In this chapter, you will understand and demonstrate knowledge in the following areas:
| Managing rollback segments | |
| Managing tables and indexes | |
| Managing clusters | |
| Managing data integrity constraints |
A good deal of the DBA’s daily job function is to create database objects. This fact is especially true for database administrators who manage databases primarily used for development and test purposes. But even DBAs working on production systems will find that a good deal of their time is spent exploring the depths of setting up database objects. In most large organizations, there are development and enhancement projects The types of database objects covered in this section are found in most database environments. This discussion covers material that will comprise about 27 percent of OCP Exam 2.
In this section, you will cover the following topics related to managing rollback segments:
| Rollback segment concept and function | |
| Creating and sizing rollback segments | |
| Storage and performance trade-offs | |
| Determining the number of rollback segments |
Often, the DBA spends part of a given day "fighting fires." Many times, these fires involve rollback segments. These database objects are probably the most useful in data processing, but they can be troublesome for the DBA to maintain. Often, rollback segments need to be resized to support the execution of long-running transactions. Other problems related to rollback segments include adding rollback segments to support higher numbers of transactions executing on the database, or resolving a recovery issue related to rollback segments. Whatever the cause, the DBA is well advised to master the management of these sometimes fussy database objects.
Transactions cannot exist without rollback segments. In the same way that Oracle automatically provides statement-level read consistency, Oracle can also provide transaction-level read consistency with the use of rollback segments. Transaction processing makes it easy to correct large mistakes with the use of commits and rollbacks. When the user process executes a logical unit of work, the individual update, insert, and delete statements that may have happened in the transaction can then be committed as a group. Likewise, if the user decides that the work must be "backed out," the user can simply execute a rollback, which discards the changes made to the database in favor of the version existing before the transaction began. It is also possible to break a transaction down into logical units. This function is managed with the use of savepoints. Savepoints are statements that can be issued in the course of a transaction that act as a benchmark for the end of one transaction portion and the beginning of another one.
SELECT * FROM emp FOR UPDATE;
DELETE * FROM emp WHERE empid = 49395;
SAVEPOINT pointA;
UPDATE emp SET emp_lname = ‘SMINT’
WHERE empid = 59394;
SAVEPOINT pointB;
ROLLBACK TO SAVEPOINT pointA;
COMMIT;
This extract demonstrates how savepoints can be incorporated into a session or transaction. At the beginning of the block, the rows of the EMP table are locked for the update. The user then deletes some data, which is the first logical unit of the transaction as noted by savepoint pointA. The second part of the transaction contains an update, which is marked as a unit by savepoint pointB. After that, the user process eliminates the first transaction unit by rolling back to the first savepoint, pointA, and then the transaction is committed. The change made to employee #59394’s last name was NOT saved, but the deletion of data for employee #49395 is now permanent.
Rollback segments store all uncommitted data changes from transactions along with what the database looked like "prechange," for the purposes of read consistency and transaction concurrency. Each rollback segment has several extents allocated to it of equal size. As user processes make data changes, they must also write entries of the "before" and "after" look of the data. These entries allow other processes to issue statements and transactions that see a read-consistent version of the data at whatever time they execute.
Each entry to a rollback segment is associated with a transaction by use of a special tracking value called a system change number, or SCN for short. The SCN allows Oracle to group all entries associated with a particular transaction together for the purpose of identification. If a rollback or commit occurs, Oracle adds a record to the redo log saying that SCN #X has been committed. Oracle then knows which changes to apply to the database permanently based on the SCN used to identify the transaction. If the transactions that create entries in the rollback segment do not commit their changes for a long time, those entries must stay active in the rollback segment until the process commits the transaction. Once the transaction is committed, the entries in the rollback segment for that transaction are no longer active, and the space they take up in the rollback segment can be reused.
The ideal use of the rollback segment is to reuse the extents as much as possible. However, this is not always possible. Uncommitted transaction entries can span multiple extents of rollback segments. If a transaction goes on for a long time without committing data changes, the span of active rollback entries in the rollback segment corresponding to the uncommitted transaction will grow and grow over several extents. It is possible that the rollback segment will grow too large—an error will ensue, and the transaction rolls back automatically, and has to be executed again.
The most effective use of space for rollback segments is for the rollback segment to have few extents that are reused often. To support this operation, a special option is available in rollback segment storage called optimal. The optimal clause specifies the ideal size of the rollback segment in kilobytes or megabytes. This value tells Oracle the ideal number of extents the rollback segment should maintain. The optimal clause prevents rollback segments from getting stretched out by one or two long-running transactions. Figure 8-1 illustrates rollback segment reusability.
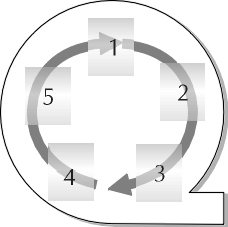
Figure 1: Rollback segment reusability
At instance startup, at least one rollback segment in the SYSTEM tablespace must be acquired by Oracle to support the database. If the user will be creating tables in other tablespaces, then at least one more rollback segment will be required. The number of rollback segments that the instance tries to acquire at startup is determined by two parameters: TRANSACTIONS and TRANSACTIONS_PER_ROLLBACK_SEGMENT. These parameters are set by the DBA in the init.ora file. The TRANSACTIONS parameter represents the average number of active transaction at any given time anticipated by the DBA. The TRANSACTIONS_PER_ROLLBACK_SEGMENT parameter represents the number of transactions that the DBA wants to allocate to any given rollback segment. By dividing TRANSACTIONS by TRANSACTIONS_PER_ROLLBACK_SEGMENT, the DBA can calculate the number of rollback segments Oracle will allocate at startup. Normally, the DBA wants to name certain rollback segments to be acquired at the time the instance starts. This task is accomplished with the ROLLBACK_SEGMENTS initialization parameter in init.ora.
Oracle’s Parallel Server Option presents a unique issue to DBAs trying to configure rollback segments. Two types of rollback segments available in Oracle: public and private rollback segments. Public rollback segments are a collection of rollback segments, any of which can be acquired by any of several instances on a database at instance startup. Private rollback segments are acquired by one and only one instance in a parallel configuration. The private rollback segment is usually acquired by name by one instance only in the Parallel Server Option. When the Parallel Server Option is not used, all rollback segments are public and private rollback segments, because public and private rollback segments are one in the same.
Two important reminders for setting up rollback segments are as follows. First, it benefits rollback segment performance on the system if the DBA creates at least one other rollback segment in the SYSTEM tablespace in addition to the one created by Oracle at instance startup. With two SYSTEM rollback segments, Oracle can keep one rollback segment available for all internal transactions. Oracle tries to avoid using the SYSTEM rollback segment for regular user transactions, but if transaction volume is heavy, Oracle may have to allow user processes to use the SYSTEM rollback segment. The extra SYSTEM rollback segment ensures better performance for system operations. Second, all extents in the rollback segments of an Oracle database are the same size. Commit this fact to memory—it’s on the OCP exam in one form or another. Oracle disallows the use of pctincrease in the create rollback segment statement in support of this fact.
Once a rollback segment is created, the DBA should bring it online in order to allow Oracle to use it. Once created for use, the rollback segment is in an offline status and must be brought online for use in the Oracle instance. Once online and in use by the users of the Oracle database, the rollback segment cannot be taken offline again until every transaction with entries in the rollback segment has completed.
Bigger is not usually better when it comes to rollback segments. The ideal size for rollback segments is large enough so that by the time the last extent fills with uncommitted transaction entries, the first extent of the rollback segment is filled with data from inactive transactions, and is thus reusable. If there are active transactions in the first extent of the rollback segment in this scenario, then the rollback segment must acquire another extent. Generally, the DBA should avoid letting Oracle stretch rollback segments out of shape like this, and the DBA has a few options to combat rollback segment stretch. First, the DBA may want to specify a value for the optimal clause for rollback segments. After Oracle commits the second transaction that causes the rollback segment to extend twice past optimal size, the database tells the rollback segment to shrink. This act will prevent a rollback segment from growing larger than required after supporting rollback entries for long-running transactions. Figure 8-2 illustrates how Oracle obtains or allocates more extents for a rollback segment.
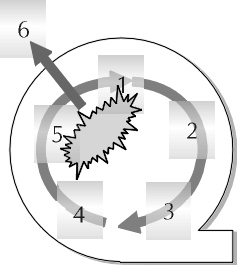
Figure 2: Allocating more extents for a rollback segment
Another option for managing rollback segment size is to create rollback segments of different sizes, and assign transactions to appropriately sized rollback segments. Consider a situation where almost all transactions during normal business hours on an Oracle database application handle small amounts of data. It makes sense to maintain small rollback segments in support of those transactions. But, it is important to ensure that rollback segments are not too small. If a long-running transaction cannot complete before being forced to allocate its rollback segment to acquire its maximum number of allowed extents, Oracle gives the following error: Snapshot too old (rollback segment too small). The transaction that produced this error is rolled back, and has to try to execute again after the rollback segment has been resized. It is wise for a DBA to create a few rollback segments large enough to handle long-running transactions in support of batch processing for the database system.
Rollback segments are created with the create rollback segment statement. The created rollback segment should have at least two extents of equal size. The alter rollback segment command can be used in any case to create the different rollback segments required on the database. Size for rollback segments is determined by the storage clauses. The following list of options is available for setting up rollback segments:
| initial The size in K or M of the initial rollback segment extent. | |
| next The size in K or M of the next rollback segment extent to be allocated. Should be the same as initial. | |
| optimal Total size in K or M of the rollback segment, optimally. | |
| minextents Minimum number of extents on the rollback segment, at least two. | |
| maxextents—Maximum number of extents the rollback segment can acquire. |
The ideal storage management a rollback segment can attain is to have the final extent of the segment filling just as the last set of active transactions in the first extent commit. In this manner, the rollback segment never needs to extend. When the rollback segment does not need to extend, then it also never needs to shrink. The process of extending and shrinking causes performance degradation associated with rollback segment performance. Information about the management of shrinks and extents and the use of the optimal storage clause can be found in chapters covering OCP Exam 4 in this Guide. Refer to the discussion of rollback segment performance, and the V$WAITSTAT view.
Another area of rollback segment performance that must be monitored and managed carefully is ensuring that enough rollback segments are available for the transactions on the database to obtain a rollback segment when they need to place transaction entries in one. The performance of rollback segments is covered extensively in of this text. At this point, however, a few key topics should be covered. The first is the concept of a wait ratio. If a process ever has to wait for something, Oracle keeps track of it in a special set of data dictionary views designed to track performance, called the V$ views. For example, a user may need to write several transaction entries to the rollback segment, but cannot do so because the rollback segment is busy being written to by another user. The result is that a user process has to wait for a resource to become free in order to write a rollback segment entry. Some V$ views that are used for this area are the V$ROLLNAME and V$ROLLSTAT views.
Most of the time, the wait ratio for any resource will be under 1 percent, based on the way it is calculated. In Unit 4, the text will elaborate on the ways to calculate wait ratios for various resources. For now, it is important to know that, when the wait ratio for any resource goes over 1 percent, the DBA must do something to improve the performance on that resource. For example, consider a performance problem on the rollback segment. Assume that the wait ratio is determined to be 3 percent for that rollback segment by data in the V$ROLLSTAT performance view. Since the wait ratio is over 1 percent, the DBA must do something. In this situation, the DBA needs to figure out which option available to her will reduce the number of times a process will wait. For example, increasing the number of extents a rollback segment has may not improve the likelihood that a process will have to wait in order to write a record to the rollback segment, because perhaps the problem is due to the fact that the disk controller for the drive containing rollback segments is frequently in use by other processes. In other words, the right option may be to increase the number of rollback segments available to the database.
Performance is made or broken not by the size of the rollback segments but by the number of them. Unfortunately, knowing there is a problem with the size is more clearcut. If a transaction causes the rollback segment to allocate its maximum number of extents and the transaction still cannot finish, Oracle returns an error. However, if there are processes that don’t exceed the maximum number of extents but do cause a lot of extents to be allocated, Oracle silently extends and shrinks, and causes phantom performance degradation that will be noticed by users and the DBA, but that will be impossible to identify without close examination of V$WAITSTAT. Worse, there may not be enough rollback segments to go around for all the processes on a busy day. This situation causes waits for the rollback segments that are available. But again, no explicit error gets written to a log file or to the screen. Performance just quietly gets worse and worse until users start complaining loudly that the processes that ran in 10 seconds two weeks ago now take several minutes. Only on close examination of performance as reflected by V$ROLLSTAT and V$WAITSTAT will the DBA identify the problem.
Once performance situations are identified, the DBA will most likely have to add rollback segments to the instance. Oracle has a recommended strategy for placing the appropriate number of rollback segments on a database to start, followed by careful monitoring to determine if the number of rollback segments on the database are enough to handle the job. For easy recollection, the DBA can call Oracle’s rollback sizing methodology the Rule of Four. The basic tenet of the Rule of Four is to take the total number of transactions that will hit the database at any given time and divide by 4 to know how many rollback segments to create.
Consider this example. A DBA needs to size the number of rollback segments for the database. Initially, this database will be used for a small user rollout of an application for user acceptance testing purposes. Only about 25 users will access the database at any given time. The DBA applies the Rule of Four to the average number of transactions on the database at any given time and determines that about six rollback segments are required to support these users. The additional calculation of rollback segment size would be piggybacked into the Rule of Four calculation, taking an average of four transactions per rollback segment and multiplying it by the average size of the transactions the users will commonly execute.
There are two exceptions to the Rule of Four. The first exception is that if the quotient is less than 4 + 4, round the result of the Rule of Four up to the nearest multiple of 4 and use that number of rollback segments. In this case, the result would be rounded from 6 to 8. The second exception to the Rule of Four is that Oracle generally doesn’t recommend exceeding 50 rollback segments for a database. If the Rule of Four determines that more than 50 rollback segments are needed, the DBA should start by allocating 50 and spend time monitoring the rollback segment wait ratio to see if more should be added later.
To summarize, the Rule of Four is as follows. Take the average number of user transactions that will run on the database at any given time, and divide that number by 4. If the result is less than 4 + 4 (8), round up to the nearest multiple of 4. If the result is over 50, use 50 rollback segments and monitor the wait ratio for the rollback segments to see if there is a need to add more.
In this section, you will cover the following topics related to managing tables and indexes:
| Sizing tables | |
| Sizing indexes | |
| Understanding storage and performance trade-offs | |
| Reviewing space utilization |
Good table and index management is critical to the success of the Oracle database in two ways. First, if tables and indexes are managed poorly, there will be problems with data storage. A database with storage problems has users constantly complaining about tables running out of room, forcing the DBA to reorganizing tablespaces to accommodate unplanned growth. Eventually, the database exceeds disk capacity, forcing the DBA either to make unpleasant performance trade-offs by placing tablespaces on disks in ways that lead to contention problems, or the organization is forced to purchase new hardware to store the growing data. A well-planned database is much easier to manage than one created piecemeal. The following discussion will focus on appropriate sizing for database tables and indexes.
The tables of the database are generally its largest and most important objects. Without tables of data, there is no reason to have anything else set up, because the data is the database. Since tables have the highest storage, access, and maintenance costs, it makes sense for the DBA to plan far in advance to avoid unplanned hardware and support costs. It is far easier to store small amounts of data in large databases and watch them both grow together than it is to retrofit large tables into a small database.
The cornerstone of storage management is managing the data block. There are several different components to a data block, divided loosely into the following areas: header and directory information, row data, and free space. Each block has a special header containing information about it, including information about the table that owns the block and the row data the block contains. Row data consists of the actual rows of each data table or index. Finally, Oracle leaves an amount of space free for each row in a block to expand via data update.
There are several space utilization clauses related to block usage. Two have been covered, pctfree and pctused. The pctfree option specifies a small amount of space that Oracle should leave free when inserting rows in order to accommodate growth later via updates. The pctused option is a threshold percentage of a block that the actual contents of row data must fall below before Oracle will consider the block free for new row inserts. There are two other space utilization clauses to be aware of that control Oracle’s ability to make concurrent updates to a data block. Those clauses are initrans and maxtrans. The initrans option specifies the initial number of transactions that can update the rows in a data block at once, while maxtrans specifies the maximum number of transactions that can perform the same function. For the most part, the default values for each of these options should not be changed. For initrans, the default for tables is 1, while for clustered tables the default is 2.
To estimate storage requirements for a table, several factors must be calculated about its contents. They are 1) estimate a count of the number of rows that will be part of the table, 2) determine the number of rows that will fit into each block, and 3) determine the number of blocks that will comprise the table.
First, the DBA may find it useful to enlist the help of application developers with this task. In many environments, the DBA will not have the extensive application knowledge required to determine the number of rows that will populate the table. The DBA can ensure a more accurate estimate with the developer’s assistance than simply taking a chance. Many DBAs find it useful having developers offer row count forecasts for today, six months out, twelve months out, and two years out. Forecasting growth for tables allows the DBA to prepare the entire database for growth, avoiding the need to make unplanned changes because the original estimate didn’t take into account a factor for growth occurring 12 months down the road. The discussion will help you learn this material with an example: Say the DBA wants to create a table called DRESSES. This table has a row count estimate of 2,000 in 24 months, and three columns, called NAME—a VARCHAR2(10) column, size—a NUMBER column, and description—a VARCHAR2(250) column.
To begin this step, the DBA should review the contents of each data block, along with some size figures attached to the components. The components of a block header, shown in Figure 8-3, include the following items, each listed with size estimates:
| Fixed block header—24 bytes | |
| Variable transaction header—24 bytes * initrans (1 for tables, 2 for clusters) | |
| Table directory—4 bytes | |
| Row directory—4 bytes * number of rows in block |
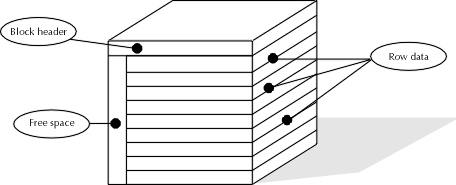
Figure 3: Components of a data block
All told, the space required for a block header is represented by 52 + 4(X), where X equals the number of rows in a block. Notice that the formula for calculating the header size depends on determining the number of rows in each block, which requires estimation. Determining how many rows fit into one block consists of the following steps:
SELECT avg(vsize(column1)), avg(vsize(column2)),
… avg(vsize(columnN))
FROM table;
Resolving step 2.1 requires analysis of the column definition for the table being created. First, it should be noted that each row in an Oracle database has three components: a row header requiring 3 bytes, column data with varying size requirements by datatype, and length bytes for each column, depending on size (1 for columns < 250 bytes, 3 for columns >= 250 bytes). The storage requirements for datatypes are listed below:
| NUMBER—Maximum 21 bytes. | |
| CHAR(n), VARCHAR2(n)—Each character specified in the length as noted by (n) equals 1 byte in single-byte character sets, 2 in multibyte character sets. Maximum 255 for CHAR, 2,000 for VARCHAR2, prior to Oracle8. | |
| DATE—Each date column takes 7 bytes to store. | |
| ROWID—Fixed at 6 bytes in size. | |
| RAW, LONG, LONG RAW—Varies, maximum 2 gigabytes for LONG and LONG RAW, 2,000 bytes for RAW. The DBA may have difficulty sizing these rows, because chaining is inherent in using LONG datatypes in Oracle prior to Oracle8. |
Return now to the example. There will be three columns in the DRESSES table, called NAME—a VARCHAR2(10) column, SIZE—a NUMBER column, and DESCRIPTION—a VARCHAR2(250) column. The maximum row length for this table is calculated as follows:
Step 2.2 gives the DBA an estimated number of rows that fit into one block. This estimate disregards the presence of a row header and free space as specified by pctfree. This step minimizes difficulty in calculating the row count per block. Assuming a 4K database and with Z already calculated, the following estimate is calculated for X:
Step 2.3 can now be accomplished. With an estimate for block row count represented by X, step 2.3 tests the estimate. Assuming pctfree in this database is 10, the following formula is made for Y, bearing in mind the need for the DBA to round X down to the nearest integer:
Step 2.4 is used by the DBA to check her work by multiplying the estimated number of rows per block, X, by the size of each row, Z. If the result is more than Y, the estimated number of rows per block is too high. If this happens, subtract 1 from X and compare Y to (X * Z) again.
The result of the equation is an untrue statement, and therefore the DBA must subtract 1 from X and try again.
The result of the equation is still not true, so the DBA makes one more pass:
Therefore, the number of rows from the DRESSES table that will fit into a block on a 4K database with pctfree set to 10 is 12.
Once the estimated row count for the table and the number of rows that will fit in a block are determined, determining the number of blocks required to store data for the table is a straightforward task. Simply divide the result of Step 1 by the result of Step 2. In the example provided in this discussion, the number of blocks required to store the DRESSES table is 2,000 / 12, or 167 blocks. Multiply that result by DB_BLOCK_SIZE, divided by 1,024 (1,024,000 for megabytes), and the DBA has the size of the table in kilobytes. In this example, the size of the DRESSES table is (167 * 4,096) / 1,024, or 668K.
There are some differences in determining indexes. The first major difference between sizing tables and indexes is the nature of data in the index. Instead of rows, indexes store nodes or entries of column index data from the table in conjunction with a ROWID of where to find the associated table row. The next difference is the size of the fixed block header. As discussed, a table has a fixed block header of 24 bytes and a variable block header whose size depends on the number of rows. Index headers have a slightly larger footprint of 113 bytes, and a fixed header size. The value for initrans in indexes is 2, not 1, so in general the total size of the index block header is 113 + (24 *2), or 161 bytes. Additionally, a node in an index has a header of 2 bytes in length. Recall that a table’s row header length is 3.
Placing these differences into context, revisit the example from the last discussion. The DBA is estimating size required for an index on a non-NULL column in the DRESSES table. Similar to step 1 in the table size estimation process, the DBA now has information for node count, 2,000. The DBA can use the associated row count forecasts for the table to size the index. If the column being indexed contains NULL values, that’s fine, but the DBA should subtract the number of rows containing NULLS from the overall node count for the index before proceeding to step 2.
In step 2, the number of nodes per block for the index is determined. Assume that the index will be composite, and the two elements are of type NUMBER and VARCHAR2(10). For Step 2.1, the length of each node in the index equals node header + ROWID + (column1 length + column2 length … + columnN length) + number of columns, called Z. Note that the ROWID column does not have a length byte associated with it.
The estimated block row count process in step 2.2 is unnecessary for indexes. Since the index block header is static at 161 bytes, the space available in a data block is easier to calculate. With that fact established, the DBA can move onto calculating the free space available in a block for index node data in Step 2.3. Assuming that the DB_BLOCK_SIZE is the same in this example as in the previous example, and that pctfree is also the same, the DBA can make an initial pass at the number of rows in each block. The formula for calculating the number of bytes available for row data equals DB_BLOCK_SIZE - (pctfree(DB_BLOCK_SIZE - 161)), and is called Y. For the example:
Step 2.4 is slightly modified for indexes as well. Since the index block header size is fixed, there is no guesswork in determining the result for step 2. The formula used for determining the number of index nodes in each block is equal to Y / Z.
At this point, the DBA determines the number of blocks required to store the index. There are some important differences again between indexes and tables related to the calculation of total blocks for the index. The first fact is that there will be slightly more blocks in each index than those being used to store index nodes. This fact is true because there are a certain number of special blocks in an index used to join the nodes together in the tree structure that comprises the index. A special multiplier, 1.05, can be used to determine the number of blocks required for the index. The formula for determining the number of blocks required, then, is the result from step 1 divided by the result of step 2, times 1.05. For this example, (2,000 / 90) * 1.05 = 24 blocks. The size in kilobytes can further be determined by taking the size of the index in block, multiplying it by DB_BLOCK_SIZE, and dividing that result by 1,024 (1,024,000 for megabytes). The result for this index in kilobytes is (24 * 4,096) / 1,024, or 96K.
Searching a table without indexes proceeds as follows. The first step is to perform a full table scan. The server process copies every block from the table into the buffer cache, one by one, and searches the contents of each row in the set of criteria given by the user until the entirety of the table is searched. Although a full table scan may only take a short while on a small table, on a large table it can take several minutes or hours. Indexes are designed to improve search performance. Unlike full table scans, whose performance worsens as the table grows larger, the performance increase on table searches that use indexes gets exponentially better as the index (and associated table) gets larger and larger. In fact, on a list containing one million elements, the type of search algorithm used in a B-tree index finds any element in the list within 20 tries. The same search using a full table scan takes anywhere from one to one million tries!
However, there is a price for all this speed, paid in the additional disk space required to store the index. To minimize the trade-off, the DBA must weigh the storage cost of adding an index to the database against the performance gained by having the index available for searching the table. The performance improvement achieved by using an index is exponential over the performance of a full table scan, but there is no value in the index if it is never used by the users.
The first step in determining the value of an index is to identify the columns that SQL statements use to access data in a table. Take, for example, a table called BANK_ACCOUNT, which has an index on the ACCOUNT_NO column. All the SQL statements issued against the table search in EMPID. Even though the index on ACCOUNT_NO provides excellent performance to queries with ACCOUNT_NO in their where clauses, the index provides little performance value overall because no SQL statements against BANK_ACCOUNT use ACCOUNT_NO in their where clauses. Therefore, the storage/performance trade-off would be better resolved with the use of an index on EMPID and EMP_LASTNAME, because the application searches the database on those values. An index does little good if users aren’t using it. Since the DBA cannot simply create indexes on every conceivable column combination to ensure good performance, regardless of the where clause, the only alternative is to look at how the data is selected and index accordingly.
There are other performance trade-offs that the DBA has to consider when creating indexes. Each index on a database creates overhead for Oracle when the user wants to change data in a table. The database must update the table and the index when a record is changed, added, or deleted. Performance on data change, then, is adversely affected by the improvement of query access to the database.
Another area where this type of trade-off is encountered is in the management of space at the block level. Depending on the types of changes to data being made in a table, the DBA may want to adjust options for managing space inside each Oracle data block accordingly. The options for managing storage space within the Oracle database are pctfree and pctused. Their meanings are as follows:
| pctfree specifies a certain amount of space inside each block that remains free when new rows are inserted, in order to allow room for existing rows in the table to increase in size via updates. | |
| pctused specifies a threshold amount of usage under which the space utilization in a data block must fall before Oracle will consider adding more rows to the block. Note that pctused is not used for indexes. |
These two options are treated in tandem. When added together, they should not exceed or even be close to 100. Setting these options in different ways has different effects on the database. A high pctfree will keep a great deal of space free in the database for updates to increase the size of each row. However, this configuration also means that some space in each block will lie dormant until the data updates to the rows utilize the space. Setting the value of pctfree low will maximize the number of rows that can be stored in a block. But, if a block runs out of space to store row data when the row is updated, then Oracle will have to migrate the row data to another block. Row migration degrades performance when the Server process attempts to locate the migrated row, only to find that the row is in another location. Chaining is also detrimental to performance on the database, as the server process must piece together one row of data using multiple disk reads. In addition, there is performance degradation by DBWR when it has to perform multiple disk writes for only one row of data.
Settings for pctused create different effects on storage also. A high value for pctused will ensure that whenever few rows are removed from a data block, the block will be considered free and repopulated in a timely manner. However, this configuration degrades performance by requiring Oracle to keep track of blocks whose utilization falls below pctused, placing the block on a freelist and then taking the block off the freelist after inserting relatively few records into the block. Although space is managed effectively, the database as a whole pays a price in performance. A low pctused changes this situation by putting blocks on freelists only when a lot of row data can be put into the block. However, even this situation has a trade-off, which is if a lot of data is removed from the blocks, but enough to put utilization below pctused, that block will sit underused until enough rows are removed to place it on a freelist.
The DBA may want to specify a high pctfree value and a low pctused for online transaction processing systems experiencing many update, insert, and delete commands. This approach is designed to make room in each block for increased row lengths as the result of frequent updates. In contrast, consider a data warehouse where a smaller numbers of users execute long-running query statements against the database. In this situation, the DBA may want to ensure that space usage is maximized. A low pctfree and high pctused configuration may be entirely appropriate.
In this section, you will cover the following topics related to managing index clusters:
| Identifying the advantages and disadvantages of clusters | |
| Creating index clusters | |
| Using hashes | |
| Creating hash clusters |
For the most part, the users and the DBA on an Oracle database system will find the use of standard tables and indexes to be effective in most situations. However, indexes on standard tables are not the only option available on the Oracle database for managing data to suit performance needs. The discussion in this section will cover some alternatives to traditional tables and indexing. The two options discussed will be clustered tables and hashing. Both of these options have advantages for use in certain, specialized situations. However, they are both somewhat complex to set up in comparison to standard tables and indexes. It is important to know when clustering and hashing will assist performance, but it is perhaps more important to know when hashing and clustering will adversely impact performance as well in order to avoid pitfalls.
Clusters are special configurations for DBAs to use when two or more tables are stored in close physical proximity to improve performance on SQL join statements using those tables. The tables in the cluster share the same data blocks as well as a special index of each table’s common columns. Each unique element in the index is called a cluster key. Ideally, the rows in all tables corresponding to unique elements in the cluster key fit into one data block. The cluster can then offer I/O performance gains even over indexed tables. Even when the common column is indexed in both tables, the Server process still has to perform multiple disk reads to retrieve data for the join. In contrast, the data in a clustered table is read into memory by the server process in only one disk read.
Clusters minimize disk I/O on table joins. Figure 8-4 illustrates the idea behind clustering. Assume that three tables share the same common primary key. The three tables are INVOICE, which stores general information about invoices for each purchase order; INVOICE_ITEM, which stores each line item of the purchase order; and INVOICE_DETAIL, which stores detailed information about each INVOICE_ITEM record, including part number, color, and size.
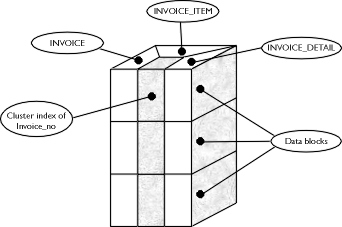
Figure 4: Cluster keys and table distribution in cluster blocks
Since all rows in clustered tables use the same column as the common primary key, the columns are stored only once for all tables, yielding some storage benefit. The use of clustering works well in certain situations, but has limited performance gains in others. First, effective use of cluster segments is limited to tables with static or infrequently inserted, updated, or deleted data. The location of pertinent data from several different tables in one block is the biggest performance advantage cluster segments can offer. Changing data in any of the tables can throw off the tenuous balance of data in each block, potentially negating any performance value a cluster can offer by increasing disk reads. Cluster segments require more maintenance than traditional tables and indexes, especially when data is changed. Additionally, the cluster works best when several rows of data in each of the tables hang off each individual element in the cluster key. If few rows share cluster keys, the space in each block is wasted and additional I/O reads may be necessary to retrieve the data in the cluster. Conversely, cluster keys with too many rows hanging off of them causes additional I/O reads and defeat the purpose of clustering as well.
On the whole, the use of cluster segments is a fairly limited way to achieve performance gains in a few special circumstances. However, the DBA should have a full understanding of the circumstances in which clusters can improve performance, and use clustering effectively when those situations arise.
The DBA should begin the task of creating a cluster by treating all the data in a cluster segment as one unit. Although the logical data model and the applications may continue to treat each component as a table, from a management and maintenance standpoint, the line between each table gets blurry as soon as the tables are clustered. A major aspect of space management, pctfree and pctused, is not available in clusters. In disabling pctfree and pctused clauses for management at the table level, Oracle forces each table to take on the storage management used in the cluster. The cluster’s space management is handled with the size option. The size option is determined by a complex calculation, somewhat like that used for determining an index or table:
As illustrated in the sections on sizing tables and indexes, the space available in each block for data storage can be expressed as DB_BLOCK_SIZE - block header. Since pctfree and pctused are not available on tables in clusters, factoring in pctfree when determining the space available per block is unnecessary. The block header size can be expressed as fixed header + variable header + table directory + row directory. Fixed header size for clusters is operating system specific. The DBA should refer to the components for fixed header size as listed in the V$TYPE_SIZE data dictionary view. For most systems, it will equal 57, while the variable header is determined by 23 times initrans, or 46. The table directory size is expressed by 4T + 1, where T is the number of tables being clustered. The row directory size is determined by 2R, where R is the number of rows per key. To simplify, the block header formula can be expressed as 104 + 4T + 2R, making the total amount of space available in the block for clustered data expressed as DB_BLOCK_SIZE - (104 + 4T + 2R).
The space required for rows associated with cluster keys is determined in the same way as determining the row size for each row in a table. There is one exception—the columns in the cluster key must not be included in the size estimate for each row length for each table; columns in the cluster key are stored only once to support one common index for all rows in the table. The same rules for determining row length in nonclustered tables also apply to clustered tables, including the row header length of 4 bytes, the length byte of 1 for columns under 250 bytes and 3 for columns over 250 bytes in length.
At this point, the DBA should also calculate the number of rows that will hang off each key in the cluster. This is accomplished by determining how many rows are associated with each column in the cluster for each table, then adding the results. For example, if one row in the INVOICE table hangs off the cluster key, and three rows in both the INVOICE_ITEM and INVOICE_DETAIL tables, then a total of seven rows will be associated with each cluster key. Additionally, this step can be used to determine the size of all rows that associate with each key. Row size of each table is indicated by: row header + sum of column lengths except cluster key + sum of all column length bytes except cluster key.
The DBA should note that the space required for columns in the cluster key is determined separately. The cluster key length is determined in the same way as the length of each row in a nonclustered table; however, the cluster key header is 19 bytes. Also, there are no length bytes in the cluster. So, if the length of the cluster key columns is 20, the average size for each cluster key is going to be 39 bytes. This amount is then added to the space required for the size of all rows associated with the index.
After determining the size of each entry in the cluster, the DBA can then determine how many cluster entries will fit into a block. From there, the DBA determines how many blocks are required for the cluster overall. The first task is determined with the original formula representing the size available in each block. The available space is then divided by the size of each cluster element. In order to factor back in the row directory size, multiply the number of cluster elements by the number of rows associated with each cluster key. If 10 cluster elements fit into each block, and each element contains 7 rows, the number of rows overall in the block will then be 7 rows per entry times 10 entries, or 70 rows. The DBA can then factor the number of rows back into the original equation of available space per block.
Usually, there is little room left over in each block for growth. If data is inserted on all three tables with clustered rows around one entry, Oracle may have to migrate or chain row entries for this cluster. As soon as migration or chaining occurs, the performance benefit of clustering tables begins to erode. Therefore, it is best to cluster data only when the tables being clustered are read only or extremely static.
Once space requirement determination is complete and the size value determined, the DBA can then go about creating the cluster in the database. The first step to clustering the three invoice-related tables for our running example is to create the actual cluster segment for the three tables to reside in. This step is accomplished with a create cluster statement.
CREATE CLUSTER invoices_items_detailsWithin the syntax of the cluster creation statement—the presence of pctfree and pctused. Although these options are not available for the individual tables in the cluster, they are available for the cluster as a whole. Thus, space utilization is managed by the cluster. After creating the cluster segment, the DBA can add tables with the create table statement.
CREATE TABLE invoice (
Invoice_id VARCHAR2(20) PRIMARY KEY,
User_account VARCHAR2(9),
Pmt_dttm DATE)
CLUSTER invoices_items_details (invoice_no);
CREATE TABLE invoice_item (
Invoice_id VARCHAR2(20) PRIMARY KEY,
Part_id VARCHAR2,
Item_amount NUMBER)
CLUSTER invoices_items_details (invoice_no);
CREATE TABLE invoice_detail (
Invoice_id VARCHAR2(20) PRIMARY KEY,
Prchs_address VARCHAR2(20),
Purchaser_zip VARCHAR2(10))
CLUSTER invoices_items_details (invoice_no);
The next step is crucial to the placement of data into the cluster. Without completing this step, the cluster is unusable, even if the table definitions and cluster definitions are in place. In order to place data in the cluster, the DBA must create the cluster key index.
CREATE INDEX invoices_items_details_01
ON CLUSTER invoices_items_details
TABLESPACE data_clusters_02
STORAGE ( INITIAL 1M NEXT 1M
MINEXTENTS 2 MAXEXTENTS 50
PCTINCREASE 50) PCTFREE 5;
After the index is created, the DBA can load data into the table with SQL*Loader or with some other mechanism for batch update. At that point, the DBA should strongly consider some form of control for limiting the amount of user update to the tables in the cluster. This task can be accomplished either by setting the tablespace containing the cluster to read only availability, limiting user update capability with the application, or via policy.
Configuring and using clusters can be complex. There are several calculations along the way that have difficult-to-find values plugged into them. After the initial determination that clustering is appropriate for this group of tables, the DBA must spend time carefully considering the implications of sizing various elements. In order to simplify the process, the following principles are offered:
| Determine the number of rows that will be associated with the cluster key first. This is a crucial element that, in the absence of completing other elements, can still help the DBA create a reasonable estimate for the cluster size. | |
| Remember not to include the cluster key columns in the estimation of the size for each row of the table. Although the cluster key columns appear in several different tables, the data for the key is stored only once. Calculating the columns in with the table row lengths will unnecessarily overestimate the size of each cluster entry. | |
| Information for most of the block header components is operating system specific, and can be found in the V$TYPE_SIZE view of the Oracle data dictionary. | |
| The cluster index must be created before the cluster data is populated. | |
| The pctfree and pctused options for each table default to the values set for the cluster, which makes sense because all tables being stored in a cluster are treated as one object. | |
| Attempts to issue alter table statements that assign values for storage options for the table, such as pctfree, initrans, or pctincrease, will result in an error. | |
| In all attempts to create a cluster, bear in mind the principles of performance improvement the cluster is designed to make. |
Another option available for improving performance by placing data in close proximity is called hashing. Normal clustering works on the principle of hanging the data from several different tables together with one common index, and then searching the index when data from the cluster is needed. The performance improvement it offers is on disk I/O. Hashing is designed to enhance performance even more. The implementation of hashing adds two new items to the creation of a cluster—a hash key and a hash function. The hash key represents a special address in memory that corresponds to each unique cluster key value. When a user process looks for data in a hash cluster, the required data is converted into the hash key by means of the hash function. The result is an address on disk that tells Oracle exactly where to find the data requested by the user process. Ideally, performance in hash clusters can be so effective as to enable the database to retrieve requested data in as little as one disk read.
Hash clustering can be a very useful performance enhancement to a database. However, the DBA needs to understand when hash clusters are appropriate. In addition to restrictions on regular clusters, such as creating clusters on tables with static data, the hash cluster is only effective when the types of queries executed against it contain equality operations in their where clauses. Figure 8-5 demonstrates inappropriate selection of data from a hash cluster.

Figure 5: select statements that use ranges are not appropriate in hashing
There are other restrictions that apply to hashing. The size and number of rows in tables in the hash cluster must be stable. A change in row data can produce data migration or chaining, which erodes the performance of the hash cluster. Also, all tables in the cluster should be searched via the cluster key. If a user process attempts to select data on columns not in the cluster key, the performance of the query will be worse than if the table was not clustered. Hash clusters also require lots of disk space and should not be used when storage is tight.
Sizing hash cluster requirements is similar to sizing regular clusters, with the following exception. There is an additional factor for creating a set of hash key values to which the cluster keys of the hash cluster will map. The number of hash keys should correspond to the number of blocks that are used to store the cluster. Therefore, determining the number of blocks containing cluster data is required in order to specify the hash key clause. Once sizing for a hash key is complete, the DBA then creates a hash cluster for the tables being clustered in the same way as the regular cluster is created, with the following addition to the storage clause of the cluster:
…
STORAGE ( INITIAL 1M NEXT 1M
MINEXTENTS 2 MAXEXTENTS 100
PCTINCREASE 50) SIZE 400
HASHKEYS 250;
In situations where the cluster key is of the NUMBER datatype and consists of only one column, and the cluster key is a list of unique sequential or uniformly stepped integers, the DBA can use the hash is clause to name the cluster key. This clause names the column on which the hashing function can be applied directly in order to produce the hash key equivalent used by Oracle to find the exact block on disk where the rows corresponding to the result set of each query using the hash cluster will reside.
A well-estimated hash key size reduces the number of times a hash function is applied incorrectly onto the value in the where clause requested in the query to find data in the hash cluster. This situation is called a collision, or an incident where the hash function generates an incorrect location based on the where clause value appearing in different blocks. One tip Oracle recommends with respect to setting the hashkeys option to allow for good distribution of keys across the hash cluster is to set hashkeys equal to a prime number.
If the DBA thinks cluster creation is hard, the complexity of hash clustering can encourage the DBA not to use hashing on his databases. Even when the mechanisms for creating a hash cluster are well-understood, there are still compelling reasons not to use hash clusters. For one thing, the performance improvements made as part of hashing can easily be diminished when considered in light of the increased storage burden for hash clustering. Hash clusters require as much as 50 percent more space to store the same amount of data as would be required if the tables in the hash cluster were placed into nonclustered tables with associated indexes. Moreover, the user would have more flexibility with nonclustered tables by querying the data using methods other than equality operations in the where clause and for inserting, updating, and deleting data than with hash clusters. Data in hash clusters must be absolutely static. However, although the scope is limited, there is often opportunity to use hash clustering on data warehouses with read only data. In these situations, hash clustering can yield dramatic performance results.
In this section, you will cover the following topics related to managing data integrity constraints:
| Types of declarative integrity constraints | |
| Constraints in action | |
| Managing constraint violations | |
| Viewing information about constraints |
One of Oracle’s greatest assets is its ability to manage data integrity from within the object definition of a table. The use of declarative integrity constraints allows the DBA to specify all but the most complicated data integrity rules in the database at the table definition level. Furthermore, the existence of declarative integrity constraints allows the DBA to view all constraints defined on the database easily using data dictionary views rather than by sorting through sometimes complex PL/SQL blocks contained in triggers throughout the database. Finally, declarative constraints allow for several different types of integrity checking, from simple valid value references, to uniqueness within a table, to foreign-key lookups in other tables. However, declarative constraints cannot do everything. For example, a declarative constraint cannot perform a foreign-key verification operation on different tables in the database depending on the value specified in the column. Additionally, a declarative integrity constraint cannot perform a PL/SQL operation, nor can it insert data into another table if the data does not exist there already. However, most business rules can be modeled using declarative integrity constraints if the logical data model is constructed well.
Several different options exist in Oracle for declarative integrity constraints. The first type of integrity constraint available in the Oracle architecture, and perhaps most central to the theory of relational databases, is the primary-key constraint. The primary key of a database table is the unique identifier for that table that distinguishes each row in the table from all other rows. A primary-key constraint consists of two data integrity rules for the column declared as the primary key:
| Every value in the column declared to be the primary key must be unique in the database. | |
| No value in the column declared to be the primary key is permitted to be NULL. |
Primary keys are considered to be the backbone of the table. As such, the DBA should choose the primary key for a table carefully. The column or columns defined to be the primary key should reflect the most important piece of information that is unique about each row of the table. Primary keys are one of two integrity constraints in the Oracle database that are created with an associated index. This index helps to preserve the uniqueness of the primary key and also facilitates high-performance searches on the table whenever the primary key is named in the where clause.
The next integrity constraint to be discussed is the foreign-key constraint. The DBA should ensure that foreign keys on one table refer only to primary keys on other tables. The creation of a foreign-key constraint from one table to another defines a special relationship between the two tables that is often referred to as a parent-child relationship. The parent table is the one referred to by the foreign key, while the child table is the table that actually contains the foreign key. In order to better understand this relationship, refer to Figure 8-6. Unlike primary-key constraints, defining a foreign-key constraint on a column does not prevent user processes from setting the value in the foreign-key column of the child table to NULL. In cases where the column is NULL, there will be no referential integrity check between the child and the parent.
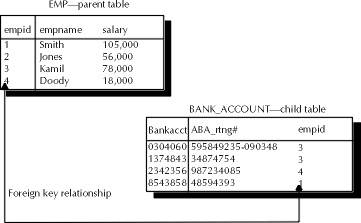
Figure 6: Creating parent-child table relationships using foreign keys
A third type of integrity constraint available in Oracle is the unique constraint. Like the primary key, a unique constraint ensures that all values in the column that the unique constraint is defined on are not duplicated by other rows. In addition, unique constraints are the only other type of constraint that has an associated index created with it when the constraint is named. The fourth integrity constraint defined on the Oracle database is the NOT NULL constraint. This constraint ensures that NULL cannot be specified as the value for a column on which the NOT NULL constraint is applied.. Often, the DBA will define this constraint in conjunction with another constraint. For example, the NOT NULL constraint can be used with a foreign-key constraint to force validation of column data against a "valid value" table. Also, the NOT NULL constraint and a unique constraint are defined together on the same columns—they provide the same functionality as a primary key.
The final type of integrity constraint that can be defined on a database is the check constraint. Check constraints allow the DBA to specify a set of valid values allowed for a column, which Oracle will check automatically when a row is inserted with a non-NULL value for that column. This constraint is limited to hard-coded valid values only. In other words, a check constraint cannot "look up" its valid values anywhere, nor can it perform any type of SQL or PL/SQL operation as part of its definition.
Constraint definitions are handled at the table definition level, either in a create table or alter table statement. Whenever a constraint is created, it is enabled automatically unless a condition exists on the table that violates the constraint. If this is the case, then the constraint is created with a disabled status and the rows that violated the constraint are written to a special location. The data in a table should not be populated before the primary key is created.
The primary key is defined with the constraint clause. A name must be given to the primary key in order to name the associated index. The type of constraint is defined on the next line. The type of constraint defined with this clause will either be a primary key, foreign key, unique, or check constraint. The tablespace to which the associated index will be created is named in the using tablespace clause. Oracle allows the DBA to specify a separate tablespace for indexes and the tables for which they index because it improves performance on select statements if the index and table data are in separate tablespaces on different disks. The code block below illustrates the creation of a table with constraints defined:
CREATE TABLE emp
( empid NUMBER NOT NULL,
empname VARCHAR2(30) NOT NULL,
salary NUMBER NOT NULL,
CONSTRAINT pk_emp_01
PRIMARY KEY (empid)
USING TABLESPACE indexes_01)
TABLESPACE data_01;
A foreign key is also defined in the create table or alter table statement. The foreign key in one table refers to the primary key in another, which is sometimes called the parent key. Another clause, on delete cascade, is purely optional. When included, it tells Oracle that if any deletion is performed on EMP that causes a bank account to be orphaned, the corresponding row in BANK_ACCOUNT with the same value for EMPID will also be deleted. Typically, this relationship is desirable because the BANK_ACCOUNT table is the child of the EMP table. If the on delete cascade option is not included, then deletion of a record from EMP that has a corresponding child record in BANK_ACCOUNT with the EMPID defined will not be allowed. Additionally, in order to link two columns via a foreign-key constraint, the names do not have to be the same, but the datatype for each column must be identical.
CREATE TABLE bank_account
(bank_acct VARCHAR2(40) NOT NULL,
aba_rtng_no VARCHAR2(40) NOT NULL,
empid NUMBER NOT NULL,
CONSTRAINT pk_bank_account_01
PRIMARY KEY (bank_acct)
USING TABLESPACE indexes_01,
CONSTRAINT fk_bank_account_01
FOREIGN KEY (empid) REFERENCES (emp.empid)
ON DELETE CASCADE)
TABLESPACE data_01;
The method used to define a NOT NULL constraint is as follows. The existence of this clause in the definition of the table will ensure that the value for this column inserted by any row will never be NULL. In order to illustrate the definition and usage of the NOT NULL constraint, consider the data definition statement below, which is identical to the statement used to illustrate the foreign-key constraint. However, this time the definition for the NOT NULL constraint is highlighted.
CREATE TABLE bank_account
(bank_acct VARCHAR2(40) NOT NULL,
aba_rtng_no VARCHAR2(40) NOT NULL,
empid NUMBER NOT NULL,
CONSTRAINT pk_bank_account_01
PRIMARY KEY (bank_acct)
USING TABLESPACE indexes_01,
CONSTRAINT fk_bank_account_01
FOREIGN KEY (empid) REFERENCES (emp.empid)
ON DELETE CASCADE)
TABLESPACE data_01;
Defining a unique constraint is handled as follows. The DBA decides to track telephone numbers in addition to all the other data traced in EMP. The alter table statement can be issued against the database. As in a primary key, an index is created for the purpose of verifying uniqueness on the column. That index is identified with the name given to the constraint.
ALTER TABLE emp
ADD (home_phone VARCHAR2(10),
CONSTRAINT uk_emp_01
UNIQUE (home_phone));
The final constraint considered in this example is the check constraint. The fictitious company using the EMP and BANK_ACCOUNT tables from above places a salary cap on all employees of $110,000 per year. In order to mirror that policy, the DBA issues the following alter table statement. The constraint takes effect as soon as the statement is issued. If there exists a row in the table whose value for the column with a check constraint against it violates the constraint, the constraint remains disabled.
ALTER TABLE emp
ADD CONSTRAINT ck_emp_01
CHECK (salary <=110000);
The only foolproof way to create a constraint without experiencing violations on constraint creation is to create the constraint before any data is inserted. If this is not done, then the DBA must know how Oracle works with constraint violations. The first and most important step to managing the violations that may arise from creating constraints on tables with data already populated is to create a special table called EXCEPTIONS by running a script provided with the Oracle software distribution called utlexcpt.sql. This file is usually found in the rdbms/admin subdirectory under the Oracle software home directory.
EXCEPTIONS contains a column for the ROWID of the row that violated the constraint and the name of the constraint it violated. In the case of constraints that are not named explicitly by the DBA, such as NOT NULL, the constraint name is listed that was automatically created by Oracle at the time the constraint was created. One method the DBA can use to discover the root cause of the problem is to review the constraints created against the database to determine which constraints are disabled by attempting to reenable the constraint with the exceptions into clause.
ALTER TABLE table_name
ENABLE CONSTRAINT constraint_name
EXCEPTIONS INTO exceptions;
This statement will cause the constraint to fail again and place each ROWID for offending rows into the EXCEPTIONS table. The DBA can then issue a select statement on the EXCEPTIONS table. By substituting the column name above with the column on which the disabled constraint was defined, the DBA should have a better understanding of the problem that caused the constraint to remain disabled after database creation.
SELECT e.constraint, x.column_name, …
FROM exceptions e, table_name x
WHERE e.row_id = x.rowid;
In order to correct the problem, the DBA must change the data in the offending row to be in compliance with the constraint, or remove the offending row. This step is accomplished by issuing an update or delete, with the ROWID of the offending row specified either explicitly in the where clause or via a join statement with the EXCEPTIONS table.
There are several ways to access information about constraints. Many of the data dictionary views present various angles on the constraints. Although each of the views listed are prefixed with DBA_, the views are also available in the ALL_ or USER_ flavors, with data limited in the following ways. ALL_ views correspond to the data objects, privileges, etc. that are available to the user who executes the query, while the USER_ views correspond to the data objects, privileges, etc. that were created by the user.
| DBA_CONSTRAINTS Lists detailed information about all constraints in the system. The constraint name and owner of the constraint are listed, along with the type of constraint it is, the status, and the referenced column name and owner for the parent key if the constraint is a foreign-key constraint. One weakness lies in this view—if trying to look up the name of the parent table for the foreign-key constraint, the DBA must try to find the table whose primary key is the same as the column specified for the referenced column name. | |
| DBA_CONS_COLUMNS Lists detailed information about every column associated with a constraint. The view includes the name of the constraint and the associated table, as well as the name of the column in the constraint. If the constraint is composed of multiple columns, as can be the case in primary, unique, and foreign keys, the position or order of the columns is specified by a 1,2,3,…n value in the POSITION column of this view. Knowing the position of a column is especially useful in tuning SQL queries to use composite indexes, when there is an index corresponding to the constraint. | |
| DBA_INDEXES Lists more detailed information about all indexes in the database, including indexes created for constraints. Most of the information about constraints that are indexed, including the position of the column in the composite index, is duplicated in the DBA_CONS_COLUMNS view. However, for the DBA who needs more detailed information about the indexed constraint( perhaps to determine if there is a problem with the index), this is the data dictionary view to use. |
This chapter covered topics related to database administration of database objects in the Oracle architecture. The areas covered are management of tables and indexes, management of the two types of cluster segments (regular and hash), the management of rollback segment resources that allow for transaction processing, and creation of integrity constraints that aid in storing the right data on the database. These sections comprise material representing 27 percent of questions asked on the OCP Exam 2.
The first area covered is management of rollback segments. These database objects facilitate transaction processing by storing entries related to uncommitted transactions run by user processes on the Oracle database. Each transaction is tracked within a rollback segment by means of a system change number, also called an SCN. Rollback segments can be in several different modes, including online (available), offline (unavailable), pending offline, and partly available. When the DBA creates a rollback segment, the rollback segment is offline, and must be brought online before processes can use it. Once the rollback segment is online, it cannot be brought offline until every transaction using the rollback segment has completed.
Rollback segments must be sized appropriately in order to manage its space well. Every rollback segment should consist of several equally sized extents. Use of the pctincrease storage clause is not permitted with rollback segments. The ideal usage of space for a rollback segment is for the first extent of the rollback segment to be closing its last active transaction as the last extent is running out of room to store active transaction entries, in order to facilitate reuse of allocated extents before obtaining new ones.
The size of a rollback segment can be optimized to stay around a certain number of extents with use of the optimal clause. If the optimal clause is set and a long-running transaction causes the rollback segment to allocate several additional extents, Oracle will force the rollback segment to shrink after the long-running transaction commits. The size of a rollback segment should relate to both the number and size of the average transactions running against the database. Additionally, there should be a few large rollback segments for use with long-running batch processes inherent in most database applications. Transactions can be explicitly assigned to rollback segments that best suit their transaction entry needs with use of the set transaction use rollback segment.
At database startup, at least one rollback segment must be acquired. This rollback segment is the system rollback segment that is created in the SYSTEM tablespace as part of database creation. If the database has more than one tablespace, then two rollback segments must be allocated. The total number of rollback segments that must be allocated for the instance to start is determined by dividing the value of the TRANSACTIONS initialization parameter by the value specified for the TRANSACTIONS_PER_ROLLBACK_SEGMENT parameter. Both of these parameters can be found in the init.ora file. If there are specific rollback segments that the DBA wants to acquire as part of database creation, the names of those rollback segments can be listed in the ROLLBACK_SEGMENTS parameter of the init.ora file. To determine the number of rollback segments that should be created for the database, use the Rule of Four. Divide the average number of concurrent transactions by 4. If the result is less than 4 + 4, or 8, then round it up to the nearest multiple of 4. Configuring more than 50 rollback segments is generally not advised except under heavy volume transaction processing. The V$ROLLSTAT and V$WAITSTAT dynamic performance views are used to monitor rollback segment performance.
The next area discussed is management and administration of tables and indexes. These two objects are the lifeblood of the database, for without data to store there can be no database. Table and index creation must be preceded by appropriate sizing estimates to determine how large a table or index will get. Sizing a table is a three-step process: 1) determining row counts for the table, 2) determining how many rows will fit into a data block, and 3) determining how many blocks the table will need. Step 1 is straightforward—the DBA should involve the developer and the customer where possible and try to forecast table size over 1–2 years in order to ensure enough size is allocated to prevent a maintenance problem later. Step 2 requires a fair amount of calculation to determine two things—the amount of available space in each block and the amount of space each row in a table will require. The combination of these two factors will determine the estimate of the number of blocks the table will require, calculated as part of step 3.
Sizing indexes uses the same procedure for index node entry count as the estimate of row count used in step 1 for sizing the index’s associated table. Step 2 for sizing indexes is the same as for tables—the amount of space available per block is determined, followed by the size of each index node, which includes all columns being indexed and a 6-byte ROWID associated with each value in the index. The two are then combined to determine how many nodes will fit into each block. In step 3, the number of blocks required to store the full index is determined by determining how many blocks are required to store all index nodes; then, that number is increased by 5 percent to account for the allocation of special blocks designed to hold the structure of the index together.
The principle behind indexes is simple—indexes improve performance on table searches for data. However, with the improvement in performance comes an increase in storage costs associated with housing the index. In order to minimize that storage need, the DBA should create indexes that match the columns used in the where clauses of queries running against the database. Other storage/performance trade-offs include use of the pctincrease option. Each time an extent is allocated in situations where pctincrease is greater than zero, the size of the allocated extent will be the percentage larger than the previous extent as defined by pctincrease. This setup allows rapidly growing tables to reduce performance overhead associated with allocating extents by allocating larger and larger extents each time growth is necessary. One drawback is that if the growth of the table were to diminish, pctincrease may cause the table to allocate far more space than it needs on that last extent.
Space within a table is managed with two clauses defined for a table at table creation. Those clauses are pctfree and pctused. The pctfree clause specifies that a percentage of the block must remain free when rows are inserted into the block to accommodate for growth of existing rows via update statements. The pctused clause is a threshold value under which the capacity of data held in a block must fall in order for Oracle to consider the block free for inserting new rows. Both pctfree and pctused are generally configured together for several reasons. First, the values specified for both clauses when added together cannot exceed 100. Second, the types of activities on the database will determine the values for pctfree and pctused. Third, the values set for both clauses work together to determine how high or low the costs for storage management will be.
High pctfree causes a great deal of space to remain free for updates to existing rows in the database. It is useful in environments where the size of a row is increased substantially by frequent updates. Although space is intentionally preallocated high, the overall benefit for performance and storage is high as well, because chaining and row migration will be minimized. Row migration is when a row of data is larger than the block can accommodate, so Oracle must move the row to another block. The entry where the row once stood is replaced with its new location. Chaining goes one step further to place pieces of row data in several blocks when there is not enough free space in any block to accommodate the row.
Setting pctfree low means little space will be left over for row update growth. This configuration works well for static systems like data warehouses where data is infrequently updated once populated. Space utilization will be maximized, but setting pctfree in this way is not recommended for high update volume systems because the updates will cause chaining and row migration. High pctused means that Oracle should always attempt to keep blocks as filled as possible with row data. This setup means that in environments where data is deleted from tables often, the blocks having row deletion will spend short and frequent periods on the table’s freelist. A freelist is a list of blocks that are below their pctused threshold, and that are available to have rows inserted into them. Moving blocks onto and off of the freelists for a table increases performance costs and should be avoided. Low pctused is a good method to prevent a block from being considered "free" before a great deal of data can be inserted into it. Low pctused improves performance related to space management; however, setting pctused too low can cause space to be wasted in blocks.
Typically, regular "nonclustered" tables and associated indexes will give most databases the performance they need to access their database applications quickly. However, there are certain situations where performance can be enhanced significantly with the use of cluster segments. A cluster segment is designed to store two or more tables physically within the same blocks. The operating principle is that if there are two or more tables that are joined frequently in select statements, then storing the data for each table together will improve performance on statements that retrieve data from them. Data from rows on multiple tables correspond to one unique index of common column shared between the tables in the cluster. This index is called a cluster index. A few conditions for use apply to clusters. Only tables that contain static data and are rarely queried by themselves work well in clusters. Although tables in clusters are still considered logically separate, from a physical management standpoint they are really one object. As such, pctfree and pctused options for the individual tables in a cluster defer to the values specified for pctfree and pctused for the cluster as a whole. However, some control over space usage is given with the size option used in cluster creation. In order to create clusters, the size required by the clustered data must be determined. The steps required are the same for sizing tables, namely 1) the number of rows per table that will be associated to each member of the cluster index, called a cluster key; 2) the number of cluster keys that fit into one data block will be determined; and 3) the number of blocks required to store the cluster will also be determined. One key point to remember in step 2 is that the row size estimates for each table in the cluster must not include the columns in the cluster key. That estimate is done separately. Once sizing is complete, clusters are created in the following way: 1) create the cluster segment with the create cluster command; 2) add tables to the cluster with the create table command with the cluster option; 3) create the cluster index with the create index on cluster command, and lastly, 4) populate the cluster tables with row data. Note that step 4 cannot happen before step 3 is complete.
Clusters add performance value in certain circumstances where table joins are frequently performed on static data. However, for even more performance gain, hash clustering can be used. Hashing differs from normal clusters in that each block contains one or more hash keys that are used to identify each block in the cluster. When select statements are issued against hash clusters, the value specified by an equality operation in the where clause is translated into a hash key by means of a special hash function, and data is then selected from the specific block that contains the hash key. When properly configured, hashing can yield required data for a query in as little as one disk read. There are two major conditions for hashing—one is that hashing only improves performance when the two or more tables in the cluster are rarely selected from individually, and joined by equality operations (column_name = X, or a.column_name = b.column_name, etc.) in the where clause exclusively. The second condition is that the DBA must be willing to make an enormous storage trade-off for that performance gain—tables in hash clusters can require as much as 50 percent more storage space than comparably defined nonclustered tables with associated indexes.
The final area of this chapter is the use of declarative constraints in order to preserve data integrity. In many database systems, there is only one way to enforce data integrity in a database—define procedures for checking data that will be executed at the time a data change is made. In Oracle, this functionality is provided with the use of triggers. However, Oracle also provides a set of five declarative integrity constraints that can be defined at the data definition level. The five types of integrity constraints are 1) primary keys, designed to identify the uniqueness of every row in a table; 2) foreign keys, designed to allow referential integrity and parent/child relationships between tables; 3) unique constraints, designed to force each row’s non-NULL column element to be unique; 4) NOT NULL constraints, designed to prevent a column value from being specified as NULL by a row; and 5) check constraints, designed to check the value of a column or columns against a prescribed set of constant values. Two of these constraints—primary keys and unique constraints—have associated indexes with them.
Constraints have two statuses, enabled and disabled. When created, the constraint will automatically validate every column in the table associated with the constraint. If no row’s data violates the constraint, then the constraint will be in enabled status when creation completes. If a row violates the constraint, then the status of the constraint will be disabled after the constraint is created. If the constraint is disabled after startup, the DBA can identify and examine the offending rows by first creating a special table called EXCEPTIONS by running the utlexcpt.sql script found in the rdbms/admin directory under the Oracle software home directory. Once EXCEPTIONS is created, the DBA can execute an alter table enable constraints exceptions into statement, and the offending rows will be loaded into the EXCEPTIONS table. To find information about constraints, the DBA can look in DBA_CONSTRAINTS and DBA_CONS_COLUMNS. Additional information about the indexes created by constraints can be gathered from the DBA_INDEXES view.
| Rollback segments allow transaction processing to occur by storing changes to the database before they are actually written to the database. | |
| Rollback segments should consist of equally sized extents. | |
| pctincrease is not permitted on rollback segments. | |
| Rollback segments must be brought online in order to use them. | |
| A rollback segment cannot be taken offline until such time as all active transactions writing rollback entries have completed. | |
| Entries are associated with transactions in the rollback segment via the use of a system change number. (SCN). | |
| When the Parallel Server option is used, the number of public rollback segments allocated by Oracle when the database is started is equal to the quotient of TRANSACTIONS/TRANSACTIONS_PER_ROLLBACK_ SEGMENT. | |
| Specific private rollback segments can be allocated at startup if they are specified in the ROLLBACK_SEGMENTS parameter in init.ora. | |
| Number of rollback segments required for an instance is determined by the Rule of Four—divide concurrent user processes by 4; if result is less than 4 + 4, round up to the nearest multiple of 4. Use no more than 50 rollback segments. | |
| Monitor performance in rollback segments with V$ROLLSTAT and V$WAITSTAT. | |
| Table creation and index creation depends on proper sizing. | |
| Three steps for determining size are as follows: |
| The components of a database block that affect how much space is available for row entries are: fixed block header, variable block header, table directory, and row directory. Another factor influencing space for row entries is the pctfree option. | |
| Determining space requirements for indexes is accomplished by the following: |
| The number of blocks required to store an index is equal to the number of blocks required to store an index node, plus an additional 5 percent for linking blocks used in the index framework. | |
| Clusters improve performance on queries that join two or more tables with static data by storing related data from the tables in the same physical data blocks. This reduces the number of I/O reads required to retrieve the data. | |
| Determining space requirements for clusters is accomplished by the following: |
| Clusters should not be used to store tables whose data is dynamic or volatile. | |
| The steps to create a cluster once proper sizing has taken place are as follows: |
| In order to further improve performance on table joins, the DBA can set up hash clustering on the database. | |
| Hash clustering is the same as regular clusters in that data from multiple tables are stored together in data blocks, but different in that there is an additional key to search for data, called a hash key. | |
| Data is retrieved from a hash cluster by Oracle applying a hash function to the value specified in equality operations in the where clause of the table join. Ideally, this allows for data retrieval in one disk read. | |
| Hash clusters only improve performance on queries where the data is static, and the select statements contain table joins with equality operations only. Range queries are not allowed. | |
| Data integrity constraints are declared in the Oracle database as part of the table definition. | |
| There are five types of integrity constraints: | |
| Primary key—identifies each row in the table as unique. | |
| Foreign key—develops referential integrity between two tables. | |
| Unique—forces each non-null value in the column to be unique. | |
| Not null—forces each value in the column to be not null. | |
| Check—validates each entry into the column against a set of valid value constants. | |
| When a constraint is created, every row in the table is validated against the constraint restriction. | |
| The EXCEPTIONS table stores rows that violate the integrity constraint created for a table. | |
| The EXCEPTIONS table can be created by running the utlexcpt.sql script. | |
| The DBA_CONSTRAINTS and DBA_CONS_COLUMNS data dictionary views display information about the constraints of a database. |