In this chapter, you will understand and demonstrate knowledge in the following areas:
| Introduction to SQL*Loader | |
| SQL*Loader operation | |
| SQL*Loader data load paths |
Although it comprises only a small amount of the actual test material on OCP Exam 2, learning SQL*Loader has a bigger payoff in the career of a DBA than getting a few questions right. SQL*Loader is a useful tool for loading data into a table. SQL*Loader accounts for the smallest portion of OCP Exam 2—only 5 to 8 percent of the test will consist of SQL*Loader questions. But, understanding SQL*Loader is nonetheless important as you progress toward OCP DBA certification.
In this section, you will cover the following topics related to introducing SQL*Loader:
| The control file | |
| The datafile |
SQL*Loader is a tool used by DBAs and developers to populate Oracle tables with data from flat files. It allows the DBA to selectively load certain columns but not others, or to exclude certain records entirely. SQL*Loader has some advantages over programming languages that allow embedded SQL statements, as well. Although a programmer could duplicate the functionality of SQL*Loader by writing her own load program, SQL*Loader has the advantage of flexibility, ease of use, and performance. It allows the developer to think more about loading the data than the details of opening files, reading lines, executing embedded SQL, and checking for end-of-file markers, and dramatically reduces the need for debugging. Using SQL*Loader consists of understanding its elements. The first is the data to be loaded, which is stored in a datafile. The SQL*Loader datafile is not to be confused with Oracle server datafiles, which store database objects. The next is a set of controls for data loading that are defined in a file called the control file. These controls include specifying how SQL*Loader should read records and parse them into columns, which columns should be loaded by data appearing in each position, and other features.
The control file provides the following information to Oracle for the purpose the data load: datafile name and format, character sets used in the datafiles, datatypes of fields in those files, how each field is delimited, and which tables and columns to load. You must provide the control file to SQL*Loader so that the tool knows several things about the data it is about to load. Data and control file information can be provided in the same file or in separate files. Some items in the control file are mandatory, such as which tables and columns to load and how each field is delimited.
The following example is of a combined control file and datafile. It illustrates basic usage and syntax for control files and the effects of those specifications.
variable-length, terminated enclosed data formatting
LOAD DATA
INFILE *
APPEND INTO TABLE address
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY ‘"’
(global_id, person_lname, person_fname,
area_code,phone_number, load_order SEQUENCE(MAX,1))
BEGIN DATA
83456, "Smith","Alfred",718,5551111
48292, "Smalls","Rebeca",415,9391000
34436, "Park","Ragan",919,7432105
15924,"Xi","Ling",708,4329354
49204,"Walla","Praveen",304,5983183
56061,"Whalen","Mark",407,3432353
Comments can appear anywhere in the control file, and need only be delineated by two dashes. Care should be taken not to place comments in the datafile or in the data portion of the control file. The load data clause generally indicates the beginning of the contents of the control file. For all control files, the infile clause is required. It denotes where SQL*Loader can find the input data for this load. Using an asterisk (*) denotes that the data is in the control file. The next line of the control file is the into table clause. It tells SQL*Loader the table to which the data will be loaded and the method by which it will be loaded. The append keyword denotes that these records can be inserted even if the table has other data. Other options include insert, which allows records to enter the table only if the table is empty; and replace and truncate, which delete all rows from the table before loading the new records. The fields terminated by clause defines how columns will be delimited in the variable-length data records. The character that separates each data element is enclosed in double-quotes. Also, an optional enclosure character is defined with the optionally enclosed by clause. The next line begins with a parenthesis, and within those parentheses the columns in the table to be loaded are specified. If a column from the table is not listed in this record, it will not be loaded with data from the datafile. The data loaded in each column will be selected from the data record positionally, with the first item in the record going into the first column, the second item in the second column, etc. The following example contains one special case in which an exception is made--a column denoted by SEQUENCE(MAX,1), corresponding to a column in the table that will be populated with a sequence number that is not present in the datafile. SQL*Loader supports the generation of special information for data loads, such as sequences and data type conversions. Finally, in cases where the data is included in the control file, the begin data clause is mandatory for denoting the end of the control file and the beginning of the data. This clause need not be present if the data is in a separate file.
Usually, however, the control file and datafile are separate. For this example, the direct path option has been set by the options clause, which can be used for setting many command-line parameters for the load. In a direct path load, SQL*Loader bypasses most of Oracle’s SQL statement processing mechanism, turning flat file data directly into data blocks. The load data clause indicates the beginning of the control file in earnest. The infile clause specifies a datafile called datafile1.dat. The badfile clause specifies a file into which SQL*Loader can place datafile records that cannot be loaded into the database. The discardfile clause specifies a file in which discarded data that does not fit a when clause specified in the control file will be stored. A replace load has been specified by the into table clause, so all records in the tables named will be deleted and data from the file will be loaded. The column specifications in parentheses indicate by the position clause that the records in the datafile are fixed-width. Multiple into table clauses indicate that two files will be loaded.
OPTIONS (direct=true)
LOAD DATA
INFILE ‘datafile1.dat’
BADFILE ‘datafile1.bad’
DISCARDFILE ‘datafile1.dsc’
REPLACE INTO TABLE phone_number
(global_id POSITION(1:5) INTEGER EXTERNAL,
people_lname POSITION(7:15) CHAR,
people_fname POSITION(17:22) CHAR,
area_code POSITION(24:27) INTEGER EXTERNAL,
phone_number POSITIONAL(29:36) INTEGER EXTERNAL)
INTO TABLE address
WHEN global_id != ‘ ‘
(global_id POSITION(1:5) INTEGER EXTERNAL,
city POSITION(38:50) CHAR,
state POSITION(52:54) CHAR,
zip POSITION(56:61) INTEGER EXTERNAL)
Contents of datafile.dat are listed as follows:
14325 SMITH ED 304 3924954 MILLS VA 20111
43955 DAVISON SUSAN 415 2348324 PLEASANTON CA 90330
39422 MOHAMED SUMAN 201 9493344 HOBOKEN NJ 18403
38434 MOUSE MIKE 718 1103010 QUEENS NY 10009
The following outlines the syntax and semantics for the control file. Statements in this file can run from line to line, with new lines beginning at any word. The control file is not case sensitive, except in strings in single or double quotes. Comments can be placed anywhere as long as they are preceded by two dashes. Column and table names can be the same as SQL*Loader reserved words as long as they appear in quotation marks.
| -- Comments | Any remarks are permitted. |
Options |
Command-line parameters can be placed in the control file as options. The format for this clause is (option=X, option=Y…). |
| Unrecoverable Recoverable |
Specifies whether to create redo log entries for loaded data. Unrecoverable can be used on direct loads only. |
| load continue_load |
Either load or continue_load must be specified in the control file. |
| data | Provided for readability. |
| characterset | Specifies the character set of the datafile. |
| preserve blanks | Retains leading white space from datafile in cases where enclosure delimiters are not present. |
| begin data | Keyword denoting the beginning of data records to be loaded. |
| infile name | Keyword to specify name of input files. An asterisk (*) following this keyword indicates data records are in the control file. |
| badfile name | Keyword to specify name of bad file. They are interchangeable. |
| discardfile name | Keyword to specify name of discard file. They are interchangeable. |
| discards X | Allow X discards before opening the next datafile. |
| discardmax X | Allow X discards before terminating the load. |
| insert append replace truncate |
The table operation to be performed. insert puts rows into an empty table. append adds rows to a table. replace and truncate delete rows currently in a table and place the current data records into the table. |
| into table tablename | Keyword preceding the tablename. |
| sorted indexes | For direct path loads, indicates that data has already been sorted in specified indexes. |
| singlerow | For use when appending rows or loading a small amount of data into a large table (rowcount ratio of 1:20 or less). |
|3498553|SMITHY|45000|
Datafiles can have two formats. The data Oracle will use to populate its tables can be in fixed-length fields or in variable-length fields delimited by a special character. Additionally, SQL*Loader can handle data in binary format or character format. If the data is in binary format, then the datafile must have fixed-length fields. Figure 10-1 gives a pictorial example of the records that are fixed in length.
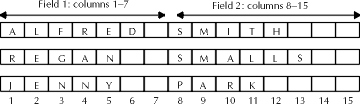
Figure 1: Fixed-length records
In contrast to fixed length data fields, variable-length data fields are only as long as is required to store the data. Unlike in Figure 10-1, a variable-length record will have only four characters for the second field of the fourth record. Typically, data fields in variable-length records are terminated by a special character or enclosed by special characters. These options are called terminated fields and enclosed fields, respectively. The following list shows the differences between terminated and enclosed fields:
| Terminated fields—delimiter (,) | Enclosed fields—delimiter (|) |
| SMITH,ALFRED SMALLS,REGAN PARK,JENNY |
|SMITH|ALFRED| |SMITH|REGAN| |PARK|JENNY| |
The final thing to know about data records is the difference between physical and logical data records. In a datafile, each row of the file may be considered a record. This type of record is called a physical record. A physical record in a datafile can correspond either to a row in one table or several tables. Each row in a table is also considered a record, and the type of record each is considered to be is a logical record. In some cases, the logical records or rows of a table may correspond to several physical records of a datafile. In these cases, SQL*Loader supports the use of continuation fields to map two or more physical records into one logical record. A continuation field can be defined in the ways listed below:
| A fixed number of physical records always are concatenated together to form a logical record for table loading. | |
| Physical records are appended if a continuation field contains a special string. | |
| Physical records are concatenated if a special character appears as the last nonblank character. |
In this section, you will cover the following topics related to SQL*Loader operation:
| Additional load files at run time | |
| SQL*Loader command-line parameters |
Finally, SQL*Loader accepts special parameters that can affect how the load occurs, called command-line parameters. These parameters–which include the ID to use when loading data, the name of the datafile, and the name of the control file--are all items that SQL*Loader needs to conduct the data load.. These parameters can be passed to SQL*Loader on the command line or in a special parameter file called a parfile.
SQL*Loader in action consists of several additional items. If, in the course of performing the data load, SQL*Loader encounters records it cannot load, the record is rejected and the tool puts it in a special file called a bad file. The record can then be reviewed to find out the problem. Conditions that may cause a record to be rejected include integrity constraint violation, datatype mismatches, and other errors in field processing.
Additionally, SQL*Loader gives the user options to reject data based on special criteria. This criteria is defined in the control file as part of the when clause. If the tool encounters a record that fails a specified when clause, the record is placed in a special file called the discard file. The second example in the control file discussion in the previous section describes this type of load. In both cases, the tool writes the bad or discarded record to the appropriate file in the same format as was fed to the tool in the datafile. This feature allows for easy correction and reloading, with reuse of the original control file. Figure 10-2 represents the process flow of a data record from the time it appears in the datafile of the load to the time it is loaded in the database.
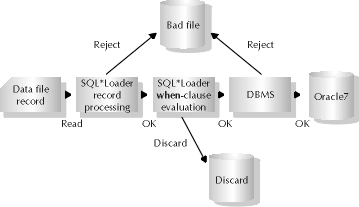
Figure 2: Control flow for record filtering
Recording the execution of SQL*Loader happens in the log file. If for any reason the tool cannot create a log file, the execution terminates. The log file consists of six elements. The header section details the SQL*Loader version number and date of the run. The global information section gives names for all input and output files, the command-line parameters, and a continuation character specification if one is required. The table information section lists all tables being loaded by the current run, and load conditions, and whether data is being inserted, appended, or replaced. The datafile section contains details about any rejected records. The table load information section lists the number of tables loaded and the number of records that failed table requirements for loading, such as integrity constraints. Finally, the summary statistics section describes the space used for the bind array, cumulative load statistics, end time, elapsed time, and CPU time.
The following parameters are accepted by SQL*Loader on the command line. These options can be passed to SQL*Loader as parameters on the command line in the format PARAMETER=value. Alternately, parameters can be passed to SQL*Loader in another component called the parfile. The parameters can be identified in the parfile as option=value. The parameters available for SQL*Loader are listed below. Note that some of the parameters are duplicates of options that can be set in the control file, indicating that there are multiple methods for defining the same load using SQL*Loader.
| USERID | Oracle userid and password |
| CONTROL | Control filename |
| LOG | Log filename |
| BAD | Bad filename |
| DATA | Datafile name |
| DISCARD | Discard filename |
| DISCARDS | Number of discards to terminate the load (default: all) |
| SKIP | Number of logical records to skip (default: 0) |
| LOAD | Number of logical records to load (default: all) |
| ERRORS | Number of errors to terminate the load (default: 50) |
| ROWS | Number of rows in the conventional path bind array or between direct path data saves (conventional path: 64, direct path: all) |
| BINDSIZE | Size of conventional path bind array in bytes |
| SILENT | Suppress messages between run (header, feedback, errors, discards) |
| DIRECT | Use direct path load (default: FALSE) |
| PARFILE | Parameter filename |
| PARALLEL | Perform parallel load (default: FALSE) |
| FILE | Datafile to allocate extents |
The use of parameters is now presented. Note that SQL*Loader is a separate utility from Oracle. Attempts to run it from the SQL*Plus command prompt will fail unless preceded by the appropriate command to temporarily or permanently exit SQL*Plus to the host operating system prompt. The table listing of SQL*Loader parameters presented is in a special order—if the DBA would like, she can specify the values for each option without actually naming the option, so long as the values correspond in position to the list presented. Thus, two statements executing SQL*Loader are the same, even though the parameter options may not be named.
Sqlldr scott/tiger load.ctl load.log load.bad load.dat
Sqlldr USERID=scott/tiger CONTROL=load.ctl DATA=load.dat
Additionally, a mixture of positional and named parameters can be passed. One issue to remember is that positional parameters can be placed on the command line before named parameters, but not after. Thus, the first of the following statements is acceptable, but the second is not:
sqlldr scott/tiger load.ctl DATA=load.dat
sqlldr DATA=load.dat scott/tiger load.ctl
As mentioned, another option for specifying command-line parameters is placing the parameters in a parfile. The parfile can then be referenced on the command line. The usage may be as follows.
Sqlldr parfile=load.par
The contents of load.par may look like the following listing:
DATA=load.dat
USERID=scott/tiger
CONTROL=load.ctl
LOG=load.log
BAD=load.bad
DISCARD=load.dsc
A final alternative to specifying SQL*Loader load parameters on the command line is specifying the command-line parameters in the control file. In order to place command-line parameters to the control file, the options clause must be used in the control file. This clause should be placed at the beginning of the file, before the load clause. Command-line parameters specified in the options clause should be named parameters, and can be overridden by parameters passed on the command line or in the parfile. The control file in the second example of the previous section details the use of parameters in the control file.
In this section, you will cover the following topics related to SQL*Loader data load paths:
| The conventional path and the direct path | |
| Integrity constraints, triggers, and data loads | |
| Indexes and the direct path | |
| Data saves |
SQL*Loader provides two data paths for loading data. They are the conventional path and the direct path. Whereas the conventional path uses a variant of the SQL insert statement with an array interface to improve data load performance, the direct path avoids the RDBMS altogether by converting flat file data into Oracle data blocks and writes those blocks directly to the database. Conventional path data loads compete with other SQL processes, and also require DBWR to perform the actual writes to database.
Figure 10-3 pictorially displays the differences between conventional and direct path loads. In a conventional load, SQL*Loader reads multiple data records from the input file into a bind array. When the array fills, SQL*Loader passes the data to the Oracle SQL processing mechanism or optimizer for insertion. In a direct load, SQL*Loader reads records from the datafile, converts those records directly into Oracle data blocks, and writes them to disk, bypassing most of the Oracle database processing. Processing time for this option is generally faster than for a conventional load.
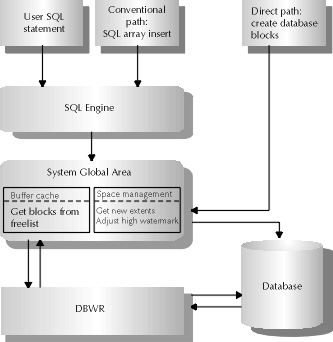
Figure 3: Database paths for conventional and direct loads
The direct load option is specified as a command-line parameter, and like other parameters, it can be specified in three different ways—on the command line as a named or positional parameter, in a parameter file, or in the control file as part of the options clause. At the beginning of the direct path load, SQL*Loader makes a call to Oracle to put a lock on the tables being inserted, and it makes another call to Oracle again at the end to release the lock. During the load, SQL*Loader makes a few calls to Oracle, to get new extents when necessary and to reset the highwatermark when data saves are required. A data save is the direct path equivalent to a commit. A list of actions the direct path takes is given below.
| Partial blocks are not used, so the server process is never required to do a database read. | |
| No SQL insert commands are used. | |
| The bind array is not used—SQL*Loader creates database blocks and writes them directly to storage. This feature allows the tool to avoid contending with other SQL statements for database buffer cache blocks. | |
| The direct path allows for presorting options, which enables usage of operating system high-speed sorting algorithms, if available. This speeds the creation of indexes and primary keys. | |
| Since SQL*Loader writes data directly to disk, in the event of instance failure, all changes made up to the most recent data save will be stored on disk, limiting the need for recovery. |
Prior to executing the data load using SQL*Loader, the DBA must determine what type of load to use. There are two paths available for use, and the following table lists the situations for using each load type. The two types of loads available are the conventional and the direct path. Generally speaking, the conventional path is slower than the direct path because it handles all the constraints and indexing in an Oracle database as the data is loaded, essentially paying all its dues up front. On the other hand, the direct path load can make some substantial performance gains on the conventional path in certain situations by deferring payment of all its dues to the Oracle server until the load is over.
| When to Use the Direct PathLarge amount of data to load in a short time frame | When loading data across a network |
| Need to use parallel loading to increase load performance | When loading data into a clustered table |
| Need to load a character set not supported in the current session, or when the conventional load of that character set produces errors | When loading small amount of data into a large indexed table or a large table with many integrity constraints—because it takes longer to drop and re-create a large index than insert a few rows to the table and index |
| When applying single-row operations or SQL functions to data being loaded |
The advantages of conventional path focus mainly around the fact that it is relatively nondisruptive to the underpinnings of a database table. Conventional path loads work on the same principles that normal data inserts work, only much faster. Records in a conventional path load pay their dues to the Oracle database as the records load; that is to say, the records loaded on the conventional path will update the associated indexes with a table, and generally have the look and feel of normal online transaction processing.
In contrast, direct path loading helps in the situation where a great deal of data must be loaded in a short period of time. Direct path loads bypass the "customs inspectors" of the Oracle database, namely integrity constraints, as well as the "post office," or table indexes, of the database. Unfortunately, the safety and performance conditions provided by indexes and integrity constraints must be met at some point. Therefore, the direct path operates on a "pay me later" principle—the index updates have to happen at some point, so after the DBA completes the direct path load, he or she will need to reapply the constraints and rebuild the indexes so as to put the Oracle database back together before users can access the data loaded in the direct path.
Some types of integrity constraints can be enforced during a direct path load, but not all. Integrity constraints that can be checked include NOT NULL constraints, unique constraints and primary key constraints, and check constraints. These constraints can be checked because they typically don’t refer to other tables; however, any constraint that refers to data in another table cannot be enforced by SQL*Loader during a direct path load. These constraints include foreign key constraints. The right way to handle constraints of this type is to disable them before the load and reenable them after the load, which the tool can do automatically if specified. The syntax for specifying this option is to use the following clause:
REENABLE {DISABLED_CONSTRAINTS} {EXCEPTIONS tablename}
The disabled_constraints keyword is optional and provided for readability; when using the exceptions clause, the table name specified must already exist. If this clause is not used in the data load, then the integrity constraints must be enabled manually using the alter table statement. When the constraint is reenabled, the entire table is checked and any errors are placed in an error table specified by the load. Similar to foreign-key constraints, default values cannot be enforced at the table level during a direct path load. Instead, the control file for the load should use the defaultif clause to specify the default expression. Otherwise, only data available to SQL*Loader for loading data to a column with a default specified will be inserted. If the data record for that column is NULL, then the value inserted will also be NULL.
Triggers present a unique issue to loading data. Insert triggers are disabled at the beginning of the direct load, which means that the trigger does not execute for any data being inserted on the direct load. Unlike constraints, triggers are not reapplied to all table rows when the trigger is reenabled. If there is login employed by the trigger that must happen to the data loaded in the direct path, it must be duplicated in some other way by the application, either through an integrity constraint, an update trigger, or a stored procedure.
One of the reasons conventional path loads run slower than direct path loads is because in the conventional path, the indexes are updated every time a row is inserted. In contrast, the direct path load will rebuild the index at the end. Ideally, data will be presorted when loaded in the direct path, making index creation simple and fast. If this situation is the case, then Oracle will not require temporary storage to sort and merge the index. If the data is not presorted, however, then Oracle will require temporary space to sort and merge the data being indexed. Use the following formula to determine size requirements in bytes for temporary storage: 1.3 *(number_rows *(10 + sum_of_col_sizes + num_of_cols)). In the equation, 1.3 represents the average number of bytes needed to sort typical lists of unordered data. The actual range for this constant is 1.0 to 2.0, where 1.0 represents ordered input and 2.0 represents input in exactly the opposite order.
SQL*Loader may leave an index in a state called the direct load state in the event that a direct load is unsuccessful. This means that the index is unusable and must be dropped and re-created for the data currently in the table. A query on INDEX_NAME and status against the DBA_INDEXES data dictionary view will show if an index was left in direct load state. The following items can cause the tool to leave an index in direct load state:
| SQL*Loader ran out of space for the index. | |
| Instance failure while creating an index. | |
| Duplicate values in a unique or primary key. | |
| Presorted data is not in order specified by the sorted indexes clause of the control file. |
SQL*Loader can save data during the direct path load with the use of data saves. Figure 10-3 shows that the direct path load accesses Oracle intermittently to request new extents and to adjust the highwatermark for the object being loaded. These activities are required as part of a data save. The frequency SQL*Loader will execute a data save is specified by the ROWS command-line parameter, and the default value for ROWS in a direct load is all. Although executing a data save during a direct path load reduces load performance, there are often compelling reasons to execute them intermittently rather than waiting until the load completes. A major reason for choosing the direct path is the need to load large amounts of data, so it may be wise to set ROWS such that a data save happens a few times during the load. For example, a load of 5 million rows may require a data save every million rows.
In a direct load, full database blocks are written to the database beyond a table’s highwatermark. A data save simply moves the highwatermark. Although similar in concept to a commit in regular SQL statement processing and conventional loading, a data save is NOT the same as a commit. Some key differences are listed here:
| Indexes are not updated by a data save. | |
| Internal resources are not released in a data save. | |
| The transaction is not ended by a data save. |
This chapter introduced SQL*Loader concepts and functions. SQL*Loader is a tool that developers and DBAs can use to load data into Oracle7 tables from flat files easily. SQL*Loader consists of three main components: a set of data records to be entered, a set of controls explaining how to manipulate the data records, and a set of parameters defining how to execute the load. Most often, these different sets of information are stored in files—a datafile, a control file, and a parameter file. SQL*Loader comprises about 5–8 percent of exam questions asked on OCP Exam 2.
Information in data records can be set into fixed-length or variable-length columns. If the data is set into fixed-length columns, the control file will contain a listing of the columns along with their start and end positions. If the data is set into variable-length columns, the control file will define the delimiters for each column in that record. There are two types of delimiters: terminating delimiters and enclosed delimiters.
SQL*Loader uses two other files during data loads in conjunction with record filtering. They are the bad file and the discard file. Both filenames are specified either as parameters or as part of the control file. The bad file stores records from the data load that SQL*Loader rejects due to bad formatting, or that Oracle7 rejects for failing some integrity constraint on the table being loaded. The discard file stores records from the data load that have been discarded by SQL*Loader for failing to meet some requirement as stated in the when clause expression of the control file. Data placed in both files are in the same format as they appear in the original datafile to allow reuse of the control file for a later load.
Recording the entire load event is the log file. The log filename is specified in the parameters on the command line or in the parameter file. The log file gives six key pieces of information about the run: software version and run date; global information such as log, bad, discard, and datafile names; information about the table being loaded; datafile information, including which records are rejected; data load information, including row counts for discards and bad and good records; and summary statistics, including elapsed and CPU time.
There are two load paths available to SQL*Loader: conventional and direct. The conventional path uses the SQL interface and all components of the Oracle RDBMS to insert new records into the database. It reliably builds indexes as it inserts rows and writes records to the redo log, guaranteeing recovery similar to that required in normal situations involving Oracle7. The conventional path is the path of choice in many loading situations, particularly when there is a small amount of data to load into a large table. This is because it takes longer to drop and re-create an index as required in a direct load than it takes to insert a small number of new rows into the index. In other situations, like loading data across a network connection using SQL*Net, the direct load simply is not possible.
However, the direct path often has better performance executing data loads. In the course of direct path loading with SQL*Loader, several things happen. First, the tool disables all constraints and secondary indexes the table being loaded may have, as well as any insert triggers on the table. Then, it converts flat file data into Oracle blocks and writes those full data blocks to the database. Finally, it reenables those constraints and secondary indexes, validating all data against the constraints and rebuilding the index. It reenables the triggers as well, but no further action is performed.
In some cases, a direct path load may leave the loaded table’s indexes in a direct path state. This generally means that data was inserted into a column that violated an indexed constraint, or that the load failed. In the event that this happens, the index must be dropped, the situation identified and corrected, and the index re-created.
Both the conventional and the direct path have the ability to store data during the load. In a conventional load, data can be earmarked for database storage by issuing a commit. In a direct load, roughly the same function is accomplished by issuing a data save. The frequency of a commit or data save is specified by the ROWS parameter. A data save differs from a commit in that a data save does not update indexes, release database resources, or end the transaction—it simply adjusts the highwatermark for the table to a point just beyond the most recently written data block. The table’s highwatermark is the maximum amount of storage space the table has occupied in the database.
Many parameters are available to SQL*Loader that refine the way the tool executes. The most important parameters are USERID to specify the username the tool can use to insert data and CONTROL to specify the control file SQL*Loader should use to interpret the data. Those parameters can be placed in the parameter file, passed on the command line, or added to the control file.
The control file of SQL*Loader has many features and complex syntax, but its basic function is simple. It specifies that data is to be loaded and identifies the input datafile. It identifies the table and columns that will be loaded with the named input data. It defines how to read the input data, and can even contain the input data itself.
Finally, although SQL*Loader functionality can be duplicated using a number of other tools and methods, SQL*Loader is often the tool of choice for data loading between Oracle and non-Oracle databases because of its functionality, flexibility, and performance.
| SQL*Loader loads data from flat file to a table. | |
| There are three components: datafile, control file, and parameter file. | |
| The datafile contains all records to be loaded into the database. | |
| The control file identifies how SQL*Loader should interpret the datafile. | |
| The parameter file gives runtime options to be used by SQL*Loader. | |
| Data in the datafiles can be structured into fixed- or variable-length fields. | |
| The positional specifications for fixed-length fields are contained in the control file along with other specifications for the data load. | |
| For variable-length data fields, appropriate delimiters must be specified. | |
| The two types of delimiters used are terminating delimiters and enclosed delimiters. | |
| Two additional files can be used for record filtering: bad files and discard files. | |
| There are two data load paths: conventional and direct. | |
| Conventional loads use the same SQL interface and other Oracle RDBMS processes and structures that other processes use. | |
| Conventional path loading updates indexes as rows are inserted into the database, and also validates integrity constraints and fires triggers at that time. | |
| Direct path loads bypass most of the Oracle RDBMS, writing full database blocks directly to the database. | |
| Direct path loading disables indexes, insert triggers, and constraints until all data is loaded. Constraints and indexes are rechecked and built after data load. | |
| The direct path load may occasionally leave an index in direct path state. This often is due to load failure or the loading of a data record that violates the table’s integrity constraints. |