In this chapter, you will understand and demonstrate knowledge in the following areas:
| Backup and recovery motives | |
| Backup methods |
Mastering the art of backup and recovery is perhaps the most important area of Oracle database administration. However, this important aspect of maintaining the integrity and durability of the database with the presence of restorable copies is one of the most difficult and least-understood areas for those software professionals working with Oracle. This chapter and the unit it is part of cover required knowledge areas in backup and recovery for OCP Exam 3. Approximately 17 percent of the material in that test is covered in this chapter.
In this section, you will cover the following topics related to backup and recovery motives:
| Importance of backups | |
| Importance of business requirements | |
| Disaster recovery issues | |
| Management involvement | |
| Testing backup and recovery |
Backups of the database are copies of the database that can be used in the event of an emergency. The restoration of an Oracle database depends on the presence of these backups. Without adequate backups of the database, there can be no recovery of that database. This sounds like a critical function, and it is. However, database backup and recovery is one of those "out of sight, out of mind" aspects that many developers and users ignore for the most part. The assumption made in most IT shops is that "someone else is handling backups, therefore I don’t need to worry about it." That person is the database administrator. The DBA must take this role seriously, for although there won’t be serious repercussions on the day a backup is missed, dropped, or forgotten, the problem will surface later when database failure occurs.
The implications of system failure for this example depend on which component is lost. Figure 11-1 illustrates the basic components of the database server used in this company. The problems created by various components in this architecture have varying solutions. For example, if the processor or memory chips of a database server were to fail, chances are that the situation, though annoying, would be recoverable with or without the presence of additional copies of data waiting in the wings for the inevitable problem to occur. The same may be said for the loss of a disk controller, the device used to manipulate the disks of a server.
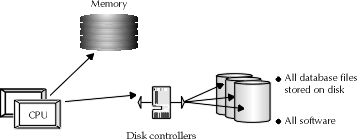
Figure 1: Components of a database server
Disk crashes are another story. No database recovery involving the replacement of data caused by failure of a disk can be performed without the use of a backup. Although several things can fail on a database server that will not require the database to require backups, the one thing that can happen, namely disk failure, wreaks havoc in terms of data loss. This loss is so costly that every system, large and small, should take the necessary precautions to ensure that the system will be recoverable to the extent that it needs to be.
Analysis of business requirements will give the DBA and the system owners a more complete understanding of the recoverability their system requires. A needs assessment step can help the DBA determine the work outlay for bringing new systems online from a database administration perspective. The components of a template for determining the recoverability of a system may include the following:
| Level of service Define overall availability requirements and assign work priorities according to their impact on database availability. Identify a chain of contacts, required response, and resolution time. Create mechanisms for reporting how DBA met expectations. Agree to standards in writing. | |
| Mechanisms for change Establish an ongoing change schedule where new requirements may be evaluated. | |
| Relate to DBA goals Once business requirements are defined, align technical processes to those requirements. |
The first step forms the core obligations of the database administration team in recovering the database in the event of many different sorts of issues. While the users of one system believe their system is highly important and any problem should be resolved in half a day or less, the DBA team has to balance the needs of any single system against the data needs for the organization as a whole. Priorities must be defined for DBAs to address different production issues effectively.
An important step to have the group recognize its successes and areas for improvement is to have quantifiable standards defined. It should be looked upon as a means to communicate about the services provided by DBAs, and whether or not that service meets the original expectations. Also, it is a time to negotiate new expectations if there seem to be areas of consistent difficulty. Agree in writing to these commitments. Without agreement on standards from all entities involved in the use and support of the system, there will always be a conflict at the time of crisis. This is because each party involved will enter the crisis with a different set of expectations. Service-level agreements are as much about maintaining good business relationships and sending a message of customer service commitment as they are about meeting the standards they define.
Any agreement on the level of service provided to a database application should be though of as a "living" document. This means that periodically the standards agreed upon by all parties at production deployment of a system must be revisited. Due to staff turnover, a change in requirements, significant enhancements, or the changes in priorities inherent in most organizations, the level of service agreed upon by everyone involved with a database must be discussed and revised. The reprocessing of a service-level agreement should be treated with the same process for development as the original. The initial steps may not take as long, since the standards in many areas are not likely to change. The discussion of change is more likely to focus on the additions, revisions, or deletions to the service-level agreement. The modifications to reporting and the agreement of all parties in the end should follow through as well.
After the system requirements are laid out and the level of service is agreed upon, the DBA must plan for the worst-case—disk failure. This situation is always the worst one to encounter, for even if there is a problem with memory, CPU, or even disk controllers, ultimately the parts can be replaced. However, any loss of data has the potential to be permanent. The amount of insurance in the form of backups should relate directly to the level of importance the application has within the organization, the volatility of the data in the system, and the speed in getting the application up and running in the event of an emergency. Furthermore, the availability of certain features in Oracle can dramatically alter the requirements of users as well as the DBA’s ability to provide recoverability to applications that require 24-hour operation. Some of these features include replication of data to remote machines using snapshots and the archival of redo logs to allow recovery to the point of failure. These and other features will be considered later in this unit, as mechanisms for providing backup and recovery unfold.
There are many issues surrounding disaster recovery that are required for any computer system, including the following:
| What disaster recovery scenarios can occur on the system? | |
| What disaster recovery scenarios involve recovery from data loss? | |
| How volatile is the data stored on the system? | |
| How quickly does the system need to be made available? | |
| How does the cost of providing recovery strategy for any scenario evaluate against the cost of losing time to reenter the data? |
Computers are fragile machinery. Consider the cornerstone of any computer—the motherboard and CPU. They are vulnerable to many things, including moisture, sudden jarring movements, and dust. The amount of electricity fed to a computer is particularly important. The circuitry in a computer must be shielded both from sudden power loss and sudden power increases, both of which can cause damage. The damage these situations may cause is memory loss or damage to memory chips, or damage to the circuitry of the motherboard. Though annoying, the failure of one or more of the named components should not cause lasting damage to the applications that use the machinery unless the problem also causes data corruption on the data storage devices of the machine.
Special attention should be paid to the permanent disks used to store information on the machine. These devices are the heart and soul of the computer machinery. A memory problem may cause some trouble with the applications and the computer’s ability to run, although frequent saves to disk can reduce the chance of data loss and ultimately the memory in a machine can be replaced. What often cannot be replaced is the data that is stored on the disk drives of the machine.
Some of the most crucial decisions that can be made about disaster recovery and computer systems involve the creation and execution of procedures to obtain backups of hard disks to the frequency they are required. The processes created to take those backups should be designed to provide the recoverability that is required based on the needs of the system. For example, the frequency of backups required for support of a rapid recovery for a system that experiences a high rate of data changes would be higher than the need for backups on a system that experienced infrequent data changes and ran only once a month. Some other features for providing rapid uptime for users in the event of a disaster center around replication or mirroring of components of the database system or, in certain cases, the entire database system. If the availability of a computer system is critical to the operation of the organization, then the organization may want to consider the advantages of having a duplicate system available for use in the event of production system failure.
Providing adequate backup strategy for every situation involving any type of failure depends on the cost of losing data in a situation versus the cost of ensuring data is not lost. With enough planning and an eye on cost, it is possible to develop strategies that ensure data recovery in all but the most confounding or overwhelming situations. However, the cost of the solution provided should relate directly with the cost of the loss in the first place. It would be nice to provide daily backups to tape, which are then replicated and delivered to an offsite location for warehousing. It may also be great to have a full replica of the system waiting for the need to arise for its use. The reality of most organizations, however, is there is neither the money nor the staff to maintain this option for every system. Furthermore, with careful planning, adequate results can be attained for far less money.
As with many other decisions an organization must make, the managers of an organization should be involved with the final determination of backup needs for the database applications used in the organization. Ideally, there should be management involvement in the task of defining the service-level agreement from beginning to end, so that the managers of an organization will properly assess each recovery situation as it arises. Managers often act as the best liaison for users and the DBA, although no DBA should ever be afraid of fielding their own support questions. With a proper understanding of the capacity and limitation of the backup strategy developed to handle a database application, the manager of that application can work in conjunction with all parties involved to ensure that all users’ needs are met in disaster situations.
Nothing is worse than taking the hard work of many people to develop good plans for database backups and squandering it by failing to perform system tests to determine if the plan is adequate for the needs of the application. A good backup strategy accommodates user errors, too. The overall strategy is meant to ensure full recoverability of a database in the event of a complete system failure. The DBA shouldn’t shy away from an array of options available to obtain supplemental backups during periods of high activity or when the DBA suspects there may be problems. Added backup coverage provides a value-added service that achieves additional recognition both for the DBA and for the entire IT shop. The ideal test plan consists of several areas, including a set of test case scenarios, the steps to resolve those scenarios, and a set of criteria to measure the success or failure of the test. Only after the initial test plans are developed and executed successfully should the DBA consider implementing the backup strategy in production.
The testing of a backup strategy should not stop once the database sees live production activity, either. Good backup and recovery testing involves both formal reworking and periodic "spot-checks" to ensure that the strategy meets ongoing needs. As the focus of a database matures, so too should the backup strategy. When changes to the service-level agreement are made, the backup strategy should be tested to ensure that the new requirements are met. If they are not met, then the strategy should be rethought, reworked, and retested. However, as the DBA considers taking out some added "insurance" with special backups, the organization may also want to contemplate the power of random "audits" to ensure that the systems supported can be backed up adequately in a variety of different circumstances.
Testing backup strategy has some other benefits as well. The testing of a manual backup strategy may uncover some missing steps from the manual process, and may prompt the DBA to consider automating the backup process as well. There is no harm in automation as long as the process is tested and accommodates changes that occur in the database. Otherwise, the automated scripts will systematically "forget" to save certain changes made to the database, such as the addition of tablespaces and datafiles after the scripts are created.
Another benefit to testing the backup strategy is its ability to uncover data corruption. If one or several data blocks are corrupted in a datafile, and the physical database backup method is used for database backup, the corrupted data will be copied into the backups, resulting in backup corruption as well as corruption in the database. There is no way to verify if this is happening if there is no testing of the backups created, so the only time a DBA will discover that the backups contain corrupted data is when it’s too late. Systematic data integrity checks can be accomplished with the DB_BLOCK_CHECKSUM initialization parameter and the DBVERIFY utility, both of which will be discussed later.
In this section, you will cover the following topics related to backup methods:
| The difference between logical and physical backups | |
| Mechanics of a good backup | |
| Implications of archiving or not archiving online redo logs | |
| Backup and recovery in round-the-clock operations | |
| Time requirements for recovery | |
| Time requirements for backup | |
| Transaction activity level and backup/recovery | |
| Backup and recovery for read-only tablespaces |
Several methods exist for taking backups on the Oracle database. Some are handled internally using Oracle utilities and features. Others rely on the use of external or operating system-based mechanisms. The needs of a system also determine what methods are incorporated or recommended for use by Oracle. This section will discuss the use of various methods for backing up the Oracle database, along with their limitations and requirements.
There are two types of backup available in Oracle: logical backups and physical backups. The two types of backups available in a database correspond directly to the two views of the database presented in Unit II: the logical view and the physical view. The logical database export consists of performing an export of the individual database objects available in an Oracle database. Oracle provides a utility for logical export of database objects and users called EXPORT. When EXPORT is used to create a backup of database objects, the backed-up copy of information is placed in a file called the dump file. A complementary application called IMPORT is designed to bring the information out of a file created by EXPORT, either into the database from which the objects were exported or into another Oracle database. Note that the format of the export dump file is compatible with the IMPORT utility only. There is no other way to use the files produced by the EXPORT utility.
Physical backups rely on the use of the operating system to copy the physical files that comprise the Oracle database from an operating system perspective. Further, for the application to incorporate changes to the database that weren’t written to the database, the use of archived copies of the online redo logs must be used to ensure that appropriate changes are made to ensure a recovery up to the moment of failure. An example of the changes that exist in the instance that may not have been written to file are the changes to data blocks that are sitting in the dirty buffer write queue waiting to be written to disk as part of a checkpoint.
When deciding on a backup strategy, the DBA should bear in mind the uses for the database application and the amount of maintenance required for the backup strategy vs. the impact of lost data from the system. In general, however, it is recommended that logical backups of data in the database NOT be the primary method for ensuring that a backup exists on the database. Instead, it is recommended that physical backups of the files that comprise the Oracle database, namely datafiles, log files, control files, and parameter files, in conjunction with the archiving of online redo log files with the archivelog option, be the preferred method of backup in the Oracle database. This recommendation is made because physical backups and use of archivelog mode allow the DBA many more options for recovery than simple logical backups. A logical backup allows for recovery only up until the point in time that the last backup was taken. In contrast, the DBA can recover a database up to the point in time of database failure when using physical database backup in conjunction with the archivelog mode.
Crucial to both a logical and a physical backup is the importance of getting data off the disk or disks that are used all the time by the database and onto some external storage media, such as magnetic tape, optical drive, or even another machine. If, for example, the DBA is taking copies of datafiles and backing them up on a different directory of the same machine, then the DBA may as well not take backups at all. Consider the impact of a disk crash in this scenario—if the disk crashes, it will take both the production file and backup file with it.
First, regardless of whether or not the DBA operates the backup process manually or via the use of automated scripts, the DBA should have an intimate knowledge of the environment in which the database resides. In host system environments that use filesystems, this means that the DBA should know all the directories that the Oracle database uses in their setup, and the names and contents of each file used in their Oracle database. If need be, a map of the filesystem may be useful. Also helpful for taking backups is the use of the V$DATAFILE, V$CONTROLFILE, and V$LOGFILE performance views to determine the names of the datafiles, control files, and online redo log files, respectively.
Second, the DBA should be aware of the sequence of events that must occur in order for a good backup to happen. Each type of backup performed in the Oracle database environment requires a series of events that must happen in a certain order. If things happen out of order, then the integrity or utility of the backup may be compromised.
Finally, the DBA must know how to handle a system problem that arises during the process of database backup. The database can fail anytime, including the time a DBA is attempting to perform backups. With the knowledge of how to handle errors during backup, the DBA can ensure that the database remains recoverable in spite of the error.
There are several different types of backups available to the Oracle DBA. These options are used in the backing up of a database, depending on the business needs of the system. In the following section, several case studies are presented to illustrate each type of backup available. The list of backup options available as of Oracle7 are as follows:
| Logical export | |
| The offline backup | |
| The online backup |
Logical export should be done outside of normal business hours to minimize impact to online database processing. The logical export of a database requires the DBA to first consider the effects of read inconsistency, the degree to which data involved in the transaction is unchanged by any transaction other than this one, from the start of the transaction to the finish. This is not a condition of logical export. Instead, the export reads data from each object in the database in turn to replicate its data in a binary file stored in a location defined by the EXPORT command-line parameters. For best results with EXPORT, use the following steps:
Remember that logical backups are good for recovery to resolve user error, such as the accidental removal of a database table. However, one major limitation of the logical backup process is that they do not use archived redo logs. As such, they do not present a good solution to recovering a database to the point of failure unless a backup was taken just prior to failure. In other words, the DBA can only make recovery on the database with logical backups up to the point in time that the last backup was taken. Figure 11-2 shows the database view of a logical export.
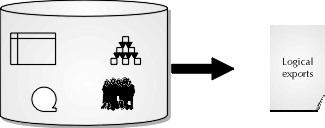
Figure 2: Database view of logical export
A cold physical backup consists of backing up the database from the operating system perspective. Since the Oracle database consists of several different files that reside in an operating system, it stands to reason that saving those files and storing them in an alternative storage form would be a viable alternative to the logical storage option. However, the physical database recovery model offers more options for success in producing backups for active database systems--databases with high-volatility database changes that can afford the downtime required for backups offline.
Redo logs should be archived with physical backups. More information about the implications of archiving and the methods for turning archiving on is detailed later in this chapter and again in Chapter 13. From the discussion of redo logs in Unit II, you know that the redo logs store every transaction that was entered into the database. Each transaction is assigned a system change number (SCN) for the purposes of tracking the change in the rollback segment and the redo log. Once committed, Oracle stores the SCN in both places, along with a message saying this transaction is committed. When archived, the online logs are stored in the archive destination specified by the init.ora parameter LOG_ARCHIVE_DEST. The physical database backup the DBA creates is only the first step in ensuring a recovery of committed transactions up to the point in time of failure. The successful application of data in the archived redo logs allows the DBA to insert the supplemental changes that happened on the database after the backup took place.
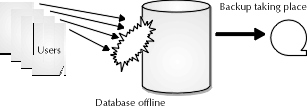
Figure 3: Cold physical backups and the operating system
To ensure that all data is captured in an offline backup, the DBA should close the database using the shutdown normal or shutdown immediate statement, then begin the offline backup process. Archived redo logs that currently reside in the disk location are stored to tape if archiving is being used. All the files of the database that store application data are then copied and archived using the methods for file copy made available by the operating system. The following bullet points list the types of files that must be archived in order to restore the database:
| Datafiles Store the tables, indexes, rollback segments, other segments, and data dictionary. | |
| Redo log files Store the nonarchived redo log entries of the database. | |
| Control files Store the physical-to-logical database schema translation and location information. | |
| Parameter files Also called init.ora, stores all parameters used for database instance startup. | |
| Password files Store passwords for DBAs allowed to connect to the database as SYSDBA. |
The DBA should back up the copies of the datafiles, online redo log files, control files, password file, and parameter file to another disk, if possible, to improve recovery time. However, allocating enough space for a copy of all the files associated with a database may be difficult, especially for large databases. Ideally, however, enough space can and will be allocated to store all files on disk first, so that the backup can complete before the files are then transferred to alternate storage media such as tape. The DBA will see the best backup performance if there is enough space to store a copy of all backed-up data on a disk, then start the database to make it available to users again.
The offline backup by itself presents a good solution for minimal point-in-time recovery on database systems that the organization can afford to allow downtime on. When used in conjunction with archived redo logs, however, the recovery options for offline backups multiply to include recovery to virtually any point in time from the time the offline backup took place right up to the point in time the database experienced disk failure, and any point in time in between.
In globally deployed systems that require a range of availability for all hours of night and day corresponding to users in other areas of the world, the cold offline backup may not be possible. The organization may simply not be able to allocate enough time per week to allow DBAs to take the database down in normal mode. A shutdown normal process can be time-consuming, as it requires the DBA to wait until the last connected user logs off before completing the shutdown routine. As an alternative to be used in support of global operations that require round-the-clock online access, the DBA can use Oracle’s online backup method, illustrated in Figure 11-4.
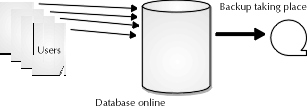
Figure 4: The online approach to database backups
The hot online backup is an iterative process that creates backed-up copies of the database, tablespace by tablespace. Whereas in the two previous options a clear distinction was drawn between exports that take the logical view of the database (EXPORT) and backups that take the pure physical view of the database (offline backups), the online backup requires a hybrid logical-physical approach. In order to execute a hot backup, the DBA must execute a command within Oracle Server Manager that prepares the database for the hot backup. The command is the alter tablespace name begin backup command. An example of the command syntax in action appears in the following code block:
ALTER TABLESPACE data_01 BEGIN BACKUP;
Once this command is issued, the DBA should immediately go to the operating system prompt of the machine hosting Oracle and make a copy of all datafiles associated with the tablespace. For example, if tablespace DATA_01 has five datafiles, called data01-1.dbf through data01-5.dbf, then after the logical database command statement in the code listing above has been executed, the DBA must switch to the operating system and make a copy of the five datafiles associated with the index. Once complete, the DBA should switch back to the logical database view of Oracle and issue the command listed in the following code block from within Server Manager:
ALTER TABLESPACE data_01 END BACKUP;
Once one tablespace is backed up, then the DBA can move on to the next tablespace that will be backed up. However, there is no requirement to do so. Since each tablespace is backed up independently of one another, the DBA can formulate a practice of incremental tablespace backups or back up all database tablespaces in their entirety.
The online backup approach offers the DBA a distinct advantage. A complete copy of all tablespaces in the database can be obtained without shutting down database operation. This fact allows 24-hour databases the same power to back up their data as those databases that can experience downtime.
The use of online backups adds some complexity to the business of making backups in that online backups required the use of archived redo logs in order to preserve the integrity of changes made to a tablespace while the backup takes place. Remember, the database is open, available, and accepting changes during the entire time an online backup is taking place. In order to guarantee that the changes made to the tablespace while the backup took place are kept, it is required that the DBA archive redo logs that were taken during the operation of hot backups. Prior to taking the hot backup, the DBA should issue the archive log list command from Server Manager in order to determine the oldest online redo log sequence that should be saved in conjunction with the online backups being taken. Once the tablespace backups are complete, the archive log list command should be issued again, followed by a log switch to ensure that the current redo log entries made for the tablespaces backed up are archived properly for use by the backups should recovery be necessary. The steps to the process are listed below:
Redo logs store every transaction that was entered into the database. Each transaction is assigned a system change number for the purposes of tracking the change in the rollback segment and the redo log. Once committed, Oracle stores the SCN in both places, along with a message saying this transaction is committed. The redo logs are an ongoing list of system change numbers and database changes. When archived, the online logs are stored when they are full to another location in the database, specified by the init.ora parameter LOG_ARCHIVE_DEST. The physical database backup the DBA creates is only the first step in ensuring a recovery of committed transactions up to the point in time of failure. The successful application of data in the archived redo logs allows the DBA to insert the supplemental changes that happened on the database after the backup took place.
Archiving of redo logs should be used in any production database environment where data changes are frequent and complete recovery to the point of failure is required. With archived redo logs, the potential options for database recovery are enhanced because the data changes recorded by redo logs can then be applied to the most recent backup to allow for all the committed changes that have been made since that backup to "roll forward." A roll-forward is when Oracle applies all the uncommitted changes that are stored in the redo logs to the database. Once this step is complete, Oracle then rolls back to eliminate the uncommitted changes from the database. Figure 11-5 shows the Oracle redo log architecture.
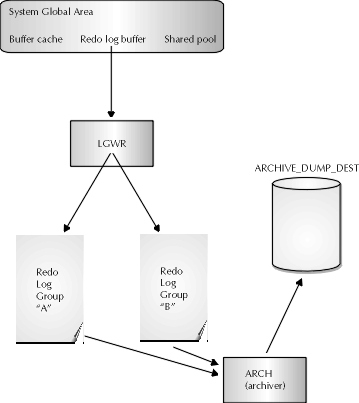
Figure 5: Oracle redo log architecture
Without the archival of online redo logs, the data changes for a database are lost every time a log switch occurs. To understand why, recall the process used to write online redo logs. There are at minimum two redo logs available in the Oracle database at any given time. Each redo log may consist of one or more members, or copies. Ideally, the online redo log members are placed on multiple disks to minimize the Oracle database’s dependency on any one disk. If a disk drive fails that contains the only member of the current online redo log, the Oracle instance will fail. Needless to say, it is important to ensure that the instance doesn’t fail because of the loss of a disk containing the online redo log. The cleanup process will necessarily be incomplete if this situation occurs.
When an online redo log fills, a log switch occurs. Remember that several things happen during a log switch. First of all, if archiving is enabled and the DBA has issued the archive log start statement from Server Manager or set the LOG_ARCHIVE_START initialization parameter to TRUE in the init.ora file, then the online redo log will be archived automatically by ARCH. If only archiving has been enabled, the DBA may have to archive the redo log manually. The LGWR process will also start writing redo log entries to the other online redo log.
Though not strictly related to archiving, a checkpoint will also occur during a log switch. A checkpoint is a point in time where the LGWR process issues an order to the DBWR process to flush the dirty buffer write queue of the database buffer cache in the SGA. Also, either LGWR or CKPT writes the new redo log sequence number to the datafile headers and to the control file. Flushing the dirty buffers means that DBWR will write the data changes made to database blocks in the buffer cache out to the datafiles on disk that contain copies of the blocks. These are the processes that comprise a log switch.
The data in the online redo log is always considered "junk" after the log switch. When the LGWR fills the other redo log, it will switch back to the first one and start overwriting the data changes made to the redo log prior to the switch. If the redo entries are not archived, then the redo log entries will be lost time and time again as the log switches cause Oracle to overwrite the data changes. This redo information is very useful for providing the DBA with many recovery options and should be archived wherever appropriate. The situations where archiving redo information is appropriate include any database that requires recovery to the point in time of the problem--where the cost of having users reenter lost data as part of database recovery outweighs the additional effort required to maintain archived redo information. As one can see, archiving redo logs is an appropriate option for all but the smallest databases in use within an organization.
Situations where archiving is not required include read-only databases or databases that experience a low frequency of data changes. Databases in this category may be better off using the logical backup option. For example, if it is known that a database will change only when a batch process feeds data into the system once a week, the simplest option that provides comprehensive backups for use in recovering this system is to make a backup of the database after the data changes are made. Either the logical backup approach or the offline backup will work to store the data changes made after the batch processes that update this type of system. This approach provides the needed recoverability for the system as well as requiring only nominal effort and maintenance on the backup process by the DBA. Some database types that may fit into this model include data warehouses or decision support systems.
However, any type of online transaction processing system may not be able to predict the volatility of its data in the same way that a system relying mainly on batch processing to create data changes would. In support of these online systems, Oracle recommends archiving redo logs. By saving all the data changes made to the database with the use of archived redo logs, the DBA can recover all committed data changes to the database with minimal requirements for end users to reenter data they may have placed into the trust of the database environment.
The requirements of round-the-clock databases have been mentioned in a few different areas of this chapter already. In many large organizations, the requirement that a system be available at all times is becoming more and more common. This fact holds true even for systems depending on a database that is not deployed to a global user base. The reason 24-hour operation is such an important requirement to many organizations has as much to do with batch processing as it has to do with the globalization of many businesses. In many environments, there is an entire fleet of database tables that contain validation information for applications. For example, assume there is a database that supports several applications for the human resources organization of a large company. This database contains tables that are updated daily via online users. The applications depend on an infrastructure of database tables that contain validation information such as an employee’s name, organization ID, salary, start date, and address. In addition, there may be several other tables in a database that support and store validation data for any number of different reasons. Typically, this validation information is not subject to change by the applications that use the data. This doesn’t mean, however, that the data never changes. For example, employees enter and leave a company all the time. The employee validation information needs to be updated for other applications that may have data populated in them on the basis of that new employee. Hence, some new data must be brought into the database on an ongoing basis. This ongoing basis is handled via batch processes. It is usually recommended that batch processing occur during time periods where few users are likely to enter data to an online application so that neither the user nor the batch process will have to share hardware resources with one another. An organization may have dozens or hundreds of batch processes that move data from one place to another, requiring several hours’ processing time per night. Thus, even a suite of applications that are deployed to users in one area or country may still require 24-hour availability to handle all batch processing overhead associated with providing valid value information to the database applications.
However, systems that are deployed worldwide are even harder to support. Since the worldwide user base may log in to create transactions at any given time, there really is no specific time the DBA can earmark as available for online processing and another time for batch. These systems typically require hardware that offers enormous processing power in order to handle database transactions for both users and batch processes at the same time. The data integrity issues these systems present can baffle even the brightest DBAs.
Consider, for example, the situation where the database has users entering information for an application associated with an employee who is an active employee according to the database at the time the data is entered. The data entry takes place at 2 p.m. Pacific time. The application that the data is entered for has a batch process called "X" that occurs at 5 p.m. Pacific time that will only process data in this application for active employees. However, another batch process called "Y" comes along at 7 p.m. Eastern time that changes the validation data for employees. This process Y changes the employee for whom data was entered at 2 p.m. Pacific time to inactive. As a result of the change made by process Y, the application batch process X will not process the record for the employee entered at 2 p.m. because the employee is not active, even though the employee was active at the time the data was entered. This example is displayed graphically in Figure 11-6, and demonstrates the importance and difficulty of determining the beginning and end of a "business day" in terms of when batch processes will update valid values.
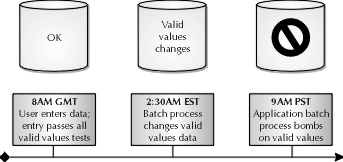
Figure 6: Importance of synchronicity in 24-hour databases
The difficulty of 24-hour operations extends into the world of backup and recovery as well. For a database that expects online usage during a certain period of time but requires 24-hour availability due to the need for extensive batch processing to support the validation data used to preserve data integrity in the face of online transaction processing, identifying time to perform backups is easy. The backups for this type of database should be scheduled during the same time as that allocated for batch processing. Usually, a few hours are identified in the business day, possibly early in the morning or late at night, where database activity is low. At this time, the DBA may schedule hot online backups to occur, or, alternately, could shut down the database and take an offline backup. Hot backups present the best option because they allow the database to be available on the errant chance that a user may still be working with information in the database. The overall effect of scheduling hot backups during lulls in database activity is to limit the amount of redo information that must be applied to a backup, to place committed changes into the database that were made while the backup was being taken.
Using the logical backup strategy is usually not effective in 24-hour operations or for online transaction processing systems, mainly because of the volatility of the data changes. Since exports cannot be used in conjunction with archived redo information, there is no way to enact database recovery past the last point in time a logical backup was created. However, logical backups can be used for supplemental backups of individual database objects or for the recovery of a dropped object in certain cases.
The difficulties faced by backup and recovery strategies are compounded by the requirement of an application to be available 24 hours a day for online usage as well as batch processing. The same problems related to scheduling batch processes are in effect for backup and recovery. The solution with respect to obtaining good database backups is solved partially with the use of hot online backups to enable the database to be available during the backup period. The size and number of redo log entries that must be applied to a hot backup may be high or low, depending on the level of transaction activity during the time the backup is taken. It is worth determining when the database is least active in terms of online and batch processing in this situation because the fewer the number of redo logs that need to be applied to a backup, the less time that will be spent waiting for the files to be restored from tape.
However, recovery in a 24-hour operation is another story entirely. Since the expected availability of a database system is all the time, the success of recovery of a 24-hour database is not simply based on the complete recovery of all data affected by the failure of the database. Time is also a consideration. Since users all over the globe will wait no matter what time it is, the DBA must be prepared to handle the recovery of the database at all times, in the shortest time possible.
There are many methods of database administration designed in order to improve the speed for recovery as well as the complete restoration of data into the database. Two of the various options used to minimize the recovery of a database in 24-hour operations include relating the frequency of a backup to the frequency of change experienced by the objects in the database and using a standby database. These two options can provide speedier recovery in different ways.
By backing up areas of the database that are updated more frequently, the DBA minimizes the recovery time required. More frequent backups minimize the number of redo logs that must be applied to the backup to bring the data in the database current to the point in time the database failure occurred. If full database backups occur infrequently, then many archived redo logs must be applied to the database in order to make current the database changes to the point in time of the failure.
The standby database provides faster recovery in another way. A standby database allows for almost instant recovery of a database by using additional hardware, along with data replication, to create a second copy of the database on another machine. When failure occurs, the DBA can switch users to the standby database for the period that the original database must be recovered. Although standby databases sound great in concept, the actual management of a standby database can be tricky. A more complete discussion of use for standby databases will appear in Chapter 15.
As long as there are backups of the database files, along with archived online redo logs, it is usually possible to recover the data right up to the last commit issued before the crash. However, the time it takes to achieve that level of availability can become an issue in and of itself. The general rule of thumb is the more time the database is expected to be available in the course of a day, the more pressure the DBA will be under to recover data in the event of a system crash. To improve recovery time, the frequency of a backup should be related to the frequency of change experienced by the objects in the database. Recovery time can also be minimized with a standby database.
Frequent backups minimize the number of redo logs that must be applied to the backup to bring the data in the database current to the point in time the database failure occurred. If full database backups occur infrequently, then many archived redo logs must be applied to the database in order to make current the database changes to the point in time of the failure. More frequent backups should be considered if the database experiences a high degree of data change in certain areas. The frequency of backups can be broken down to the tablespace level for those DBAs who use hot backups as well. By backing up the database one tablespace at a time, the DBA may find it useful to back up tablespaces whose data is frequently changed. In addition, the DBA may want to back up tablespaces containing rollback segments in databases experiencing high transaction volumes.
The standby database provides faster recovery in another way. As discussed, a standby database allows for almost instant recovery of a database by using additional hardware along replication to create a second copy of the database on another machine. When failure occurs, the DBA can switch users to the standby database for the period that the original database must be recovered. Although standby databases sound great in concept, the actual management of a standby database can be tricky. In general, the use of a standby database is expensive and challenging. Although it certainly has its place in database backup and recovery, care should be taken in order to ensure that the DBA manages standby databases properly. A fuller treatment of the standby database appears in Chapter 15.
Backing up the database has its own time implications as well. The length of time a backup may take need not be considered "lost time" in terms of productivity of availability of the system, as has already been established. However, each style of backup has its own time considerations, as will be presented shortly.
Consider first the time requirements of the logical backup. In order to obtain a logical backup, the database must either be open to all users or set into restricted session mode, whereby only users with the restricted session privilege may access the database. Presumably, the user that connects to Oracle to take the logical backup, either a person at a terminal or a batch script, will have this privilege.
It is recommended that the restricted session option be used when backing up the database using the logical options presented by the EXPORT utility. The reason for this recommendation is because of EXPORT’s biggest time implication—for the period of time the EXPORT is taking place, there is no guarantee of read consistency for the entire export. Due to the method Oracle uses for exporting data, the EXPORT utility does give read-consistent views of the data in each table while the read takes place; however, the same ability is not given across tables. Thus, if the DBA has a set of tables to back up using the EXPORT method, and users have access to the data, there is a chance that data can change in one table while the backup is saving another. Once the data export is complete, the utility will not go back to find data that may have changed while the export was running. In effect, even though the data may have changed in the table, there is still not guarantee that it was backed up.
The time implications involved with the use of EXPORT are important for the DBA to consider when scheduling and designing backups. Time impact is twofold. First, during the period of time the export takes place, the DBA should consider disallowing the users’ access to the database so as to provide a read-consistent view of all objects backed up. The time trade-off with this option is that for the time the backup is taking place, the users may not access the database. The second trade-off is that if user access is not disallowed, then the data in the export may not be useful. It is conceivable that since there is no read consistency between database objects as the export takes place, if a user inserts data into a table after the data was exported, the row would not appear in the table but it would appear in the index.
Second in consideration to logical backups is the fact that the more infrequent the backup, the more time that will be required for data reentry into the database system. It has been mentioned that the logical backup is only capable of restoring the data in a database to the point in time the last backup was taken. If, for example, the last export of a database was taken at 2 a.m. on a Tuesday and the database crashed on Wednesday at 4 p.m., then the DBA will only be able to provide restoration of data to the point the export took place at 2 a.m. Tuesday. Thus, the users of the database will be required to redo work on their own time.
Physical backups have their own set of time considerations as well. An offline backup must take place while the database is closed. The first time implication for offline backups is that the backup must occur when users are not likely to be on the system. As with logical backups, this time period may be late at night or on weekends, provided that the database system does not have 24-hour availability requirements due to global user base and/or extensive batch processing.
The second fact is that for the period of time the offline backup takes place, no user may access the database system. Period. This fact is due to the database being offline while the backup takes place. Although logical backups have a similar recommendation that the database be in restricted session mode for the period of the backup to ensure read consistency, the offline physical backup must take place when the database is down. Therefore, the users of the database must necessarily be willing to accept downtime as part of the backup process.
Finally, in the event of a disaster, as with logical export backups, the physical offline backup will only restore data to the point of failure if database archiving is not used. In this situation, the users will be required to take time to redo their database work from the time the backup occurred to the time the failure occurred. It should be said at this point that the cost of recovery in the situation where users’ changes are not restorable to the point in time of the database failure could grow quite costly. Even though it may take several hours to apply redo log entries onto the restored database on top of the time it takes to restore the database itself, during that time the users may be able to salvage their own productivity by doing something else until the system is available. However, if the database is available and several users must accomplish a day’s worth of work to recover their own data changes (for example), then the users of the database have definitely lost time. The time loss suffered by each user, when translated into an hourly rate times the number of users who suffered the time loss, can add up to a scandalously large soft cost paid by the company to restore a database. As such, Oracle strongly recommends the use of archiving in conjunction with physical backups for any shop that must have data recovery to the point in time a failure may occur.
The final backup option whose time implications will be considered is the online backup method. As mentioned before, this option requires the use of archiving in order to obtain the data changes made to the tablespace during the online backup period. The time implications with this form of backup basically amount to showing how forgiving an online backup really is. During the period that the backup occurs, the database can and should be available for the use of any users to insert, select, update, or delete data from the tablespace being backed up. This option is designed to support 24-hour availability on a database.
The main time implication of online backups, however, is the time to recover using them. The recovery process when using archived redo logs is twofold. First, the DBA must apply the backup to the database in order to restore the database to the point in time the backup was taken. Then, in order to restore the database to the point in time that it failed, the DBA must apply the archived redo logs. This two-step process can be time-consuming, depending on the number of archived redo logs that need to be applied. If backups are infrequent and the redo logs large and many, then recovery will take a long time to accomplish. If backups are frequent and the redo logs small and few, then the same amount of data recovery will take less time.
In order to avoid the time implications created by online hot backups, the DBA should schedule the backups as frequently as possible without incurring excessive overhead on the database during peak hours of usage. A deeper discussion of the implications of large and voluminous archived redo logs and some potential causes for this situation will be discussed shortly.
It is not difficult to ensure that the database can have all its data restored up to the final committed transaction just prior to system failure. The difficulty starts when trying to perform said recovery in the rapid manner demanded by most online applications. To boot, the business situations that make DBAs opt to use archiving in the first place are often the same business situations that put the most pressure on DBAs to provide a rapid recovery. Often, the situation gives rise to a paradox—does the DBA emphasize recoverability of data at the expense of recovery performance, or does the organization have to suffer the potentially poor performance of a complete recovery for the sake of recovering all its data?
The size and number of redo logs that will be required for an Oracle database recovery in the event of an emergency correlates directly to two factors. The first factor is the amount of transaction activity. The number of redo logs that are generated and required to support recovery from the last backup to the most current redo log is in direct proportion to how long ago the last backup was made and how high the transaction activity has been on that tablespace since the last backup. A general rule of thumb is the higher the transaction level, the more archived redo logs that will be generated. The size of a redo log is set by the parameters specified for the database at the time a database is created. For more information about the size of a database, refer to the discussion of creating databases in Unit II.
The second factor is the frequency of the backups. Once a backup is taken, all the data in a tablespace at the moment in time the backup takes place is recorded in that backup. Any archived redo logs that were required to get the database to the point of the backup from a previous backup are no longer required for that point-in-time recovery. Generally speaking, the more frequent the backup, the fewer the number of redo logs that will be required by the DBA for purposes of recovery to the point in time of failure.
Transaction activity makes more or fewer redo entries, depending on how much activity the database is seeing. For example, on a database that infrequently experiences weekend activity, there will be fewer redo log entries, and thus fewer redo logs, that are produced during weekend activity. At peak periods of usage, however, when the users are adding data to the database frequently, the redo logs will grow rapidly.
In general, larger and more numerous archived redo logs coupled with infrequent backups produce longer recovery times than fewer, smaller redo logs coupled with more frequent backups. Fortunately, there are recovery alternatives that may be faster to execute. It is beneficial for the DBA to back up the database more frequently during periods of high transaction activity. This will enable the DBA to use fewer archived redo logs during database recovery to produce the same recovered data in less time. Another practice commonly applied by DBAs who are using online backups is to back up the most frequently used tablespaces most often. Since online backups are accomplished tablespace by tablespace, the DBA can easily pinpoint database objects for backup that are updated frequently by consolidating placement of those objects into tablespaces earmarked for frequent backup. The recovery of those frequently updated database objects is more convenient in the event that the disk storing those tablespaces fails.
This approach also works for those tablespaces that may not be as frequently changed. Since the changes to a tablespace may not be frequent, a large number of archived redo logs to apply may not contribute as heavily to the recovery time required for infrequently updated tablespaces. This fact is due to the existence of few redo entries in each of the archived redo logs. So, each redo log that is applied to the infrequently changed tablespace may run quickly due to the fact that there aren’t many redo entries in the log to apply.
The transaction activity level will adversely impact database recovery in databases that do not use archiving as well. More frequent backups should be used when the database relies on logical backups or offline backups. Since these methods only afford the DBA the opportunity to make recovery to the point in time the backup occurred, it makes sense to back up data frequently to minimize the amount of effort the users will have to reapply to the database in the event of a database failure.
Unfortunately, in nonarchiving situations, more frequent backups require more time—during which the users will not be able to add or change data in the database. In reality, it may not be possible to accomplish these nonarchiving backups more often than once a day, which means there is always the possibility that users will lose at most one day’s work plus recovery time. Especially on databases with high transaction activity, Oracle recommends archiving the redo logs in order to provide recovery to the point in time of the failure.
Drawing on the points made about backup needs for less-frequently changed database objects, there are special considerations that should be made for backup on the least-frequently changed database objects. In cases where special "valid values" data is kept in lookup tables on the Oracle database, the tables that contain this data can be placed into special tablespaces called read only tablespaces. These tablespaces in the database are precisely that—the data in the tables of a read only tablespace may not be changed.
Data that is read-only in a database represents the easiest effort in terms of DBA maintenance and backup for the sake of database recovery. In situations where database data is defined as read only, the DBA needs to back up the read only tablespace once for every time the data changes. The mechanics of setting a tablespace to read only status is covered in Unit II. Once the tablespace is read only, the DBA can rest assured that the data will not change. As such, repeated backup is not necessary. The data in a read only tablespace needs to be backed up only once.
This chapter covered several areas of introduction to the business of backup and recovery on an Oracle database. The two topic areas covered in this chapter include the backup and recovery motives in Oracle and the backup methods in the Oracle database. Together, these topics comprise 17 percent of the OCP Exam 3 test content.
The first area covered in this chapter is backup and recovery motives. The DBA must remember that the data in a table cannot be recovered without backups. This is the critical nature of backups for recovery purposes. When determining the setup for a backup schedule, the DBA should keep several things in mind. First, the nature of business for this application should be remembered. Is the application meant for online transaction processing situations, where several thousand users are entering data daily? If so, then the backups taken on that type of system should reflect the volatility of the data being stored. On other systems, where data may be fed to the database on a batch schedule such as in the situation of a data warehouse, backups may be required only after said batch processes update data. This may true because after that time, the database is primarily available on a read-only basis to its users. The point being made here is that the backup and recovery strategy must be tied very closely to the overall objectives of the database being backed up.
Disaster can strike any computer system at any time. Some of the implications of disaster recovery for any system include data loss, reduced productivity for users while the computer system is recovered, and hardware costs for replacing missing or destroyed server and/or client components. Other costs to the computer system include the time it may take to manually reenter data that could not be recovered automatically due to the absence of backup components. Any or all of these issues may be deemed acceptable by the organization, depending on whether or not the organization is risk-taking or risk-averse. However, as with most decisions in organizational settings, management should be involved and ultimately responsible for making the hard decisions about backup and recovery. Oracle supports many options that can provide a high level of recoverability for database data. However, many of the options, such as backup archiving offsite or a standby database, have premium costs attached to them. Having as many options as possible at the DBA’s disposal is important, but so is the cost of providing those options.
One final area of importance when considering the motives for backup and recovery is to test the backup strategy to ensure the success or failure of the strategy before a problem occurs. Testing backup and recovery in the organization accomplishes several goals. The first goal accomplished is that the overall strategy can be observed in several different scenarios to determine if there are flaws or weaknesses in the plan. The bonus of testing the plan is also that the plan can be remodeled in a noncritical atmosphere, with little or no consequence regarding the loss of data and subsequent frustration of the organization with its DBA. The second important consequence of periodic testing of the database backups relates to the use of physical backups. Testing backups allows the DBA to determine if there is some sort of subtle data corruption in the physical database files that is being copied into all the backups, rendering them as defective as the production database. Finally, testing the backup and recovery strategy allows the DBA to develop expertise in that area, which offers the benefit of the DBA developing well-tuned backup and recovery.
Overall, the success of a recovery is not only dependent on whether or not all data can be restored successfully. The true victory in database recovery is won when the DBA can restore all data successfully and quickly, so as to minimize the overall strain a database failure poses to the organization.
Backup methods is the other major area of concern covered in this chapter. The first discussion in this section identified differences between logical and physical backups. The first difference between physical and logical backups is based on the two fundamental viewpoints a DBA has on the information stored for the Oracle database on disk. From the logical perspective, the disk contains tables, tablespaces, indexes, sequences, and the like. The logical backup supports this viewpoint by allowing the DBA to handle the backup entirely within Oracle, at the level of tables, indexes, sequences, users, and the like. The tool in Oracle used to support logical backups is the EXPORT tool. The other perspective of Oracle disk usage is the perspective of the operating system. Oracle stores data in files that look the same from the operating system as other files. This is the physical view of the database. Backups from this perspective consist of copies of the files that comprise the Oracle database.
Logical database backups can be taken with the EXPORT utility provided with Oracle. Good exports start with the identification of low usage times on the database, times that are suitable for exporting data. Ideally, the users are locked out of the database by the DBA enabling the restricted session mode. With the users locked out of the database, the DBA can ensure that the backup made is a read-consistent view of the database at the point in time the backup is made. The proper steps for executing a backup with the EXPORT tool are detailed in Chapter 13. After the logical backup is complete, the database should be opened for general use by disabling the restricted session mode.
Physical database backups are divided into two categories—offline, or "cold" backups, and online, or "hot" backups. Cold backups may only be accomplished by the DBA when the database is closed, or unavailable to users. The database must be shut down using the shutdown normal or shutdown immediate statements. If the shutdown abort options are used to shut down the database, the next time the database is opened, Oracle will attempt instance or media recovery, respectively. Shutting the database down in normal mode is the method used to avoid this problem. Only when the database is closed normally is the DBA assured that all changes made to data in the database that may still be in memory have been written to disk. Once the database is closed normally, the DBA can begin the process of taking a complete copy of the physical database files in the database. These files are generally of four types. The four types are datafiles, control files, redo log files, and parameter files. Only full backups of the database are available with offline backups; it is inappropriate to back up only a few of the datafiles in this situation. To obtain a list of all the files that should be backed up in the database, the DBA can look in the following views: V$DATAFILE for datafiles, and V$LOGFILE for the redo log files. To obtain the names of the control files for the Oracle database, the DBA should execute the show parameters control_files command from Server Manager. Once all the database files have been backed up, the DBA can then restart the database.
The final type of backup considered is the online backup. These types of backups allow the database to be up and running during the entire time the backup is taking place. Hot backups require archiving of redo logs in order to recover the backups. Hot backups require the DBA to adopt a hybrid logical-physical view of the database. Hot backups are taken in an iterative process, one tablespace at a time. The first step in a hot backup is to place the tablespace into backup mode with the alter tablespace name begin backup statement. Once executed, the DBA can make a copy of the datafiles that comprise a tablespace to an alternate disk, or off the machine entirely to tape or other external media. Once the backup is complete, the alter tablespace name end backup statement is issued. Since the database was open for activity the entire time the backup took place, the DBA must archive the redo logs that were collected during the time of the backup. In order to know which redo logs were used, the DBA should execute the archive log list statement within Server Manager and take note of the oldest online redo log sequence. After the backup is complete, the DBA can force archival of the redo log entries saved written during the backup with the alter system switch logfile statement.
Discussed in this chapter also is the importance and value of archiving redo logs in the various backup situations. Archiving redo logs allows the DBA to save all redo information generated by the database. In the event of a database failure that destroys some data, the changes that were written to the redo logs can be reapplied during database recovery to allow for full re-creation of all data changes committed right up to the point the database failed. If the DBA is using the logical export options provided with the Oracle EXPORT and IMPORT utilities, then archiving is of limited value because archiving cannot be applied to recovery using logical backups. Only if the database is using physical backups can the use of archiving be applied. For any database that requires recovery of data to the point of database failure, Oracle recommends the archiving of redo logs and the use of physical database backups.
Some operations have special database availability considerations that will influence the backup options that are required for those systems. This statement is particularly true for databases that are required to be available at all times, or 24� 7 databases. There are two types of situations where 24-hour availability may be required for a database. One is where the database is deployed globally to users around the world who work at different times. The other is for databases that are deployed to users on a limited range of time zones, but the application relies on periodic refreshing of data as provided by batch processing that runs during off-peak usage time periods in the day. The 24-hour database cannot be brought down or have restricted session enabled on it frequently enough to allow for offline or logical backup. Furthermore, their recovery requirements include the ability to recover all data up to the point of time the database failed. As such, these systems generally require online backups in conjunction with archiving of online redo logs. The online backup allows users to access the database at all times, even while the backup takes place, and the archival of redo logs allows the DBA to apply all database changes made during and after the backup up to the moment in time the database failed.
Database recovery has several implications related to time. Database recovery is a two-step process. The first step is the application of the backup to the database to restore lost or damaged information. The second part is the application of archived redo logs in order to allow for recovery to a point after the most recent backup, usually to the point in time the database failed. Depending on the type of recovery plan pursued and the number of archived redo logs that need to be applied, the database recovery can be time-consuming. Another time consideration that should be weighed into database recovery is the amount of time required by users to recover their own data changes by reentering the data lost.
The backup options pursued by the DBA have time implications of their own. Depending on the option chosen for use in the database, the DBA may require time where the users are not permitted to access the system. This requirement may be fine for systems that are expected to be available during normal business hours. In this case, logical or offline backups may be an option. However, there are situations where the database must always be available. In this case, the DBA should choose online backups in conjunction with the archiving of redo logs. The choice of backup method used to support recoverability on the database will impact the time required for recovery on the database.
Transaction volume will ultimately affect the backup and recovery of a database as well. This fact is especially true for databases that archive their redo log information. Since high transaction volumes produce large amounts of redo log information, the number of archived redo logs has a tendency to increase quickly. In order to recover all database changes made in the event of a database failure, all archived redo log entries made during and after an online backup, or after the offline backup, will need to be applied after the backup is applied. This effort of applying the redo information takes more or less time depending on the number or size of the redo logs to be applied. The more redo logs, the longer the recovery. In order to combat the length of time it takes for database recovery with archived redo logs, the DBA should save tablespaces that experience large transaction volumes frequently. Even in environments where archiving is not used, the overall recovery time for a database, including the time it takes for users to reenter the data lost from the period of time following the most recent backup to the database failure, is improved if backups occur frequently. However, obtaining downtime on the database for an offline backup or a logical backup may not be possible more often than once a day. This fact means that the system may always be susceptible to a day’s worth of downtime in the event of a database failure, plus the time it takes to perform the recovery that is possible using the offline or logical backups available.
The final area of discussion involved the opposite situation to high transaction volumes and their backup/recovery implication. That other situation is that involving read-only tablespaces. Since the data in read-only tablespaces cannot be changed, the backup requirements for these tablespaces are minimal. Whenever the data does change, the tablespace must be backed up. After the tablespace is set into read only mode, the data should be backed up once and then left alone, as the DBA can rest assured that the tablespace will not change.
| Without backups, database recovery is not possible in the event of a database failure that destroys data. | |
| The business requirements that affect database availability, whether the database should be recoverable to the point in time the database failure occurred, along with the overall volatility of data in the database, should all be considered when developing a backup strategy. | |
| Disaster recovery for any computer system can have the following impact: loss of time spent recovering the system, loss of user productivity correcting data errors or waiting for the system to come online again, the threat of permanent loss of data, and the cost of replacing hardware. | |
| The final determination of the risks an organization is willing to take with regard to their backup strategy should be handled by management. | |
| Complete recovery of data is possible in the Oracle database—but depends on a good backup strategy. | |
| Database recovery consists of two goals: the complete recovery of lost data and the rapid completion of the recovery operation. | |
| Testing backup and recovery strategy has three benefits: weaknesses in the strategy can be corrected, data corruption in the database that is being copied into the backups can be detected, and the DBA can improve his or her own skills and tune the overall process to save time. | |
| The difference between logical and physical backups is the same as the difference between the logical and physical view of Oracle’s usage of disk resources on the machine hosting the database. | |
| Logical backups are used to copy the data from the Oracle database in terms of the tables, indexes, sequences, and other database objects that logically occupy an Oracle database. | |
| The EXPORT and IMPORT tools are used for logical database object export and import. | |
| Physical backups are used to copy Oracle database files that are present from the perspective of the operating system. This includes datafiles, redo log files, control files, the password file, and the parameter file. | |
| To know what datafiles are present in the database, use the V$DATAFILE or the DBA_DATA_FILES dictionary views. | |
| To know what control files are present in the database, use the show parameters control_files command from Server Manager or look in the V$CONTROLFILE view. | |
| To know what redo log files are available in the database, use the V$LOGFILE dictionary view. | |
| There are two types of physical backups: offline backups and online backups. | |
| Offline backups are complete backups of the database taken when the database is closed. In order to close the database, use the shutdown normal or shutdown immediate commands. | |
| Online or "hot" backups are backups of tablespaces taken while the database is running. This option requires that Oracle be archiving its redo logs. To start an online backup, the DBA must issue the alter tablespace name begin backup statement from Server Manager. When complete, the DBA must issue the alter tablespace name end backup statement. | |
| Archiving redo logs is crucial for providing complete data recovery to the point in time that the database failure occurs. Redo logs can only be used in conjunction with physical backups. | |
| When the DBA is not archiving redo logs, recovery is only possible to the point in time the last backup was taken. | |
| Databases that must be available 24 hours a day generally require online backups because they cannot afford the database downtime required for logical backups or offline backups. | |
| Database recovery time consists of two factors: the amount of time it takes to restore a backup, and the amount of time it takes to apply database changes made after the most recent backup. | |
| If archiving is used, then the time spent applying the changes made to the database since the last backup consists of applying archived redo logs. If not, then the time spent applying the changes made to the database since the last backup consists of users manually reentering the changes they made to the database since the last backup. | |
| The more changes made after the last database backup, the longer it generally takes to provide full recovery to the database. | |
| Shorter recovery time can be achieved with more frequent backups. | |
| Each type of backup has varied time implications. In general, logical and offline physical database backups require database downtime. | |
| Only online database backups allow users to access the data in the database while the backup takes place. | |
| The more transactions that take place on a database, the more redo information that is generated by the database. | |
| An infrequently backed-up database with many archived redo logs is just as recoverable as a frequently backed-up database with few online redo logs. However, the time spent handling the recovery is longer for the first option than the second. | |
| Read-only tablespaces need backup only once, after the database data changes and the tablespace is set to read-only. |