In this chapter, you will understand and demonstrate knowledge in the following areas:
| Minimizing downtime | |
| Troubleshooting | |
| The standby database |
The final areas of Oracle backup and recovery that the DBA should understand are database troubleshooting, minimizing database downtime, and the use of the standby database feature of Oracle. The first advanced topic of backup and recovery—minimizing downtime—will consist of several discussions. These discussions include system startup after database failure. This section also includes discussion of starting up the database in situations where parts of the database are damaged. A continuation of the discussion started on the topic of leaving the database open during tablespace recovery will be included as well. Finally, related to minimizing downtime, the parallel recovery option will be discussed. Troubleshooting will also be presented. The usage of the alert log and process trace files is discussed, as is a further discussion of the dynamic performance views. The detection and resolution of corrupt data in online redo logs is also presented in this chapter. Finally, for this discussion, the use of DBVERIFY will be presented. Finally, the usage and functions of the standby database feature in Oracle will be presented. These three topics comprise the advanced topics of Oracle backup and recovery covered by the OCP Exam. These three topics comprise 12 percent of OCP Exam 3.
In this section, you will cover the following topics related to minimizing downtime:
| Database startup after system failure | |
| Starting the database when missing database files | |
| Initiating partial recovery on an open database | |
| Parallel recovery |
This section will cover the topic of minimizing downtime during database recovery. The first advanced topic of backup and recovery, minimizing downtime will consist of several discussions. These discussions include system startup after database failure. This section also includes discussion of starting up the database in situations where parts of the database are damaged. A continuation of the discussion started on the topic of leaving the database open during tablespace recovery will be included as well. Finally, related to minimizing downtime, the parallel recovery option will be discussed.
When a database crashes, several things go wrong at the same time. A hardware failure prevents Oracle from using one of the disks on the hardware hosting Oracle. Alerts are written in their proper places, and the DBA realizes there is a problem. As mentioned, it is important to get the database back into the state of being open and available for use. However, a parallel goal that the DBA should have for recovering the database is to recover the database as quickly as possible.
One feature of the Oracle database allows it to start quickly after database failure occurs. This feature makes the database open after the failure in a manner that quickly gets the database recovery going so that the DBA can get off to a good start performance-wise with the database recovery. This feature is called fast transaction rollback.
To understand the process of database recovery and how fast transaction rollback works, consider the following presentation. The architecture of the Oracle database is such that recovery occurs in two processes. Recall that issuing the database shutdown command from Server Manager with the abort option will force database media recovery after the database restarts. The first process in that media recovery is called rolling forward. In Figure 15-1, there is a demonstration of the activity Oracle undergoes during the rolling forward process. Consider the act of complete recovery with archiving, as presented in Chapter 14. Oracle will roll forward all the database transactions that have been exchanged with users. This process will happen until all redo entries have been applied that were present in the online redo log after database startup.
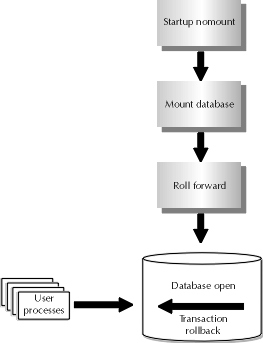
Figure 1: Database startup after media failure
After that point, the second process will kick in—the database will engage in the process of rollback of all transactions that were not committed at the time the shutdown abort was issued. This process is also demonstrated at a high level in Figure 15-1. Any transaction that was still being engaged by a user process when the database was shut down is considered uncommitted, while those transactions that had a commit statement issued to end them are considered committed. The second part of the recovery is designed to eliminate the in-progress information for uncommitted transactions from the data dictionary required for transaction rollback.
The fast transaction rollback feature of the Oracle database is designed to improve performance of the second part of this process. It accomplishes the process of rolling back in a manner that is more efficient than normal database rollback. The efficiency is created in several ways. In earlier versions of Oracle, the database could not be opened for use by the users until Oracle had resolved everything related to the transactions that failed in the media failure and subsequent database abort. Oracle would first roll everything forward, then roll back, then open the database. With fast transaction rollback, Oracle will open the database for use after the roll forward occurs, making the database open for users to execute transactions on the vast majority of the database.
What effect does this fast transaction rollback have on the rest of the database? Recall that there are several things a database does in order to facilitate transaction processing. The items that facilitate transaction processing include rollback segments, locks, and transaction marker statements such as begin transaction, commit, and rollback. First of all, each transaction is assigned to a rollback segment that stores any database changes the transaction makes, along with what the database looked like before the changes were made. These changes are stored in order to make it easy for the user process to discard the database transaction right up to the moment it is committed. Recall also the use of locks in transaction processing. In order to obtain read consistency for the life of a transaction, there are several locks a user process may acquire while the transaction operates. The user process holds all of them until the transaction ends.
When media recovery occurs, Oracle will go through the process of applying all the changes made to the database to the point in time of the failure, only to roll the uncommitted ones back. To do so, the database must both use the rollback segment entries made for the uncommitted transactions to put the database back the way it was, and force those uncommitted transactions to give up their locks. With the fast transaction rollback feature in place, allowing users to access the database after Oracle rolls forward, there are other user processes that are simultaneously accessing the database resources while these other things related to transaction rollback takes place. The impact may be felt by the user processes in the following ways:
| Rollback segments involved in the fast transaction rollback are in a partly available state. Transactions that operate on the database while fast transaction rollback takes place will have fewer rollback segments at their disposal. | |
| Locks held by transactions active at the time of failure will still be held until Oracle can force their release. This means that the rows or tables that may have been used in transactions that are in the process of rolling back are still locked. So, even though the database is technically open and available for use, if the user processes attempt to change the tables or rows that are held in locks awaiting fast transaction rollback, those processes will wait until the locks are released. |
Essentially, the benefit of fast transaction recovery is to allow the user processes wanting to do work on the database that is unrelated to the data being manipulated by the transactions in progress when the failure occurred to do so. But, for those users who may want to rerun the same transactions that were running when failure struck, or those users who want to use the same data that was being manipulated by the active transactions at the time of the failure, they will have to wait.
Fast transaction rollback has the potential to minimize downtime for the database after an instance failure. The fast transaction rollback accomplishes its goal by opening the database immediately after the roll-forward process occurs, rather than waiting until the database has had the chance to roll back also. Although this feature has the advantage of allowing the database to open sooner, the benefit is mixed, depending on the amount and types of transactions running at media failure time. The parts of the database that were involved in transaction processing at the time the failure occurred (rollback segments and locked rows/tables) will continue to be unavailable until fast transaction rollback completes. However, the users that do not require those resources in process of recovery will fare better performance-wise than the users that try to use the resources that are being recovered. Overall, the use of fast transaction recovery is helpful for the DBA who tries to minimize downtime for the organization.
Many times, the DBA will need to make the database available during the course of the recovery. In many organizations where several applications share the same database instance, a media failure causes one disk to crash containing data for one application while several other applications remain unaffected by this failure. If this is the case, it makes sense that the database be available for those other applications while the DBA handles recovery of the disk information for the affected application.
The next discussion will present information about handling the recovery process for a database that must be available to the users while the damaged or affected areas of the database are fixed. This discussion will focus on opening a database that is missing some of its datafiles, or even entire tablespaces, so that it is available for use while the DBA performs recovery.
It is possible to open a database that is missing datafiles. To understand how to do so, first the three database availability states will be reviewed. The three database availability states are nomount, mount, and open. There are different activities that Oracle engages in when the database is in each of these three states. Figure 15-2 demonstrates these pictorially. If the DBA puts the database into nomount state with the startup nomount command issued from Server Manager, then the Oracle instance will start the execution of all background processes and create the system global area, or SGA. As part of these tasks, the database parameter file init.ora will be read.
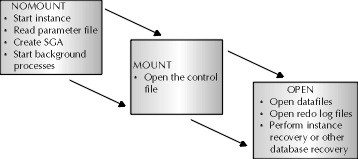
Figure 2: Database availability states and their corresponding activities
Several other things happen when the database is mounted. To mount the database and start the instance all at the same time, the DBA can issue the startup mount command from Server Manager, or use the alter database mount statement to mount a database to a previously started instance without a database mounted to it. When the database is mounted, the instance opens the control file containing the physical database specification of all files associated with the database. However, the database still cannot be accessed, and will not be accessible until the DBA opens it.
To open the database, the DBA can either issue the startup open command from Server Manager or the alter database open statement from SQL*Plus. The first statement allows the DBA to start the instance, mount, and open a database, all in one statement. The second allows the DBA to open a previously mounted database. Only when the database is open can users access the logical database objects like tables, indexes, and sequences that comprise the Oracle database.
In order to open a database that has had damage done to one or more of its datafiles as part of media failure, the DBA must engage in the following tasks. First, the Oracle instance must be started and the database must be mounted to it, but not opened. At this point, the database is not available for use. In order to open the database with a datafile missing, the DBA at this point should take the tablespace offline using the alter tablespace offline statement executed from the SQL*Plus or Server Manager command prompt. For the following example, assume that a media failure has damaged a datafile called index01.dbf, the only datafile for tablespace INDEX01. In order to open the database to other users while simultaneously performing database recovery on the damaged tablespace, the following code block can be used by the DBA:
STARTUP MOUNT;
ALTER TABLESPACE index01 OFFLINE;
RECOVER TABLESPACE index01 … ;
A few items related to open database recovery must be understood by the DBA. Recall that only complete tablespace recovery can be executed on an open database. Incomplete recovery in particular, which is a full database recovery, or complete database recovery, may not be executed while the database is open. Datafile recovery can be conducted either with the database available or without the database being available. Finally, redo logs must be archived in order to conduct online database recovery.
After issuing the appropriate commands to open the database for use, being sure to take the tablespace offline that contains damaged datafiles, open database recovery can commence. To refresh the discussion, the DBA must understand that the only option she may pursue for open database recovery is the complete recovery of a tablespace using both a backup copy of the datafiles that comprise the tablespace and all archived redo information taken both during the backup and after. Remember, online backups require use of archiving to capture the data changes made to the datafiles of a tablespace while the database was open during the database backup.
One of the main reasons to engage in open database recovery is to support database availability. The steps for tablespace recovery have been covered in Chapter 14. To refresh the discussion, the database must be open in order to accomplish a tablespace recovery. This is so that Oracle can view the contents of the database while the tablespace recovery occurs. However, the tablespace itself must be offline. An added benefit to using tablespace recovery is the fact that the DBA can allow users to access other tablespaces while the offline tablespace (presumably on the disk that failed) is being restored. In this example, assume that the INDEX01 tablespace needs to be recovered.
ALTER DATABASE MOUNT;
ALTER TABLESPACE index01 OFFLINE;
ALTER DATABASE OPEN;
ALTER DATABASE
RENAME FILE ‘/u01/oracle/home/index01.dbf’
TO ‘/u01/oracle/home/index01.dbf’;
ALTER DATABASE RECOVER AUTOMATIC TABLESPACE users01;
ALTER TABLESPACE users01 ONLINE;
Note that after database recovery, it is always a good idea to conduct a database backup. Though it is certainly possible to recover the database again if there should be another failure after recovery is complete (after all, the DBA performed just that), it speeds things greatly if the DBA can move forward with the certainty of knowing that all the work she just performed can be recovered more easily.
A final method DBAs may use to improve database recovery performance is the parallel recovery feature of the Oracle database. The DBA can run a recovery in parallel, which dedicates more processing power and database resources to accomplish the database recovery faster, thus minimizing downtime while also taking better advantage of the resources of the host machine running Oracle.
Parallel recovery requires Parallel Query to be in place on the Oracle database. The database must be running in parallel in order to run parallel recovery. When parallel recovery is used, the process from which the parallel recovery statement is issued will be the master process, or coordinator of the recovery. Oracle will allow the master process to create several slaves that execute the recovery in parallel according to several different parameters. In order to execute a parallel recovery, the DBA must issue the recover parallel statement from Server Manager, with several options specified. The DBA can execute parallel recovery using any of the recovery options available in Oracle: recover database parallel, recover tablespace parallel, and recover datafile parallel. The available options will now be discussed.
Parallel recovery is limited to the resources available to the database from the host machine running Oracle. The resources of the Oracle database that are available for parallel recovery are limited by an initialization parameter in the init.ora file called RECOVERY_PARALLELISM. This parameter represents the total number of parallel processes that can be used to execute a parallel recovery. The value for this parameter cannot exceed the value specified in another init.ora parameter set for database parallelism, PARALLEL_MAX_SERVERS.
When the DBA issues the parallel recovery command, she can specify the degree of parallelism to which the recovery should be executed. The degree of parallelism is synonymous with how many processes will operate in tandem to recover the database. That is, the degree of parallelism specified by the degree clause of the recovery operation represents the number of processes that will execute the recovery operation at the same time.
When the DBA issues the parallel recovery command, she can specify the instances that will be dedicated to the task of database recovery. In order to use the instances clause, the database must be mounted and opened in parallel by more than one instance. As opposed to database recovery, for which the database may be mounted to only one instance and not opened, parallel online tablespace recovery can be executed on an open database. The instances clause acts as a multiplier for the degree clause, allowing the DBA to apply a specified degree number of processes or degrees to database recovery for every instance specified for the instances clause. The total number of processes that can be applied to the database recovery equals degree times instances.
Executing the recovery of the Oracle database involves the following process. The DBA issues the recover database parallel statement with values for the degree and instances clauses, being careful not to exceed the value set for RECOVERY_PARALLELISM. The following code block can be used:
RECOVER DATABASE PARALLEL DEGREE 3 INSTANCES 2;
The following points should be made about the benefits of parallel recovery. First, parallel recovery works best in situations where a media failure may have damaged information on two or more disks. In this way, the recovery can operate on the two or more disks in parallel, rather than the DBA having to execute the recovery of each disk serially. However, the real performance benefit of parallel recovery depends on the operating system’s ability to have two or more processes writing I/O to the same disk or to different disks at the same time. If the operating system on the machine hosting Oracle does not support this function, then the performance gain made by parallel recovery may be limited.
The discussion in these four areas is designed to help minimize downtime. DBAs in 24-hour database operations environments may be required to know these techniques in order to obtain maximum performance on their database recovery techniques. Remember, the goal of database recovery is twofold: to get the database operational with no loss of data, and to get it that way in the shortest time possible.
In this section, you will cover the following topics related to troubleshooting the Oracle database:
| Using trace files and the alert log | |
| Using the V$ performance views to identify problems | |
| Detecting corruption in online redo logs | |
| Clearing corruption in online redo logs | |
| The DBVERIFY Utility |
Fundamental to the resolution of a problem in the Oracle database is the ability to identify it. In order for the DBA to solve a problem involving any aspect of the Oracle database, the DBA must know the problem exists. This fact is true even when backup and recovery are not required as a solution to whatever problem arises. Knowing how to identify problems that arise in Oracle is the topic of discussion in this section. This discussion will consist of several different topics. The first topic is identifying errors using called trace files. Included in this part is a discussion of a special trace file for the entire Oracle database called the alert log, which can be used to identify many different types of problems in the Oracle database. This discussion will also give introductory usage instruction for the dynamic performance views of the Oracle database. Dynamic performance views give real-time information about the Oracle environment and are located in the data dictionary, and they are identified by a special prefix to their name called V$. This discussion provides introduction to the more detailed information about V$ that will appear in the next unit covering OCP Exam 4. This section will also present how to detect and resolve corruption in the online redo logs of the Oracle database, and the special problems redo log corruption creates. Finally, a discussion of using the DBVERIFY utility will be presented.
The first topic to be presented in this section is the concept, function, and process of identifying errors using special files for background processes called trace files. Trace files can be used to identify many different things about the runtime activities of a process in the Oracle database. Any process, be it a user process, a server process, or an Oracle background process, can have a trace file. This trace file collects many different things about the process, including the input to the process as well as its output. These trace files can also list any errors that the process may have encountered during their execution. In the next unit, covering OCP Exam 4, the text will cover some uses for trace files in conjunction with user processes to determine any performance problems that may be occurring on the Oracle database. For this section, however, the discussion will focus on the use of trace files in conjunction with Oracle’s background processes, and how these trace files help the DBA identify problems that may arise during database usage.
Included in this part is a discussion of a special trace file for the entire Oracle database called the alert log, which can be used to identify many different types of problems in the Oracle database. The Oracle database has a special trace file that covers the entire database operation. This special trace file is the alert log, and it contains a great deal of runtime information about the execution of the Oracle database. If the DBA has any questions about what’s going on inside Oracle at any given point, the DBA can use the alert log to find out what is happening. Often, when a problem has occurred, the alert log is updated. The alert log is designed to act as a running log of any and all problems that occur on the database. There are several different things that are marked in the alert log. These factors include the following list of items:
| Initialization parameters at the start of the Oracle instance | |
| Information about the execution of all database, tablespace, and rollback segment creation statements | |
| Information about all startup and shutdown statements issued by the DBA | |
| Descriptive information about recoveries that may have been performed and the enabling/disabling of redo log archiving | |
| Many different types of error messages, along with a descriptive explanation of their cause |
The location of trace information and the alert log vary by database instance. The DBA can control where the files are placed with the use of several different parameters in the Oracle instance. The two parameters used are called BACKGROUND_DUMP_DEST and USER_DUMP_DEST. These parameters can be specified in the init.ora file and will be set at the time the instance is started. The locations specified for the parameters must conform to operating system specifications.
The location specified by the BACKGROUND_DUMP_DEST parameter identifies where Oracle will place the trace information for Oracle background processes like LGWR, DBWR, SMON, and PMON. In addition, the location specified by the BACKGROUND_DUMP_DEST parameter will also be where Oracle places its alert log. The USER_DUMP_DEST process is the location where Oracle will allow server processes to write trace files (that will be discussed later in the coverage of OCP Exam 4) for the purpose of identifying problems with performance in application code or SQL statements. The following code block illustrates the contents of an Oracle database alert log. Notice that each item in the alert log contains a time stamp for its activity. This alert log illustrates a startup and shutdown of an Oracle database, with no problems encountered. Notice that all activities associated with startup and shutdown are listed, along with the specified values for the initialization parameters for the database, and the activities of archiving on the database as well.
Dump file C:\ORANT\RDBMS733\trace\orclALRT.LOG
Mon Feb 16 10:39:10 1998
ORACLE V7.3.3.0.1
vsnsta=0
vsnsql=a vsnxtr=3
Windows NT V4.0, OS V192.0, CPU type 586
Starting up ORACLE RDBMS Version: 7.3.3.0.1.
System parameters with non-default values:
processes = 50
license_max_sessions = 1
control_files = C:\ORANT\DATABASE\ctl1orcl.ora
db_block_buffers = 200
compatible = 7.3.0.0.0
log_buffer = 8192
log_checkpoint_interval = 10000
db_files = 20
sequence_cache_hash_buckets= 10
remote_login_passwordfile= SHARED
mts_servers = 0
mts_max_servers = 0
mts_max_dispatchers = 0
audit_trail = NONE
sort_area_retained_size = 65536
db_name = orgdb01
snapshot_refresh_processes= 1
background_dump_dest = %RDBMS733%\trace
user_dump_dest = %RDBMS733%\trace
max_dump_file_size = 10240
Mon Feb 16 10:39:10 1998
PMON started
Mon Feb 16 10:39:11 1998
DBWR started
Mon Feb 16 10:39:12 1998
LGWR started
Mon Feb 16 10:39:14 1998
RECO started
Mon Feb 16 10:39:16 1998
SNP0 started
Mon Feb 16 10:39:18 1998
ALTER DATABASE MOUNT EXCLUSIVE
Mon Feb 16 10:39:19 1998
Completed: ALTER DATABASE MOUNT EXCLUSIVE
Mon Feb 16 10:39:19 1998
alter database open
Mon Feb 16 10:39:21 1998
Thread 1 opened at log sequence
Mon Feb 16 10:39:21 1998
Current log# 1 seq# 3 mem# 0: C:\ORANT\DATABASE\log2orcl.ora
Mon Feb 16 10:39:21 1998
SMON: enabling cache recovery
Mon Feb 16 10:39:27 1998
SMON: enabling tx recovery
Mon Feb 16 10:39:27 1998
Completed: alter database open
Mon Feb 16 10:40:25 1998
Thread 1 advanced to log sequence
Mon Feb 16 10:40:26 1998
Current log# 2 seq# 4 mem# 0: C:\ORANT\DATABASE\log1orcl.ora
Mon Feb 16 10:42:52 1998
Shutting down instance (normal)
Mon Feb 16 10:42:52 1998
License high water mark = 2
Mon Feb 16 10:42:53 1998
alter database close normal
Mon Feb 16 10:42:55 1998
SMON: disabling tx recovery
Mon Feb 16 10:42:56 1998
SMON: disabling cache recovery
Mon Feb 16 10:42:57 1998
Thread 1 closed at log sequence 4
Mon Feb 16 10:42:57 1998
Current log# 2 seq# 4 mem# 0: C:\ORANT\DATABASE\log1orcl.ora
Mon Feb 16 10:42:57 1998
Completed: alter database close normal
Mon Feb 16 10:42:57 1998
alter database dismount
Mon Feb 16 10:42:57 1998
Completed: alter database dismount
The alert log of an Oracle database is highly useful for identifying the activities of many different parts of the Oracle database at one time, in much the same way as a console window is useful for identifying runtime activities on other types of systems. Additionally, there is important information captured in the individual trace files for each Oracle background process. These processes have their trace information stored in the same location, but the trace files themselves generally contain only information for the individual process, while the alert log captures information for the database overall. Two trace files that are useful to look at if disk failure is suspected are the trace files for the LGWR and DBWR processes. Since these two Oracle background processes interact with disk I/O extensively, it is likely that the DBA will see a problem with disk I/O be detected by those two processes, and errors indicating those problems will therefore appear in their associated trace files.
The dynamic performance views of the Oracle database are highly useful for DBAs to understand what is happening on the Oracle database. This discussion will give introductory usage instruction for the dynamic performance views of the Oracle database. Dynamic performance views give real-time information about what Oracle is doing, and they are located in the data dictionary, identified by a special prefix to their name called V$. This discussion provides an introduction to the more detailed information about V$ that will appear in the next unit covering OCP Exam 4.
The dynamic performance views of the Oracle database can be used in several ways. First, they can themselves be accessed as long as the Oracle instance is active. Dynamic performance view information is generally valid for the life of the instance. Since it is information that is designed to give the DBA an understanding of the runtime performance of the Oracle database, the data in V$ performance views is not carried over from the execution of one instance to the next. Instead, the DBA must find other means to track that information across instances if it is something desired.
There are dozens of V$ performance views in the Oracle database. These views fall into several different categories, depending on the type of monitoring they are designed to provide. There are several different performance views designed to provide information about the database in several areas, some of which are listed in the following set of bullets:
| Archived redo log information | |
| Locks, latches, and other points of contention | |
| Oracle internal components such as the SGA, disk I/O and files, and database processes | |
| Any sort of database activity |
The use of V$ views to help diagnose problems is as follows. The database, as discussed, is comprised of many datafiles, redo logs, parameter files, and control files. The DBA can detect a problem with Oracle’s ability to write to a datafile using the V$DATAFILE performance view. One of the columns in this view is a status column. The status column indicates what the status of the datafile is. There are several different status possibilities, such as ONLINE or OFFLINE. One status, the RECOVER status, indicates that this datafile is one that is in need of recovery. Working in conjunction with the dynamic performance view V$DATAFILE, the DBA should first identify which datafiles are unavailable. Then the DBA should try to access that disk using appropriate operating system commands. If the access to that disk proves unsuccessful, the DBA may have identified a disk with a problem.
Of course, disks containing datafiles are not the only ones with the capacity for media failure. Any disk, as a matter of fact, can experience media failure that will render the disk inaccessible, and thus requiring the DBA to execute database recovery. In addition to V$DATAFILE, there is a dynamic performance view called V$LOGFILE, which identifies information about the online redo log files of the Oracle database. This performance view contains a status column as well, one that has several different possibilities regarding the states a log file may be in. One of those states is INVALID—meaning that the redo log file is inaccessible by the LGWR process. If a DBA spots one of her log files reading the INVALID state in the V$LOGFILE performance view, she may have a problem with media failure that requires attention. As such, it is always a good idea to multiplex redo log files, or specify several different log file members, each placed on a different disk. Multiplexing redo log information prevents the possibility that the failure of a disk containing the only redo log file for the log currently online causes the entire instance to crash.
Finally, the DBA must pay attention to the possibility of disk failure eliminating one of the control files for the database. The instance is aware of the database’s control files through the use of the CONTROL_FILES parameter in the init.ora file. If any of the control files specified in this parameter should be damaged by a media failure, then the DBA must shut down the instance and restore the control file. Since the control file is such an important link for Oracle to know what the physical side of the database looks like, it is important that the DBA allow Oracle to maintain multiple copies of the control file. In order to detect problems with media failure that may have damaged a control file, the DBA usually has to look in the alert log.
In addition to accessing the dynamic performance view information directly as the DBA would for another table in the data dictionary or in the database, the DBA can access the information from dynamic performance views using the Oracle Server Manager database monitoring tools. The Server Manager tool allows access to the V$ performance tables without dealing with the actual access to those views. Instead, the Server Manager program gathers data from these views and presents the data to the DBA in a graphical user interface.
Normal redo log operation consists of LGWR writing redo log buffer information to the online redo log. Optional but highly recommended to this process is the archival of redo log information. One situation that Oracle may encounter in the process of writing redo log information is the corruption of a data block within the online redo log, containing redo information. This scenario is highly detrimental to the recoverability of a database. The reason this is so damaging is that if undetected, a redo block corruption will get propagated silently to the database archived redo logs. Only when Oracle attempts to recover the database using the archived redo log will Oracle discover that the archived redo information is corrupted. However, by then it is too late—the database has failed and complete recovery is questionable.
For added protection, the DBA can specify redo log checksums to ensure that data block corruption does not occur within archived redo logs. This feature verifies each block by using checksums of values for each data block. If Oracle encounters unexpected values from this operation, Oracle will read the data in the corrupted data block of one online redo log member from another member in the redo log group. Hence the benefit of multiplexing redo log groups is twofold—Oracle is more likely to obtain good archived redo log information, and is likely not to have instance failure occur as a result of a media failure taking with it the only copy of an online redo log.
Checking redo log file blocks for data corruption is conducted only when the checksum operation is active. To activate this feature, the DBA must set the LOG_BLOCK_CHECKSUM initialization parameter to TRUE. This parameter is set by default to FALSE, rendering redo block checksum inactive by Oracle’s default behavior. When set to TRUE, Oracle will check every redo log block at archive time, substituting copies of corrupted blocks in one member with the same uncorrupted blocks from another redo log member. As long as the data block is not corrupted in every redo log member, the process will complete. If the block is corrupted in all members, however, Oracle will not be able to archive the redo log.
There are some points to be made about this feature. First of all, the use of log block checksums is irrelevant unless archiving is enabled. If the DBA is not archiving the redo log information for the database, she might as well not use the checksum feature. Second, there is some performance degradation that may be experienced as a result of checking sums. The checksum process occurs at each log switch, at the same time the archiving of redo logs takes place. The performance loss would occur at this point. If online redo logs are filling fast due to heavy database usage activity, there might be some overall impact on performance. For the most part, however, the benefit of using LOG_ARCHIVE_CHECKSUM outweighs any performance hit. It is recommended that this feature be used on the Oracle database.
If data block corruption is detected in an online redo log, Oracle will automatically try to obtain the same block from a different member of the online redo log group. So long as the group is multiplexed using several different members, this will minimize problems with data block corruption in the redo logs, because it is unlikely that the same block will be corrupted in two or more redo log members on two or more disks.
If for some reason the same redo data block is corrupt in all members of the online redo log (or if there is only one member in the online redo log), then Oracle cannot archive the redo log. Furthermore, there is some manual intervention that the DBA must engage in order to correct the problem. Recall the discussion about archiving redo logs manually in Chapter 13. If a redo log does not get archived manually and all online redo logs fill with redo information, Oracle will not accept any database transaction activity until the redo logs are archived. Since the redo log containing block corruption cannot be archived, an alternate step must be accomplished by the DBA. That alternative is that the online redo log must be cleared.
To clear an online redo log, the DBA must accomplish the following step. The DBA must issue an alter database clear logfile group statement. The following code block demonstrates the clearing process of an online redo log. In order to clear an unarchived redo log, the DBA must remember to specify the unarchived keyword in the statement. The issuance of this statement will eliminate all redo information in the database redo log group specified. An example of the statement is demonstrated in the code block following this paragraph. This statement must be issued by the DBA in a timely fashion if Oracle is unable to archive a redo log in the event that every member has a block corruption in the same place.
ALTER DATABASE orgdb01
CLEAR UNARCHIVED LOGFILE GROUP 5;
In the event a redo log is found to be corrupt by the checksum process, the DBA must back up the database. If a database backup does not take place, the DBA will not have a complete set of archives from which to conduct a complete database recovery. Without that complete set of archives, the DBA will have only enough data to conduct an incomplete recovery, which results in a loss of data in the event of a database failure. The best method for handling the situation is simply to take a new backup, start archiving again, and be done with it.
Any redo log can be cleared, not just the one currently online. For example, if the DBA would like to clear the redo log that was just archived, she can issue the alter database clear logfile group statement to do so. If the redo log being cleared has already been archived, then the DBA should not use the unarchived keyword from the previous example. A demonstration of usage for this statement is offered in the following code block. Assume in this example that Oracle is currently writing to online redo log group 5, having just finished on group 4. An archive of group 4 is then created. Afterward, the DBA decides to clear the redo log group. She can do so with the following statement:
ALTER DATABASE orgdb01 CLEAR LOGFILE GROUP 4
The verification process offered with respect to the database online redo log data blocks is a useful process for ensuring that bad data does not get propagated to the backup copies of a database. However, the LOG_ARCHIVE_CHECKSUM parameter does little to check any other aspect of the database. Suppose the DBA wants to verify the integrity of other database files. Verification of structural integrity of Oracle database files is done with the DBVERIFY utility.
DBVERIFY is a utility that verifies the integrity of a datafile backup or production file. It can be used either to verify that a backup is usable, to verify the usability of a production database, or to diagnose a situation where corruption is suspected on a datafile or backup. DBVERIFY is usually run from the operating system command line, and is a stand-alone utility. It operates on a datafile or datafiles of a database that is currently offline. As such, it usually runs with good performance. Like other Oracle utilities, it runs from the command line according to the parameters that are identified for it. There are several parameters that can be specified. They are FILE, START, END, BLOCKSIZE, LOGFILE, FEEDBACK, HELP, and PARFILE. The following presentation will describe briefly each of the parameters that can be used with DBVERIFY.
This parameter specifies the name of the datafile that DBVERIFY will analyze. Without this parameter, the utility can do nothing.
This parameter specifies the start address in the Oracle blocks where DBVERIFY will begin its analysis. If no value for START is specified, then the utility will assume the start of the file.
This parameter specifies the end address in the Oracle blocks where DBVERIFY will end its analysis. If no value is specified, the utility will assume the end of the file.
This parameter specifies the database block size for the database. It should be specified explicitly in all cases where the block size for the Oracle database is not 2K, or 2,048 bytes. The value should be specified in bytes. If the database is not 2K and a value is not specified for this parameter, an error will occur and the run of DBVERIFY will terminate.
This parameter identifies a file to which all output from DBVERIFY will be written. If no filename is specified, then DBVERIFY will write all output to the screen.
This parameter allows the DBA to use an indicator method built into the utility that indicates the progress made by the utility. The indicator works as such. An integer value is assigned to the FEEDBACK parameter, which represents the number of pages that must be read of the datafile before DBVERIFY will display a period (.) on the output method, either the terminal or the log file. If FEEDBACK=0, then the function is disabled.
When DBVERIFY is run with HELP=Y, the utility will print out a help screen containing information about the parameters that can be set for this tool.
As with other Oracle utilities, all parameters can be included in a parameter file that is named by the PARFILE parameter. This parameter identifies a parameter file for use by the utility in this run.
The DBVERIFY tool is a stand-alone program that, again, should be run from the command line. The name for the command that runs the utility varies from one operating system to the next, but the functionality is the same. If the DBA encounters any errors when running DBVERIFY, it is recommended that the DBA contact Oracle Worldwide Support. On many systems, the utility is referred to on the command line as dbv. The following code block demonstrates usage of this utility from a UNIX prompt:
$ dbv file=users01.dbf blocksize=4096 logfile=users01.log feedback=0
Alternately, the DBA can execute the utility with the use of a parameter file, as follows:
$ dbv parfile=users01.par
The contents of the parameter file are listed as follows:
file=users01.dbf
blocksize=4096
logfile=users01.log
feedback=0
Typically, the DBVERIFY utility is only used in cases where the DBA is trying to identify corruption problems with the data in a datafile. Its output should be interpreted with the assistance of Oracle Worldwide Support. In fact, its use is often under the guidance of Oracle Worldwide Support. However, it, like all other troubleshooting methods identified herein, can be quite useful in resolving database problems.
In this section, you will cover important topics related to the standby database feature of Oracle:
| Standby database configuration | |
| Deployment of the standby database when disaster strikes | |
| Switching back to the principle database |
All preparation for database recovery with configuring, reading, testing, and tuning, pays off when disaster strikes. With tensions running high in the organization when a database crashes, the assumptions made are that the database will be available, and soon. And the sooner it can be made available, the better for everyone. The final area of discussion in this chapter is the use of the standby database. Introduced in Oracle 7.3, the standby database offers an additional option for minimizing downtime. So minimal is downtime with the standby database that some may consider the high cost for operation and challenge of maintenance to be a small price to pay. Those organizations tend to be large ones, where a lot of time and money are riding on the availability of a machine hosting a database.
The standby database feature of Oracle allows DBAs to configure and maintain an operational clone of a mission-critical database within an organization. When disaster strikes, the DBA can use the standby database to minimize downtime for the organization by having a fully functional and up-to-the-minute copy of the database on hand. The DBA in this situation need only switch to the standby database in order to handle short-term goals for database recovery like minimizing downtime and having the database available for the users again on short notice.
The standby database is an exact replica of the current production database. To make the match even more identical, it is usually recommended that the DBA use identical hardware and operating system versions for the standby database in order to avoid any unplanned inconsistencies between versions at the time a disaster strikes. Obviously, this may be an expensive proposition—for example, the organization running on the latest and greatest hardware that cost $100,000 for the main system alone, without an identical backup system. If a decision is made to run the standby database feature to ensure 100 percent availability for a mission-critical database, that decision effectively doubles the cost of database hardware and software for the production machine, not to mention the cost of additional maintenance. However, the extra cost for hardware, software, and maintenance may be a small price to pay for the security of knowing the DBA has a spare database on hand to minimize the downtime and data loss to the period of time it takes users to connect to a new machine.
The standby database operates in the following way. To first create the standby database, the DBA should take a full offline backup of the primary database and create a special control file for the standby machine. The statement used to create that control file is alter database create standby controlfile as ‘filename’. Finally, the DBA should archive the current redo logs using alter system archive log current. Refer to Figure 15-3 for more information.
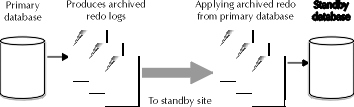
Figure 3: Data movement between primary and standby database
The following list demonstrates the activities in a step-by-step format:
ALTER DATABASE orgdb01
CREATE STANDBY CONTROLFILE
AS ‘stbydb.ctl’;
ALTER SYSTEM ARCHIVE LOG CURRENT;
After the necessary backups have been made, the DBA should transfer the standby database backup files and restore the primary database on the standby machine. At this point, the DBA has a baseline copy of the required database objects and information. From there, the maintenance of transaction information between the primary and standby database is accomplished with the use of archived redo logs. Redo logs are generated as information is entered into the primary database. The redo logs are then archived and a copy is sent to the standby database, where it will be restored to the standby database. Essentially, the standby database is always in recovery mode. Ideally, the continuous process of recovery required to apply an ongoing amount of archived redo information prompts the DBA for the standby and primary database to devise some sort of automated method for moving and applying archived redo logs between the two and restoring the data on the standby database. The following steps should be engaged to begin the perpetual recovery of the standby database:
STARTUP NOMOUNT;
ALTER DATABASE MOUNT STANDBY DATABASE EXCLUSIVE;
RECOVER FROM pathname STANDBY DATABASE;
For purposes of ensuring data consistency between the primary and standby database, it is important the DBA bear some things in mind. First, the DBA must always ensure that every data change made in the primary database finds its way onto the standby database. In general, as long as redo information is generated on whatever activity takes place on the primary database, the standby database will be updated as well. Archiving must be used in conjunction with the standby database. Some activities should be avoided, particularly those activities that do not produce redo log information. Such activities include creating database objects with the unrecoverable option. The performance benefits of creating database objects with the unrecoverable option will be discussed in the next unit covering OCP Exam 4. At this point, it should be said that the performance gain using this option is made at the expense of creating archived redo information for the database operation. The use of a standby database for recovery purposes cannot afford this performance improvement, and for this reason the DBA should never use the unrecoverable option when creating database objects or making other changes to the database.
A few final remarks about the use of a standby database will be made. It is important that the flow of archived redo log information from the primary database to the secondary database be constant. Any interruptions, such as the need to clear an online redo log because of block corruption, make it necessary for the DBA to rebuild the standby database from backup. Since this will require that the standby database not be available for recovery, the database is particularly vulnerable to disaster during the period of time the standby database is being rebuilt.
In the situation where the primary database experiences disaster, the DBA can switch to using the standby database in the following way. First, any remaining archived redo information from the primary database must be applied to the standby database as part of the ongoing recovery that creates the standby database. This step should include the online redo logs from the primary database, if possible, so as to allow the standby database to contain every committed transaction to the point in time of the failure. Next, when the recovery is complete, the DBA must activate the standby database so that it may be used in a production capacity. This step is accomplished with the alter database activate standby database statement. After activating the standby database, the DBA can handle any last-minute changes to tablespaces, such as putting them into read only status or bringing them online or offline, depending on the status they had in the primary database. The final step is to have users point their connections to the new production machine. Depending on the application, there may (and perhaps should) be some centralized method for automating this task in order to prevent a rash of users pointed to an invalid or offline database, then calling the DBA or some other help desk group to figure out what to do. The steps for this process are listed below for reinforced understanding:
STARTUP MOUNT;
ALTER DATABASE RECOVER;
ALTER DATABASE
ACTIVATE STANDBY DATABASE;
It is important that the DBA understand that once the standby database is activated and used by the users, it becomes the production database. The original production database can then be built from the new database and it will become the new standby database. The same procedures for creating the original standby database apply to the creation of the new standby database. However, the DBA must understand that there is no point in time where the DBA switches the database activity back to the original production database. After the standby database is activated and used, there is no further link between the production and the standby database. This operation occurs again and again.
The main benefit of using the standby database is to minimize downtime in the event of media failure. However, the standby database essentially requires the DBA to maintain two copies of the organization’s data at all times, on two separate machines, which increases hardware, software, and maintenance costs substantially. For many organizations, such as national or worldwide operations where 24-hour, 99+ percent availability is a requirement (not a nice feature), the standby database is an integral tool for delivering that requirement. However, the standby database is also the most expensive option for backup and recovery. The use of a standby database should be tested thoroughly in order to understand the impact of relying on this method to minimize downtime. The importance of testing the use of this option is greater than the testing of other backup and recovery options for one reason—an organization even considering use of the standby database must have critical needs for that database to be available at all times.
The focus of database recovery is to minimize downtime and minimize data loss. In this chapter, several areas of maintaining a database from the perspective of backup and recovery are discussed. The first advanced topic of backup and recovery—minimizing downtime—will consist of several areas. These discussions include system startup after database failure. This section also includes discussion of starting up the database in situations where parts of the database are damaged. A continuation of the discussion started on the topic of leaving the database open during tablespace recovery is included as well. Finally, related to minimizing downtime, the parallel recovery option is discussed. Troubleshooting is also be presented. The use of the alert log and process trace files is discussed, as is a further discussion of the dynamic performance views. The detection and resolution of corrupt data in online redo logs is also presented in this chapter. Finally, for this discussion, the use of DBVERIFY is presented. Finally, the usage and functions of the standby database feature in Oracle are presented. These three topics comprise the advanced topics of Oracle backup and recovery, and together comprise 12 percent of OCP Exam 3.
The first area of discussion within the topic of minimizing downtime is starting the database after system failure. The database startup after system failure will be faster than a typical database startup. This is due to the use of fast transaction rollback when opening the database in media recovery situations. Database recovery consists of two general steps: rolling forward and rolling back. The roll-forward process consists of applying all transactions, committed and uncommitted, to the database, while rollback consists of discarding those transactions that were not committed to the database at the time of the failure. Opening the database with fast transaction rollback consists of several items. First, Oracle will not open the database until the roll-forward process completes. However, the database will not wait until the rollback completes. Instead, Oracle will open the database for regular use after the roll-forward takes place, rolling back uncommitted transactions at the same time users are accessing the database objects. A couple of situations may arise from this. First, if a user process attempts to change a row or table that is involved in the rollback process, the transaction that failed may still hold a lock to that object, forcing the user to wait. Second, there will be fewer rollback segments available to user processes while the fast transaction rollback takes place, due to the fact that the rollback segments that were being used by transactions that failed in the database failure will be involved in the fast transaction rollback effort. However, fast transaction rollback does allow the DBA to open the database sooner that would otherwise be permitted in a database recovery situation. Thus, downtime can be minimized.
Another area of minimizing downtime comes with the ability to open the database for use when datafiles are damaged or missing as a result of a media failure. In order to do this, the DBA must first mount but not open the database. At this stage, the DBA can take the tablespace containing lost datafiles offline. Then, the DBA can open the database. By opening the database even while parts of it are damaged, the DBA allows users of the database to access undamaged parts of the database while damaged parts are being fixed.
The DBA can then initiate a complete tablespace recovery on the damaged tablespaces with the use of online tablespace backups and a full set of archived redo logs. The types of organizations that benefit most from this sort of recovery are those with multiple applications running on the same database. A media failure in this situation may damage the datafiles associated with only one of the applications, implying that other applications should not have to suffer downtime because of damage to another application. This operation is usually accomplished with the recover tablespace option. Recall that the recover tablespace option requires a complete recovery to be performed to the point in time of the database failure.
A final area covered with respect to minimizing downtime is the use of the parallel recovery feature of Oracle. Parallel recovery can improve the performance of a database recovery when two or more disks have been damaged, or a great deal of redo must be applied as part of the recovery. The parallel feature is incorporated into recovery with the use of the Server Manager recover database parallel command. The DBA can issue this statement from Server Manager line mode or using the graphical interface. Parallel recovery requires two clauses to be specified as part of the recovery. The first is called degree. The integer specified for this parameter represents the degree of parallelism for the database recovery, or the number of processes the database will have actively attempting to recover the database. The second clause is called instances. The integer specified for this parameter indicates the number of instances that will accomplish the recovery. Each instance involved in the parallel recovery can have the number of processes dedicated to recovery indicated by degree, so in a sense the instances parameter is a multiplier for the degree clause. Because of the multiplier effect, it is important to remember that the number of processes that can be used to handle parallel recovery may not exceed the value set for RECOVERY_PARALLELISM, an initialization parameter set at instance startup in the init.ora file. Further, database recovery is more effective when the operating system of the machine hosting the Oracle database supports synchronous I/O. Otherwise, there will be limited gains in recovery performance using recover database parallel.
The next area of discussion in this chapter is the technique of troubleshooting a database to identify issues requiring recovery from backup. The first technique is mastering the use of trace files and the alert log for identifying problems with the operation of the database. As presented first in the second unit of the book covering OCP Exam 2, the Oracle database has several background processes handling various functions for the database, such as the operation of moving redo information or database blocks from and to the disks, various recovery activities, and other operations. Each of these background processes writes a log of its activities, detailing any errors it may have encountered, when it started running, and other things. These logs are called trace files, and they are stored in a location identified to Oracle by the use of the initialization parameter in init.ora called BACKGROUND_DUMP_DEST. Each of the user processes connecting to the database requires a server process to run Oracle database transactions on its behalf. These processes also create an activity tracing log. This log is stored in another location, specified with the use of the initialization parameter in init.ora called USER_DUMP_DEST. A final, and perhaps most important, log mechanism is the overall log of activity for the Oracle database, called the alert log. This file contains all error messages encountered by the database in its normal activity, along with startup and shutdown times, archiving information, and information about the startup and shutdown of background processes. If the DBA suspects there is a problem with the operation of the database, the alert log should be the first place she looks.
Another method the DBA can incorporate into the detective work required for the identification of database problems is the use of the dynamic performance views in the Oracle data dictionary. These views track performance information for the database, and their names are usually prefixed with either V$ or X$. Several of these views identify the status for various components of the database, such as the datafiles and redo log file of that database. If there is a problem with the status of a datafile or redo log file arising from the failure of a disk, Oracle will mark the file with the appropriate status in the appropriate dynamic performance view. There are several performance views involved in the task of backing up and recovering the database. Some of these have already been identified. The two views emphasized in this discussion are the V$DATAFILE and the V$LOGFILE views. Both of these dynamic performance views contain status information for each of the files they represent. These files are datafiles and redo log files, respectively. If the DBA should find a datafile with a status of RECOVER or a redo log file with a status of INVALID, the DBA may want to investigate a problem with accessing the disk containing the datafile and/or log file using operating system means. These methods may be used to check the status of the database for recovery issues.
One particular issue for DBAs that may arise in the need to identify damage to the database is the need for verification mechanisms of the database. There are a few mechanisms available for the DBA to do just that. The first pertains to the verification of operation on the online redo logs. There is a feature that will verify the blocks of an online redo log before archiving, or before applying an archived redo log as part of database recovery, to prevent the propagation of corrupted data blocks in the backup and recovery of an Oracle database. To use this feature, the DBA needs to set the LOG_ARCHIVE_CHECKSUM initialization parameter to TRUE. If the DBA is using archive checksums to confirm the integrity of the blocks in an online redo log, the following process will occur. When Oracle reaches a log switch, it will check the online redo log for corruption in the data blocks of the online redo log to archive. If Oracle finds corruption in an online redo log, it will try to write archive information using a different redo log file. If all members contain the corruption in the same data block, Oracle will not be able to archive that redo log and archiving will stop.
At this point, the DBA must intervene in the archiving process. The redo log containing the corrupt data block will need to be cleared using the alter database clear unarchived logfile group statement. Since the log has not been archived, the DBA will also need to include the unarchived option as described above. Any redo log group can be cleared, depending on the desires of the DBA. For example, a redo log can be cleared after archiving by using the statement identified above for clearing online redo logs, but since the statement has been archived, the unarchived option can be eliminated. However, once a redo log is cleared, the DBA no longer has a complete set of archived redo logs for database recovery. Unless the DBA backs up the database at this point, the DBA will only be able to execute incomplete recovery from database failure. The DBA should be sure to back up the database in the event of clearing online redo logs.
Another tool available for the DBA to use in verification of other types of files such as datafiles is the DBVERIFY utility. This utility will take an offline datafile and inspect it for block corruption. DBVERIFY is a stand-alone utility that operates in the same way as other utilities discussed in Oracle. To run it, the DBA supplies a set of parameters. Some parameters the DBA can identify for running DBVERIFY are listed: FILE, START, END, BLOCKSIZE, LOGFILE, FEEDBACK, HELP, and PARFILE. The FILE parameter is used by the DBA to name the file that DBVERIFY will operate on, while START and END are used to tell DBVERIFY where in the file to start and end the verification. The defaults are the beginning and end of the file, respectively. The BLOCKSIZE parameter specifies the size of Oracle blocks in the database, in bytes. The LOGFILE parameter names a file to which the output of DBVERIFY will be written. If no log file is specified, DBVERIFY writes its output to the screen. The FEEDBACK parameter can be assigned an integer that specifies how many pages of the datafile will be read before DBVERIFY puts some notification of its progress on the screen. Setting the HELP parameter to ‘Y’ will cause DBVERIFY to display information the DBA can use for setting other parameters. Finally, the PARFILE parameter can be used to name a parameter file containing values for other parameters used in DBVERIFY. Due to the fact that DBVERIFY identifies problems involving database corruption, use of it may be best undertaken with the guidance of Oracle Worldwide Support.
The final topic covered in this chapter is the use of the standby database feature of Oracle. DBAs who need to provide a high degree of availability for the users of a database may incorporate a standby database into the overall backup and recovery strategy. A standby database is an identical twin database for some other database, and it can be used in the event of a disaster. In order to use the standby database feature of Oracle, the DBA must use archiving in both databases. The reason archiving is necessary is because the standby database is updated with data changes on the primary database by applying the archive logs generated by the primary database.
To create a standby database, the DBA must execute the following steps. First, the DBA should acquire a machine to host the standby database that is identical to the machine hosting the primary database. Next, the DBA needs to take a complete backup of the primary database. After that, the DBA must create a special control file for the standby database using the alter database create standby controlfile as ‘filename’. Finally, the DBA should archive the current set of redo logs using the alter system archive log current statement.
With the archived redo logs, datafile backups, and standby control file, the DBA can create a baseline standby database. After creating the standby database, it must be perpetually standing by for database recovery in order to keep the standby database current with the changes made in the primary database. To do so, the DBA should use the startup nomount statement in Server Manager, followed by the recover standby database statement. Archive logs generated by the principle database should be placed in the location specified by LOG_ARCHIVE_DEST on the standby database, or, alternately, the from clause can be used in conjunction with the recover standby database statement. Ideally, the process of moving archive logs from the primary database to the standby will be automated in order to keep the standby database as current with changes in the primary database as possible.
When disaster strikes the production database, the DBA must do the following to get users on the standby database as quickly as possible. First, the application of all archived redo logs on the standby database must complete as quickly as possible. Next, the DBA should shut down the standby database and restart it using startup mount. From there, the DBA should execute a recover database statement, being sure to omit the standby clause. As part of this recovery, the DBA should try to apply the current online redo logs on the production database to the standby database in order to capture all transaction information up to the moment of failure on the other database. After recovery of the standby database is complete, the DBA can execute the alter database activate standby database statement. From this point on, the standby database is the production database. Switching back to the original production database, then, will not happen unless the production database is made into the standby of the new production database and the new production database fails.
Standby databases can offer enormous benefit to the organization requiring 24�7 database availability with little or no option for downtime. However, standby databases are a costly solution to database recovery. The costs of a standby database are usually twice the price of the production database hardware and software, plus added expenses for maintaining both databases. Of course, the price of downtime per minute on a mission-critical database system can be far, far higher, thereby justifying the additional costs.
| The reason the database will start quickly after a system failure is due to the fast transaction rollback feature of the Oracle database. | |
| There are two general parts to database recovery: roll forward and rollback. Fast transaction recovery allows Oracle to open the database after roll forward is complete, executing the rollback while users access the database. | |
| Fast transaction recovery eliminates the wait for a database to open after system failure, minimizing downtime so the DBA can initiate recovery quicker. However, users entering the database may still encounter delays due to rollback segments still being involved with recovery, and locks on tables and rows that are still held by dead transactions. | |
| In some organizations, a media failure may not impact all users. | |
| To allow the users who are not impacted to continue using the database even when datafiles are missing, the DBA can open the database in the following way. First, the DBA should use startup mount from Server Manager to start the instance and mount the database. From there, the DBA can take the tablespaces containing missing or damaged datafiles offline with the alter tablespace offline statement. After that, the DBA can open the database with the alter database open statement. | |
| Recovery on parts of a database that are missing can be accomplished using the methods for complete tablespace recovery. The DBA will require an online backup and all appropriate archived redo logs. For this recovery, the tablespace must be offline. | |
| When the DBA is done recovering the tablespace damaged, while the rest of the database is used by the users, the DBA can back up the recovered tablespace or the entire database. | |
| Parallel recovery can be used to improve recovery time for the Oracle database. To engage in parallel recovery, the DBA can use the recover database parallel statement from Server Manager. | |
| There are two clauses that must be set for parallel recovery: degree and instances. | |
| The degree option indicates the degree of parallelism for the recovery, or the number of processes that will be used to execute the recovery. | |
| The instances option indicates the number of instances that will engage in database recovery. | |
| The total number of processes that will engage in parallel recovery equals degree times instances. This value may not exceed the integer set for the RECOVERY_PARALLELISM initialization parameter set in the init.ora file. | |
| Troubleshooting the Oracle database can be accomplished by looking in trace files or the alert log. | |
| Every background process writes its own trace file, containing information about when the background process started and any errors it may have encountered. | |
| A special trace file exists for the entire database, called the alert log. This file contains trace information for database startup and shutdown, archiving, any structural database change, and errors encountered by the database. | |
| The V$ performance views may also be used to detect errors in the operation of the database. | |
| The V$DATAFILE view carries information about the datafiles of the database. One item it contains is the status of a datafile. If the status of a datafile is RECOVER, there may be a problem with media failure on the disk containing that datafile. | |
| The V$LOGFILE view carries information about the redo log files of the database. One item it contains is the status of a log file. If the status of the logfile is INVALID, there could be a problem with media failure on the disk containing that redo log. | |
| Another cause of problems in the Oracle database is the problem of data integrity. If there is a corruption in the online redo log of the database during archiving or an archived redo log during recovery, the DBA risks having an unusable set of backups for database recovery. | |
| To minimize risk of storing corrupt archived redo information, the DBA can use a verification process available for redo logs. To use this verification process, the DBA should set the LOG_ARCHIVE_CHECKSUM parameter in the init.ora file to TRUE and restart the database. | |
| The redo log verification process works as follows. At a log switch, Oracle will check every data block in the redo log as it writes the archive. If one is corrupt, Oracle will look at the same data block in another redo log member. If that data block is corrupt in all members of the online redo log file, Oracle will not archive the redo log. | |
| If Oracle does not archive the redo log, the DBA must intervene by clearing the log file. This step is accomplished with the alter database clear unarchived logfile group statement. If the log file group has been archived, the unarchived clause above can be eliminated. | |
| Verifying the integrity of a database can also be executed on its datafiles using the DBVERIFY utility. DBVERIFY is a stand-alone utility that verifies a file or files of an offline database or tablespace. | |
| Operation of DBVERIFY involves specifying parameters to manage its runtime behavior. The parameters that may be specified include FILE, START, END, BLOCKSIZE, LOGFILE, FEEDBACK, HELP, and PARFILE. | |
| FILE is used to identify the filename of the datafile that DBVERIFY will analyze. | |
| START is used to identify the Oracle block where DBVERIFY will start analysis. | |
| END is used to identify the Oracle block where DBVERIFY will end analysis. | |
| BLOCKSIZE is used to identify the size of blocks in the datafile. | |
| LOGFILE is used to identify a file that DBVERIFY will write all execution output to. If not used, DBVERIFY writes to the screen. | |
| FEEDBACK is a special feature whereby DBVERIFY writes out dots on the screen (or logfile) based on progress, or the number of pages it has written. | |
| HELP is used to obtain information about the other parameters. | |
| PARFILE is used to place all other parameters in a parameter file. | |
| The standby database is used by DBAs to create and maintain a clone database for the purpose of minimizing downtime in the event of a disaster. | |
| The hardware used to support the standby database should be identical to the machine that supports the production database. | |
| To create a standby database, the DBA must do the following. First, take a full backup of the database, either offline or online. Then, create a standby database control file with the alter database create standby controlfile as ‘filename’. Finally, the DBA should archive the current set of redo logs using the alter system archive log current statement and move it all to the standby machine. | |
| After creating the standby database on the other machine, the DBA should put the standby database into perpetual recovery mode. The first step is to use the startup nomount option to start the database with Server Manager. Then, the DBA must issue the recover standby database statement. At this point, the database will apply archived redo logs from the primary database to the standby database. | |
| When a disaster strikes, the DBA can recover the final transactions made to the primary database and move data to the standby database. Starting the standby database is accomplished in the following way. The DBA should shut down the standby database and restart it using startup mount. From there, the DBA should execute a recover database statement, being sure to omit the standby clause. | |
| As part of this recovery, the DBA should try to apply the current online redo logs on the production database to the standby database in order to capture all transaction information up to the moment of failure on the other database. After recovery of the standby database is complete, the DBA can execute the alter database activate standby database statement. | |
| From this point on, the standby database is now the production database. There is no step later where the DBA switches it back, unless the original database is turned into a standby for the new production database and the new production database fails. | |
| The standby database, though costly, is the best option for minimizing downtime to make a fast recovery. |