Chapter 16 *
In this chapter, you will understand and demonstrate knowledge in the following areas:
| Tuning overview | |
| Diagnosing problems |
This chapter is an introduction to tuning. OCP Exam 4 covers many aspects of tuning the Oracle database, and this chapter will set the stage both for your high-level understanding of the Oracle tuning process and for the material to come in the rest of Unit IV. This chapter will begin your exploration of tuning the Oracle database and the applications that use the Oracle database. Both the methodology for tuning and the tools for executing the tuning process will be discussed. The material in this chapter comprises about 15 percent of test questions asked on OCP Exam 4.
In this section, you will cover the following topics related to tuning overview:
| Discussing the nature of tuning | |
| Outlining a tuning methodology | |
| Identifying diagnostic tools |
The Oracle database server is designed to meet the needs of different applications, including those applications that have large user populations who execute many transactions to put data into the database and modify existing data in that database. Oracle also serves the needs of organizations that require large amounts of data to be available in a data warehouse, or an application that contains vast amounts of data available primarily for read access and reporting. In order to meet the needs of these different types of applications, Oracle offers a great deal of flexibility in the way it can be configured. The ongoing tuning process is used by DBAs to run the Oracle Server in such a way as to maximize query performance, storage management, and resource usage according to the needs of the application. This section will begin the discussion of the nature of tuning, allowing you to make the most of Oracle.
Tuning is done for many reasons on an Oracle database. Users often want their online applications to run faster. The developers may want batch processes to run faster as well. Management in the organization often recognizes the need for faster applications and batch processing on their Oracle databases. One solution to the problem of performance is to invest in the latest hardware containing faster processors, more memory, and more disk space. To be sure, this is often an effective solution, and methods for maximizing the hardware on the machine hosting the Oracle database will be presented in this unit in order to improve your understanding in this area for OCP. However, the latest and greatest machines are also the most expensive. Organizations generally need to plan their hardware purchases some time in advance also, which means that acute problems with performance are not usually resolved with the hardware purchase approach. Instead, the DBA must determine other ways to improve performance.
In order to meet the needs of an ongoing application that sometimes encounters performance issues, the DBA must know how to resolve those issues. Many problems with performance on an Oracle database can be resolved with three methods, the first being the purchase of new hardware described. The second and third are effective database configuration and effective application design. It should be understood by all people who use Oracle databases that by far the greatest problems with performance are caused by the application—not the Oracle database. Poorly written SQL statements, the use of multiple SQL statements where one would suffice, and other problems within an application are the source of most performance issues. The DBA should always place the responsibility of the first step in any performance situation onto the application developers to see if they can rewrite the code of the application to utilize the database more effectively.
Only after all possibility for resolving the performance issue by redeveloping the application is exhausted should the DBA attempt any changes to the configuration of the Oracle database. This consideration is designed to prevent the impromptu reconfiguration of the Oracle database to satisfy a performance need in one area, only to create a performance problem in another area. Any change to the configuration of the Oracle database should be considered carefully. The DBA should weigh the trade-offs she might need to make in order to improve performance in one area. For example, when changing the memory management configuration for the Oracle database without buying and installing more memory, the DBA must be careful not to size any part of the Oracle SGA out of real memory. Also, if the Oracle SGA takes up more existing memory, other applications that might be running on the same machine may suffer. The DBA may need to work in conjunction with the systems administrator of the machine to decide how to make the trade-off.
Before the DBA begins tuning Oracle, he or she should have an appropriate tuning methodology outlined. This methodology should correspond directly to the goals the DBA is attempting to reach regarding the use of each application and other needs identified by the organization. Some common goals include allowing an application to accept high-volume transaction processing at certain times of the day, returning frequently requested data quickly, or allowing users to create and execute ad hoc reports without adversely affecting online transaction processing. These goals, as well as the many other performance goals set before DBAs, fall into three general categories:
| To improve performance of specific SQL statements running against the Oracle database | |
| To improve performance of specific applications running within the Oracle database | |
| To improve overall performance for all users and applications within the Oracle database |
Oracle has its own four-step process that every DBA should use for performance tuning. In general, it is best to start with step 1 in every situation, in order to avoid creating problems as you attempt to solve them. Also, notice that progressing from step to step directly translates to an increase in the scope and impact of the proposed change. The steps of the process are to start by tuning the performance of applications using the Oracle database, then to tune the memory usage of the Oracle database. If there are still problems, the DBA can tune the disk I/O and utilization of the Oracle database, and finally, the DBA should tune locks and other contention issues. A full presentation of each area follows.
The importance of tuning the application SQL statements and PL/SQL code cannot be overstated. Most often, poorly written queries are the source of poor performance. DBAs should play an active part in encouraging developers to tune the application queries before engaging in other steps of the tuning process. Some of the tools available for developers are described shortly, including SQL Trace and the explain plan command. More detailed information about application tuning appears in Chapter 17.
After application tuning, appropriate configuration and tuning of memory structures can have a sizeable impact on application and database performance. Oracle should have enough space allocation for the SQL and PL/SQL areas, data dictionary cache, and buffer cache to yield performance improvement. That improvement will be in the following areas:
| Retrieving database data already in memory | |
| Reduction in SQL parsing | |
| Elimination of operating system paging and swapping (the copying of data in memory onto disk that has detrimental impact to application performance) |
More detailed information about memory tuning appears in Chapter 18.
Oracle Server is designed in such a way as to prevent I/O from adversely impacting application performance. Features such as the server, DBWR, LGWR, CKPT, and SMON background processes each contributing to the effective use and management of disk usage, and are designed to reduce an application’s dependency on fast writes to disk for improvements in performance. However, there are situations where disk usage can have an adverse impact on an application. Tuning disk usage generally means distributing I/O over several disks to avoid contention, storing data in blocks to facilitate data retrieval, and creating properly sized extents for data storage. More information about disk I/O tuning appears in Chapter 19.
As in the case of tuning disk I/O, Oracle Server is designed in such a way as to minimize resource contention. For example, Oracle can detect and eliminate deadlocks. However, there are occasions where many users contend for resources such as rollback segments, dispatchers, or other processes in the multithreaded architecture of Oracle Server, or redo log buffer latches. Though infrequent, these situations are extremely detrimental to the performance of the application. More information about resource contention tuning appears in Chapter 20.
As stated, the steps listed above should be used in the order listed in the event of a tuning emergency. However, the proactive DBA should attempt to tune the database even when everything appears to be running well. The reason proactive tuning is necessary is to reduce the amount of time the DBA spends in production support situations. Proactive tuning also increases the DBA’s knowledge of his or her applications, thereby reducing the effort required when the inevitable production emergency arises.
The most important step in solving performance issues is discovering them. While the easiest way to discover performance issues is to wait for developers or users to call and complain, this method is not very customer-oriented, and has proved very detrimental to the reputation of many information technology departments. This approach of taking performance problems on the chin is a reality that is not required, given the availability of tools from Oracle to help monitor and eliminate performance issues. Here are some utilities designed to assist in tuning the Oracle instance.
This creates tables to store dynamic performance statistics for the Oracle database. Execution of this script also begins the statistics collection process. In order to make statistics collection more effective, the DBA should not run UTLBSTAT until after the database has been running for several hours or days. This utility uses underlying V$ performance views (see V$ views below) to find information about the performance of the Oracle database, and the accumulation of useful data in these views may take some time.
This ends collection of statistics for the instance. An output file called report.txt containing a report of the statistics generated by the UTLBSTAT utility. To maximize the effectiveness of these two utilities, it is important that UTLBSTAT be allowed to run for a long time before ending statistics collection, under a variety of circumstances. These circumstances include batch processing, online transaction processing, backups, and periods of inactivity. This wide variety of database activity will give the DBA a more complete idea about the level of usage the database experiences under normal circumstances.
Oracle’s Server Manager tool contains several menu options for monitoring the database and diagnosing problems. This menu is usable when Server Manager is run in GUI mode. Since most Oracle DBAs who use UNIX as the operating system to support Oracle run Server Manager in line mode, this option may not be as familiar to them as other options that take advantage of line mode operation.
This command enables the DBA or developer to determine the execution path of a block of SQL code. The execution plan is generated by the SQL statement processing mechanism. In Oracle7, this command can be executed by entering explain plan set statement_id = ‘name’ into plan_table for SQL_statement at the SQL*Plus prompt. The execution plan shows the step-by-step operations that Oracle will undertake in order to obtain data from the tables comprising the Oracle database. This option is provided mainly for developers and users who write SQL statements and run them against the database to avoid running inefficient SQL. The output of this information is placed into a special table created by running the utlxplan.sql script found in the rdbms/admin subdirectory under the Oracle software home directory. This table is called PLAN_TABLE. An example of an operation that obtains data from the database inefficiently is a full table scan. The execution information can be retrieved from PLAN_TABLE using a special query provided by Oracle—this query will display the information in PLAN_TABLE in a certain way that requires interpretation of the innermost indented operation outward, and then from top to bottom. More information about using explain plan will be presented in Chapter 17.
This set of utilities contains products that will help the DBA identify performance issues. This package is available mainly to organizations using Oracle on servers running Windows operating systems. This option may not be as well known to DBAs in organizations using Oracle in UNIX environments, because many DBAs use Oracle database management tools in line mode.
This tool extends the functionality provided by explain plan by giving statistical information about the SQL statements executed in a session that has tracing enabled. This additional statistical information is provided in a dump file. This utility is run for an entire session using the alter session set sql_trace = true statement. Tracing a session is especially useful for analyzing the full operation of an application or batch process containing multiple transactions, where it is unclear which part of the application or batch process is encountering performance issues.
The dump file provided by SQL Trace is often hard to read. TKPROF takes the output in a trace file and turns it into a more understandable report. The relationship between SQL TRACE and TKPROF is similar to the relationship between IMPORT and EXPORT, as TKPROF only operates or accepts as input the output file produced by SQL TRACE. The contents of the report produced by TKPROF will be discussed.
These are views against several memory structures created by the Oracle SGA at instance startup. These views contain database performance information that is useful to both DBAs and Oracle to determine the current status of the database. The operation of performance tuning tools, such as those in the Oracle Enterprise Manager or Server Manager utilities running in GUI mode as well as utilities available from third-party vendors, use the underlying V$ performance views as their basis for information.
In this section, you will cover the following topics related to diagnosing problems:
| Running UTLBSTAT and UTLESTAT | |
| Describing contents of report.txt | |
| Understanding latch contention | |
| Checking for events causing waits |
In order to solve performance issues, the DBA must be able to pinpoint their source. Often, the performance issue may occur in conjunction with another event. For example, a DBA may get a performance-related support call from users of an online transaction processing system who experience noticeably slower performance at 3 p.m. The DBA may think that there is a performance issue with the application until she discovers that there are a series of ad hoc reports that are scheduled to deploy at around that time. Unfortunately, performance issues sometimes happen infrequently or at irregular intervals. The task of identifying the problem can involve a detailed review of what was happening in the database at the time the performance issue arose. A real-time database monitoring tool that uses V$ dynamic performance views as the basis of reflecting database usage can tell the DBA when the performance issue happened. However, the tool will only be able to tell when the problem occurred in real time. The DBA or someone else must actually be observing the performance monitor when it reflects the change in performance. This can be time consuming and prone to human error such as momentary distraction. The answer to this problem is to maintain a history of performance statistics. This section will describe how the DBA can do this.
These two utilities, mentioned earlier, provide the functionality required to maintain a history of performance information. To review, UTLBSTAT creates several statistics tables for storing the dynamic performance information. It also begins the collection of dynamic performance statistics. Typically, the script is found in the rdbms/admin directory under the Oracle software home directory, and is executed from within Server Manager. Though it is not necessary to execute the connect internal command before executing this query, the DBA should connect to the database as a user with connect internal privileges prior to running the query. The database overhead used for collecting these statistics, though not sizeable (depending on the platform running Oracle), can have an impact on the system as high as 10 percent. UTLBSTAT creates tables to store data from several V$ performance views including:
| V$WAITSTAT V$ROLLSTAT V$SESSION |
V$SYSTEM_EVENT V$ROWCACHE V$LIBRARYCACHE |
V$SYSSTAT V$LATCH V$SESSION_EVENT |
UTLESTAT ends the collection of performance statistics from the views named above. Typically, the script is found in the same location as UTLBSTAT, in the rdbms/admin directory under the Oracle software home directory, and it is executed from Server Manager. Though it is not necessary to execute the connect internal command before executing this query, the DBA should connect to the database as a user with connect internal privileges prior to running the query. This utility will gather all statistics collected and use them to generate an output file called report.txt. After generating report.txt, the utility will remove the statistics tables it used to store the performance history of the database. The contents of report.txt will be discussed shortly.
Care should be taken not to shut down the database while UTLBSTAT is running. If this should happen, there could be problems with interpreting the data, and since the database must be running for several hours in order for the V$ views that UTLBSTAT depends on to contain useful data, all work done by UTLBSTAT will be useless. The best thing to do in this situation is to run UTLESTAT as soon as possible to clear out all data from the prior run, and wait until the database has been up long enough to attempt a second execution.
There are several important areas of information provided by the report.txt file. The report.txt file provides a great deal of useful information in the following areas. First, it provides statistics for file I/O by tablespace and datafile. This information is useful in distributing files across many disks to reduce I/O contention. SGA, shared area, dictionary area, table/procedure, trigger, pipe, and other cache statistics. report.txt is also used to determine if there is contention for any of several different resources. This report also gives latch wait statistics for the database instance and shows if there is contention for resources using latches. Statistics are also given for how often user processes wait for rollback segments, which can be used to determine if more rollback segments should be added. Average length of a dirty buffer write queue is also shown, which the DBA can use to determine if DBWR is having difficulty writing blocks to the database. Finally, the report.txt file contains a listing of all initialization parameters for the database and the start and stop time for statistics collection. An example of report.txt, slightly modified for readability, is listed here:
SVRMGR> Rem Select Library cache statistics. The pin hit rate should be high.
SVRMGR> select namespace library, gets,
2> round(decode(gethits,0,1,gethits)/decode(gets,0,1,gets),3)
3> gethitratio, pins,
4> round(decode(pinhits,0,1,pinhits)/decode(pins,0,1,pins),3)
5> pinhitratio, reloads, invalidations from stats$lib;
LIBRARY GETS GETHITRATI
PINS PINHITRATI RELOADS INVALIDATI
------------ ---------- ---------- ---------- ---------- ---------- ----------
BODY 2
1
2
1
0
0
CLUSTER 0
1
0
1
0
0
INDEX 0
1
0
1
0
0
OBJECT 0
1
0
1
0
0
PIPE 0
1
0
1
0
0
SQL AREA 5098 .605
18740 .772
185 0
TABLE/PROCED 7762 .989
15138 .982
186 0
TRIGGER 0
1
0
1
0
0
SVRMGR> Rem The total is the total value of the statistic between the time
SVRMGR> Rem bstat was run and the time estat was run. Note that the estat
SVRMGR> Rem script logs on as "internal" so the per_logon statistics will
SVRMGR> Rem always be based on at least one logon.
SVRMGR> select n1.name "Statistic", n1.change "Total",
2> round(n1.change/trans.change,2) "Per Transaction",
3> round(n1.change/logs.change,2) "Per Logon"
4> from stats$stats n1, stats$stats trans, stats$stats logs
5> where trans.name='user commits'
6> and logs.name='logons' and n1.change != 0
7> order by n1.name;
0 rows selected.
SVRMGR> Rem Average length of the dirty buffer write queue. If this is larger than
SVRMGR> Rem the value of the db_block_write_batch init.ora parameter, consider
SVRMGR> Rem increasing the value of db_block_write_batch and check for disks that
SVRMGR> Rem are doing many more IOs than other disks.
SVRMGR> select queue.change/writes.change "Average Write Queue Length"
2> from stats$stats queue, stats$stats writes
3> where queue.name = 'summed write queue length'
4> and writes.name = 'write requests';
0 rows selected.
SVRMGR> Rem I/O should be spread evenly across drives. A big difference between
SVRMGR> Rem phys_reads and phys_blks_rd implies table scans are going on.
SVRMGR> select * from stats$files order by table_space, file_name;
An important facet of performance tuning lies in knowing how to set initialization parameters. Knowing the values of these parameters often becomes an issue when trying to identify and solve problems. Although the DBA can find the values of initialization parameters by reading the init.ora file used to start the database instance, this method of determining initialization parameters for the instance isn’t the most accurate. Instead, the DBA should use the show parameter command available in Server Manager. Alternately, the following select statement using the V$PARAMETER view will show the initialization parameters for the instance:
SELECT name, value
FROM v$parameter;
The next four chapters on performance tuning that comprise this unit utilize information from dynamic performance views on the Oracle database. These views are the cornerstone of statistics collection for the Oracle database and are used by many performance monitoring tools such as Server Manager. Access to these views, whose names generally start with either V$ or X$, is as follows: V$ views can be accessed either by the DBA logging in as the owner (SYS) or as a user with the select any table privilege granted to it. The X$ views can be accessed only by user SYS.
To monitor and control access to most Oracle system resources, there are mechanisms called latches that limit the amount of time and space any single process can command the resource at any given time. Monitoring the latch that controls access to the resource is the method used to determine if there is a problem with contention for the resource. A latch is simply an object in the Oracle database that a process must obtain access to in order to conduct a certain type of activity.
As with any other monitoring exercise, there are V$ dynamic performance views provided by Oracle to assist in the task of observing the performance of the resource. In this case, there are two views that accomplish the task. They are V$LATCHHOLDER and V$LATCH. V$LATCH gives statistical information about each latch in the system, like the number of times a process waited for and obtained the latch. There are approximately 40 different latches in Oracle (possibly more, depending on the options installed and used). V$LATCHHOLDER tells the DBA which latches are being held at the moment, and identifies the processes that are holding those latches. Unfortunately, this information is stored in V$LATCHHOLDER and V$LATCH according to latch number, while the actual names of the latches corresponding to latch number are stored only in V$LATCHNAME.
The following code block shows the contents of V$LATCHNAME, a dynamic performance view that contains the names of all latches in the database, along with their corresponding latch numbers. The name of the latch is stored in this view only, and can be joined with data stored in the other V$ views on latches by latch number. This listing should give an idea about the types of latches that are available in Oracle:
SELECT * FROM v$latchname;
LATCH# NAME
--------- -------------------------
0 latch wait list
1 process allocation
2 session allocation
3 session switching
4 session idle bit
5 messages
6 enqueues
7 trace latch
8 cache buffers chains
9 cache buffers lru chain
10 cache buffer handle
11 multiblock read objects
12 cache protection latch
13 system commit number
14 archive control
15 redo allocation
16 redo copy
17 dml lock allocation
18 transaction allocation
19 undo global data
20 sequence cache
21 row cache objects
22 cost function
23 user lock
24 global transaction mapping table
25 global transaction
26 shared pool
27 library cache
29 virtual circuit buffers
30 virtual circuit queues
31 virtual circuits
32 NLS data objects
33 query server process
34 query server freelists
35 error message lists
36 process queue
37 process queue reference
38 parallel query stats
The latches in the list above manage many different resources on the Oracle database. Those resources, along with some of the latches from above that handle management of that resource, are listed below:
| Buffer cache Cache buffers chain, cache buffers LRU chain, cache buffer handle, multiblock read objects, cache protection latch | |
| Redo log Redo allocation, redo copy | |
| Shared pool Shared pool, library cache, row cache objects | |
| Archiving redo Archive control | |
| User processes and sessions Process allocation, session allocation, session switching, session idle bit |
To obtain any of the resources listed in the previous code block, the process must first acquire the latch. Processes that request latches to perform activities using Oracle resources do not always obtain the latch the first time they request them. There are two behaviors that processes will undertake when they need to use a latch and find that the latch is not available for their use. One is that the process will wait for the latch to become available for the process’s use. The other is that the process will not wait for the latch to become available, but instead will move on within its own process.
V$LATCHHOLDER handles identifying the processes running on the database that are holding latches. These particular processes may be causing waits on the system. A query against V$LATCHHOLDER will allow the user to identify the process IDs for all processes holding the latch. Since the period of time that any process will hold a latch is very brief, the task of identifying waits on the system, as discussed earlier, can be accomplished by continuously monitoring V$LATCHHOLDER to see which users are holding latches excessively. If there are processes that are holding latches for a long while, that process will appear again and again. Performance for all processes that are waiting for the latch to be free will wait as well.
Unfortunately, each of these views uses a rather cryptic method of identifying which latch is currently being held. A listing of the columns in each table and their meaning follows this discussion. One solution to the problem of cryptic latch numbers used to identify the latch being used is to use V$LATCHNAME. This view maps the latch number to a more readable name that the DBA can associate with a latch. A sample query is given below that will list out the latches that are currently being held by a process, as well as the name of the latch being held:
SELECT h.pid, n.name
FROM v$latchholder h, v$latchname n, v$latch l
WHERE h.laddr = l.addr
AND l.latch# = n.latch#;
H.PID N.NAME
--------- -----------------------
34 redo allocation
12 library cache
…
Note that this query performs a join through the V$LATCH performance view. This is because the link from the latch name in V$LATCHNAME and the latch address that is given in V$LATCHHOLDER can only be made through the latch number, which is present in V$LATCH. More information about the contents of each performance view designed to store latch statistics can be found in Figure 16-1.
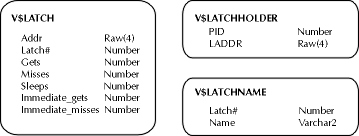
Figure 1: V$ performance views storing latch statistics
The V$LATCH can be used as a link between latch views to obtain latch numbers corresponding with latch addresses. Sometimes this link is useful for tying in another important piece of information related to latches. This important piece of information is the wait ratio for the latch—the number of times processes waited for latch access in proportion to the overall number of times processes requested the latch. The wait ratio for latches helps to determine if there is a more serious problem associated with latch waits on the system. The following code block shows how to obtain the latch wait ratio using appropriate views:
SELECT h.pid, n.name, (l.misses/l.gets)*100 wait_ratio
FROM v$latchholder h, v$latchname n, v$latch l
WHERE h.laddr = l.addr
AND l.latch# = n.latch#;
H.PID N.NAME
WAIT_RATIO
------ ----------------- -------------
34 redo allocation 1.0304495
12 library cache 0.0403949
…
This new feature of the latch holder query adds in the ratio of times a process did not obtain the latch vs. the total number of times the latch was requested. Consistent monitoring of these V$ performance views yields the following: If the same process shows up time and time again as holding the latch named, and the wait ratio is high for that latch, then there could be a problem with an event causing a wait on the system.
To find out more about the events or processes that are suffering as a result of an event causing waits, the V$PROCESS view can be put into play. V$PROCESS has a special column associated with it that identifies the address of a latch for which that process is currently experiencing a wait. This column is usually NULL, but if there is a value present for it then there is a wait happening. Associating the latch name and wait ratio can be accomplished with an extension of the query already identified. The following code block demonstrates this:
SELECT p.pid, n.name, (l.misses/l.gets)*100 wait_ratio
FROM v$process p, v$latchname n, v$latch l
WHERE p.latchwait is not null
AND p.latchwait = l.addr
AND l.latch# = n.latch#;
P.PID N.NAME
WAIT_RATIO
------- ---------------- -------------
34 redo allocation 1.0304495
The execution of this query produces the process identifier for a process experiencing the wait, the name of the latch that is currently held by another process, and the wait ratio for that latch overall. The functionality that these V$ views give can be better managed with use of the MONITOR LATCH menu item present in Oracle’s utilities for database administration, Server Manager. This feature is not available in Oracle8.
There are two types of requests for latches. The distinction between each type of request is based on whether the requestor will continue to run if the latch is not available to that process. Some processes are willing to wait for the latch, while others are not. If a process will wait for the latch, the following series of events will take place:
Unlike those processes that are willing to wait until a latch becomes available, there are other processes that will not wait until the latch is free to continue. These processes require the latch immediately or they move on. The V$LATCH dynamic performance view captures statistics on both types of latch requests. The following chart depicts the columns of V$LATCH, the explanation of the column, and the corresponding type of request it reflects:
GETS |
Willing to wait | The number of latch requests that resulted in actually obtaining the latch |
| MISSES | Willing to wait | The number of latch requests that did not result in actually obtaining a latch |
| SLEEPS | Willing to wait | The number of times a process waited for the latch, then requested to obtain it again |
| IMMEDIATE_GETS | Immediate | The number of latch requests that resulted in immediately obtaining the latch |
| IMMEDIATE_MISSES | Immediate | The number of latch requests that were unsuccessful in obtaining the latch |
Consider a couple of examples of obtaining latches to understand the process Oracle uses to maintain latch statistics better. Assume a user process puts forth an immediate request to obtain a latch. The latch is available, so the request is granted and the user process obtains the latch. The IMMEDIATE_GETS column on V$LATCH corresponding to the row entry for that latch will be incremented by one . Using that same example, let’s say now that the latch was busy. Instead, Oracle will now update the IMMEDIATE_MISSES column on the corresponding row entry in V$LATCH for that latch. This example illustrates that the statistics compilation process for immediate requests for latches is straightforward.
Now, let us consider the more involved process of compiling statistics for willing to wait requests. A user process makes a willing to wait request for a latch. The latch is available, so the process obtains the latch. The GETS column from V$LATCH is incremented by one . Using the same example, the user process requests a latch, but this time the latch is unavailable. The user process has to wait. So, the user process goes to sleep. The MISSES column is incremented and the SLEEP column is incremented, and the process doesn’t get its latch. After a short period, the process wakes up and asks for the process again. The latch is now available, so the GETS column in V$LATCH for that latch is incremented as well. One can see that the numbers will add up on those columns corresponding to willing to wait requests if latches become tough to obtain.
The next important aspect of latches to cover is calculation of the wait ratio for a latch. The DBA can obtain the wait ratio for a given latch by executing the following query against Oracle:
SELECT n.name,
(l.misses/l.gets)*100 w2wait_ratio,
(l.immediate_misses/l.immediate_gets)*100 immed_ratio,
FROM v$latch l, v$latchname n
WHERE n.name in (‘redo copy’,‘redo allocation’)
AND n.latch# = l.latch#;
N.NAME W2WAIT_RATIO
IMMED_RATIO
----------------- -------------- --------------
redo allocation 1.0304495 2.9405949
Any of the names for latches listed in the code block displaying the contents of V$LATCHNAME can be used as part of the in clause in this statement. However, as we will learn in this unit, the latches that manage access to the redo log resources are particularly important because there are few of them, and every process that makes changes to data needs access to them. If either the wait ratio on willing to wait or the immediate latch requests for the latch named by the DBA in the query are greater than 1, then there is a problem with latch contention in the database.
In this chapter we have covered the fundamentals in this advanced area of performance tuning as evaluated by OCP Exam 4. These areas are the tuning overview and problem diagnostics. These two topics comprise 15 percent of OCP Exam 4 content. The beginning of this chapter focused on the nature of database tuning. The text outlined three goals for any DBA approaching the task of performance tuning. They are improving performance of certain queries running against the Oracle database, improving performance of certain applications running against Oracle, and improving Oracle’s overall handling of database user and application load. The text also covered why DBAs should always begin the tuning process by trying to achieve the first goal, that of tuning the SQL queries first. Only when that approach does not work should higher levels of performance tuning be sought.
The following steps were also presented as the outline of an appropriate tuning methodology for DBAs. Step 1 is to tune the applications. Step 2 is to tune memory structures. Step 3 is to tune disk I/O usage. Step 4 is to detect and eliminate I/O contention. These steps are the Oracle-recommended outline of tasks to execute in all tuning situations. The DBA is encouraged to use these steps when he or she isn’t sure of the cause for poor performance on the Oracle database. Following the logical hierarchy or scope of each change is the important feature to remember from this section. OCP Exam 4 will focus some attention on taking the most appropriate tuning measure without making sweeping changes to the database in order to avoid causing more problems than were solved.
The tools used to diagnose and solve performance issues were also discussed in this chapter. One important method the DBA will use to determine performance issues on an Oracle database involves the use of the statistics gathering utilities UTLBSTAT and UTLESTAT. The location of these utilities on the Oracle distribution is usually the rdbms/admin subdirectory under the Oracle software home directory. UTLBSTAT begins statistics collection for observing database performance over an extended period of time. When executed, this process will create the necessary data dictionary tables to store performance data history, and then it will begin collecting those historical performance statistics. UTLESTAT is the statistics collection end utility. On execution, it takes the statistics gathered in the tables UTLBSTAT created and creates a report based on that data. The report name is report.txt, and it can be found in the current directory. The report.txt file consists of several parts, which are described and illustrated in the chapter body.
These tools are dependent on performance data collected by the V$ views in the Oracle data dictionary. That data is valid only for the current Oracle instance; the data is not carried over when an instance is shut down. Since it takes some time for those statistics gathered to have any meaning, it is wise to hold off running UTLBSTAT and UTLESTAT until the database instance has been available for several hours.
Also covered by this chapter was the topic of latch contention in the Oracle instance redo log. Similar to locks, latches exist to limit access to certain types of resources. There are at least 40 different latches in the Oracle database. Two important latches in the database manage the redo log resource. They are the redo copy and redo allocation latch. Latches can be monitored by using the dynamic performance views V$LATCH, V$LATCHHOLDER, and V$LATCHNAME. The statistics to monitor about latches are the number of times a process has to wait for Oracle to fulfill a request it makes to obtain a latch vs. the times a process requests a latch and obtains it. A process will generally do one of two things if it is denied access to a latch. Its request is either immediate or willing to wait. These two types of process requests affect the collection of V$LATCH statistics in the following way. V$LATCH tracks the number of GETS, MISSES, and SLEEPS for processes willing to wait on a request for a latch. A process will sleep if its latch request is denied and the process wants to wait for it to become available. V$LATCH also calculates the number of IMMEDIATE_GETS and IMMEDIATE_MISSES for those processes requesting latches that want the latch immediately or the process moves on. Latch wait time for processes willing to wait is based on the number of MISSES divided by GETS, times 100, or (MISSES/GETS)*100. Latch wait time for processes requiring immediate access to latches or the process will move on is based on the number of IMMEDIATE_MISSES divided by IMMEDIATE_GETS, times 100, or (IMMEDIATE_MISSES/IMMEDIATE_GETS) *100.
Looking for events causing waits was also covered. Events that are causing waits appear in both the V$LOCK dynamic performance view and the V$LATCHHOLDER view. Both these views list information about the processes that are currently holding the keys to access certain resources on the Oracle database. If there are high wait ratios associated with a process holding a latch or lock, as reflected by statistics gathered from V$LATCH or by the presence of a process ID in the V$LOCK view, then there could be a contention issue on the database.
| Three goals of performance tuning are improve performance of particular SQL queries, improve performance of applications, and improve performance of the entire database. | |
| The four steps of performance tuning are as follows: |
| Performance tuning steps listed above should be executed in the order given to avoid making sweeping database changes that cause things to break in unanticipated ways. | |
| The UTLBSTAT and UTLESTAT utilities are frequently used by DBAs to identify performance issues on the Oracle database. | |
| UTLBSTAT is the begin statistics collection utility. Executing this file creates special tables for database performance statistics collection and begins the collection process. | |
| UTLESTAT is the end statistics collection utility. It concludes the statistics collection activity started by UTLBSTAT and produces a report of database activity called report.txt. | |
| The report.txt file consists of the following components: | |
| Statistics for file I/O by tablespace and datafile. This information is useful in distributing files across many disks to reduce I/O contention. | |
| SGA, shared pool, table/procedure, trigger, pipe, and other cache statistics. Used to determine if there is contention for any of the listed resources. | |
| Latch wait statistics for the database instance. Used to determine if there is contention for resources using latches. | |
| Statistics for how often user processes wait for rollback segments, which is used to determine if more rollback segments should be added. | |
| Average length of dirty buffer write queue, which is used to determine if DBWR is having difficulty writing blocks to the database. | |
| Initialization parameters for the database, including defaults. | |
| Start time and stop time for statistics collection. | |
| Latches are similar to locks in that they are used to control access to a database resource. Latch contention is when two (or more) processes are attempting to acquire a latch at the same time. | |
| There are approximately 40 different types of latches in the Oracle database. | |
| Latches are used in conjunction with restricting write access to online redo logs, among other things. The two types of latches for this purpose are redo allocation latches and redo copy latches. | |
| Some processes make requests for latches that are willing to wait for the latch to be free. Other processes move on if they cannot obtain immediate access to a latch. | |
| V$LATCH is used for latch performance monitoring. It contains all GETS, MISSES, SLEEPS, IMMEDIATE_GETS, and IMMEDIATE_MISSES statistics required for calculating wait ratios. | |
| V$LATCHNAME holds a readable identification name corresponding to each latch number listed in V$LATCH. | |
| V$LATCHHOLDER lists the processes that are currently holding latches on the system. This is useful for finding the processes that may be causing waits on the system. | |
| V$LOCK lists the processes that are holding object locks on the system. This is useful to find processes that may be causing waits on the system. | |
| Latch performance is measured by the wait ratio. For processes willing to wait, the wait ratio is calculated as MISSES / GETS * 100. | |
| For processes wanting immediate latch access, the wait ratio is calculated as IMMEDIATE_MISSES / IMMEDIATE_GETS * 100. |