query will be in direct proportion to the number of rows in the table.
Another cause for inefficient SQL is use of B-tree indexes of columns that contain few unique values. This low uniqueness, or cardinality, causes the index search to perform poorly. If a column with low cardinality must be indexed, the DBA should use a bitmap index rather than a B-tree index. More information about bitmap indexes appears in Chapter 4. Another cause of poor SQL statement performance involves views. If a view is utilized in a query, the best performance will occur if the underlying view selection statement is resolved as a component of the overall query, rather than the view resolving first and then the rest of the query being applied as a filter for the data returned. Finally, another cause for poor performance on a table that uses indexes consisting of multiple columns from the table, sometimes called concatenated or composite indexes, is the user’s use of those columns in the composite index in the wrong order on the SQL where clause. When using composite indexes to search for data, the query must list all columns in the where clause in the order specified by the composite index. If the user is unsure about column order in a composite index, the user can consult the ALL_IND_COLUMNS data dictionary view for that table’s indexes and the column order.
To better tune query performance, it helps to use the explain plan statement offered by Oracle in conjunction with the database’s SQL processing mechanism. Any user can use the explain plan statement in conjunction with the Oracle database provided they have a special table called PLAN_TABLE created in their user schema. This table can be created using the utlxplan.sql script found in the rdbms/admin directory off the Oracle software home directory. The results of the explain plan command are stored in the PLAN_TABLE. It is important to include a unique statement_id in the explain plan command syntax to facilitate retrieving the execution plan for the query.
The query listed in the text is used to retrieve the execution plan data from the PLAN_TABLE. The execution plan itself is read from the top of the plan downward, with results from inner operations feeding as input into the outer operations. It is important to watch out for full table scans, as these are the operations that are so detrimental to query performance. The database session can also be configured to generate execution plans using the set autotrace on command. There are advantages and drawbacks to using this approach. One advantage is that the user does not need to specify the explain plan syntax for every statement executed during the session; autotrace simply generates the plan and stores it. However, the execution plan for a query will not be available until the statement completes, making it difficult to proactively tune the query.
Other tool options for tuning SQL statements include the SQL Trace feature used in conjunction with TKPROF. SQL Trace tracks performance statistics for SQL statements, placing numbers next to the operations provided by explain plan. These statistics include the number of times the statement is parsed, executed, and how often records are fetched if the statement is a select; and CPU elapsed time and real elapsed time for the query, block reads, processed rows, and library cache misses. SQL Trace must be used in conjunction with proper settings for the TIMED_STATISTICS, MAX_DUMP_FILE_SIZE, and USER_DUMP_DEST parameters. The output of a SQL Trace dump file is difficult to read, giving rise to the need for TKPROF. This tool takes the trace file as input and produces a report of statistics named above for queries executed in the given session. Tracing can be specified on a session basis or for the entire instance. To enable tracing, alter the SQL_TRACE parameter either with the alter session statement (session-wide) or by specifying it in the init.ora file (instance_wide) and restarting the instance.
To track performance statistics in large, complex code environments, it helps to register code components with the database using the DBMS_APPLICATION_INFO package. This package provides functionality to name various modules of code and identify the actions they perform. Statistics for the execution of various actions within modules and the modules themselves can then be tracked using the dynamic performance views V$SESSION and V$SQLAREA.
| Online transaction processing (OLTP) applications are systems used generally by large user populations that have frequently updated data and constantly changing data volume. | |
| OLTP application performance is adversely affected by increases in processing overhead for data changes. This includes excessive usage of indexes and clusters. | |
| Decision support systems (DSS) are systems that store large volumes of data available for generating reports for users. | |
| DSS system performance is adversely affected by processing overhead associated with complex select statements. This may include a lack of proper indexing, clustering, data migration, or chaining. | |
| Client/server applications are distributed processing applications that have a client process usually residing on one machine and a server process usually residing on another. | |
| The additional processors used to handle client/server processing can speed the execution of processes on both ends. | |
| The unseen partner in client/server processing is a network connection. | |
| In addition to a physical connection, Oracle requires a common "language" to be spoken between client and server in order for interprocess communication to proceed. | |
| Oracle provides interprocess communication with the SQL*Net tool for clients and servers. | |
| SQL*Net provides a listener process that monitors the database connection for requests from clients. | |
| When a client request comes in, Oracle must route the user process to a server process in one of two ways, depending on whether the DBA uses dedicated servers for user processes or if the DBA uses the multithreaded server architecture (MTS). | |
| For dedicated servers, the SQL*Net listener connects each user process to its own private or "dedicated" server process. | |
| For a multithreaded server, the listener routes that request to a dispatcher, which will broker the client’s access to a limited number of shared server processes. | |
| Systems can be reconfigured on a temporary basis for application requirements. | |
| Multiple copies of initialization parameter files (init.ora) can manage this on-the-fly reconfiguration need. | |
| SQL tuning is the most important step in all database performance tuning, and should always happen as the first step in that tuning process. | |
| Possible causes for inefficient SQL stem mainly from improper or lack of index usage on data queries involving large tables or multiple table joins. | |
| The explain plan statement is used to assist the DBA or developer in determining the execution plan for a query. The execution plan is the process by which the SQL statement execution mechanism will obtain requested data from the database. | |
| The session can be set to generate execution plans for all executed queries by using the set autotrace on command. | |
| More information about the execution of a query can be obtained through using the SQL Trace and TKPROF utilities. | |
| SQL Trace can be enabled at the instance level by setting the SQL_TRACE parameter to TRUE and starting the instance. | |
| SQL Trace can be enabled at the session level with the alter session set sql_trace=true statement. | |
| SQL Trace tracks the following statistics for SQL statements: CPU time and real elapsed time; parse, execute, and fetch counts; library cache misses; data block reads; and number of rows processed. | |
| To use SQL Trace properly, several initialization parameters must be set in the init.ora file: |
| TKPROF takes as input the trace file produced by SQL Trace and produces a readable report summarizing trace information for the query. | |
| DBMS_APPLICATION_INFO is used to register various blocks of code with the database for performance tuning purposes. | |
| DBMS_APPLICATION_INFO.SET_MODULE sets the module and action name for the current code block. | |
| DBMS_APPLICATION_INFO.SET_ACTION sets the action name for the current code block. | |
| DBMS_APPLICATION_INFO.SET_CLIENT_INFO sets additional client information about the code block. | |
| DBMS_APPLICATION_INFO.READ_MODULE obtains module and action names for current active code block. | |
| DBMS_APPLICATION_INFO.READ_CLIENT_INFO obtains additional client information for current active code block if there is any available. |