In this chapter, you will understand and demonstrate knowledge in the following areas:
| Parallel DML in Oracle8 | |
| The LOB datatypes | |
| Advanced queuing with DBMS_QUEUE |
Oracle8 supports new features in several other areas as well. To support new levels of VLDB administration, Oracle8 has some major enhancements to improve performance on insert, update, and delete statements on Oracle tables by making it possible for Oracle to process these statements in parallel. In Oracle7, only select statements could be processed in parallel. Oracle8 also supports new datatypes for large objects, the class of which is called LOBs. These LOBs are the designed to support next-generation databases that use multimedia objects such as text, graphics, sound, and video. Although the predecessors to LOB datatypes, LONG and LONG RAW, are still supported in Oracle8 as they were in Oracle7, the emphasis in Oracle8 is on the LOB types. This is because LOB types are more versatile and integrate more effectively into Oracle8’s other major advancement—object relational database development features. Finally, several new features have been added to Oracle8 to support the implementation of asynchronous execution of database operations, called queuing. These features are discussed in this chapter as well. Study of these areas will assist in your preparation for OCP Exam 5.
In this section, you will cover the following topics related to parallel DML in Oracle8:
| Advantages of using parallel DML | |
| Enabling and using parallel DML | |
| Restrictions on using parallel DML | |
| Dictionary views on parallel DML |
The first section of this chapter covers parallel DML. The overall use of parallelism in Oracle8 has increased dramatically in support of large database environments, as given evidence by the treatment of partitioned tables in Chapter 21. This increase is due to the increase in database size as a whole, both in data warehouses and in OLTP applications. As Oracle database applications advance in the organization, they also grow. Although most organizations shouldn’t ever feel too constrained by the 512 petabyte size limit for Oracle8, even the data warehouse of 20 gigabytes may seem unwieldy with several database objects whose size is measured in hundreds of megabytes. Oracle7 may have difficulty accessing data in those databases as well, given the limited ROWID structure. In contrast, accessing data in Oracle8 should offer some relief with partitioning and the new ROWID structure already discussed. Oracle8 also improves the ability of users to put data into the database efficiently with parallel DML.
In large databases that store gigabytes of data, a single large DML operation may affect tens of thousands of rows. In data warehouse or decision support systems, where data is fed to the system in batch cycles, these updates may take several minutes to hours. Even well-tuned SQL update, insert, or delete statements may take a long time if the amount of data is being changed is large. Though usually the amount of data being changed per statement is small in an OLTP application, there may be some situations where large amounts of data are changed at once, perhaps in a data feed operation where status on row data must be updated to reflect the feed. Parallel DML is designed to improve the overall performance of large data change operations in conjunction with the use of partitioned tables, although the insert as select statement is optimized to provide parallelism even on a nonpartitioned table.
Consider the performance gains granted with the use of parallel DML. A great deal of performance gained with parallel DML depends on the ability of the machine hosting Oracle to support parallel DML operations. The requirements for parallel DML include more memory to support additional I/O processes running and more CPUs to process data spread across multiple disk drives.
Parallel DML has another advantage in that Oracle8 supports it readily, without extra setup and intervention from the developer. In Oracle7, the degree of parallelism to which DML operations could be performed was up to the developer’s ability to divide the data change activity across multiple sessions using ROWID or key information. Since there is no support for multisession transactions in Oracle, the developer had to manage the data change actively, checking each session to verify the success or correct the failure of each individual piece of the parallel operation. Since parallel DML is supported within one statement running in one session, the developer can define a transaction around the parallel operation. Within parallel configurations, parallel DML can run even faster because the degree of parallelism can be duplicated automatically by the number of instances connected to the same Oracle database. Parallel processes that are used in the Oracle database include parallel query, parallel insert as select statements on both partitioned and nonpartitioned tables, and parallel update and delete statements on partitioned tables.
Parallelism operates in different ways for different statements and in different situations. The parallel query option introduced in Oracle7 improves performance for select statements, resulting in full table scans by dissecting requested data by ROWID and directing multiple I/O processes to obtain one of the required ranges. This division of data to be selected allows Oracle to run queries in parallel, even if the parallel operations obtaining data must work on the same partition on a partitioned table or in a nonpartitioned table. Each I/O process is limited to only one partition, and cannot span partitions.
In order to process update, delete, and insert as select statements in parallel on multiple table partitions, Oracle maps a disk device to a partition. The closer the DBA can make the device-to-partition mapping one to one, the more effective parallel DML should operate. The parallelism in this setup is based on the number of partitions available, whereas in the other situations parallelism is defined for within partitions. Thus, in this situation, a maximum of only one slave process may operate on any single partition on behalf of the DML statement.
Finally, for insert as select statements to run in parallel on nonpartitioned tables, multiple I/O processes are generated and Oracle divides the number of rows to be inserted among the I/O processes equitably. These I/O processes insert data into the tables in the same way that SQL*Loader’s direct path data load: data is put into the table over the high watermark. However, since the parallel DML statement operates as a transaction, a commit resets the high watermark rather than a data save. For more on the direct path data load in SQL*Loader, review Chapter 10. Figure 23-1 illustrates the three methods Oracle8 introduces for parallel database operation.
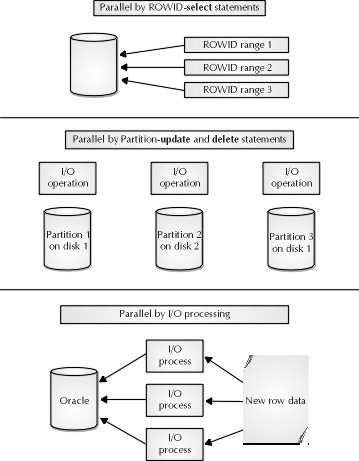
Figure 1: Three methods for parallel data operations
Parallel DML is enabled on a session level using the alter session enable parallel DML statement. To disable parallel DML, the same alter session statement can be issued with the disable rather than enable keyword. A select statement runs in parallel independently of enabling or disabling parallel DML, so parallel query will continue to function even when parallel DML is disabled. Parallel DML cannot be set on an instance-wide level, so the user must remember to issue the alter session statement before attempting to execute parallel DML. The parallel DML statement constitutes the end of the database change portion of a transaction. No select or DML activity can occur until the parallel DML transaction is ended either with the commit or rollback statement; otherwise, an error will occur.
The parallelism used by DML statements can be defined by the table at the time the table is created. The parallel options specified in the create table statement indicate the use of parallelism in the DML and select statements later. The following code block illustrates the definition of parallelism for the table creation. Note that the DBA can use the default keyword in the definition of degree and instances as part of the parallel clause rather than specifying a number. Also, the noparallel clause can be used to bypass parallelism in table creation. Finally, defining instances is optional, and should be used only in conjunction with a parallel configuration.
CREATE TABLE employees
…
PARALLEL(DEGREE 3 INSTANCES DEFAULT);
Even when parallel DML is enabled for the session, there is still no guarantee that it will be used when the user issues a DML statement. To ensure use of parallel DML, the user must include a special directive called a hint. Hints have been around for some time in Oracle7, used mainly for performance tuning. A hint is a directive sent to the Oracle SQL processing mechanism also known as the optimizer, telling it to process the SQL statement in a certain way. Hints can improve performance in situations where the SQL processing mechanism by default would pick an inefficient method to process the statement. Hints also override the parallelism set up in the create table statement. The specification of the parallel hint takes the form /*+parallel (tablename, degree_parallel) */ in the update, insert, or delete statement, as shown in the following example:
UPDATE /*+PARALLEL (employees,2) */
employees
SET salary = salary*1.08;
DELETE /*+PARALLEL (employees,4) */
FROM employees
WHERE to_number(substr(empid,1,1)) < 3;
The placement and syntax for the parallel hint is the same for update, delete, and insert DML operations. The parallel hint tells Oracle8 to run both the table scan to find data to change or remove and the actual data change or removal in parallel. The tablename and degree_parallel variables specified in the parallel hint of an update, delete, or insert statement override any values set for parallelism in the create table statement.
There are special considerations for parallel hints and two additional hints available for insert as select operations. Parallel hints can be specified both for insert and select portion of the insert as select statement. The two new hints available are for insert statements. Those new hints are append and noappend, and they indicate to the Oracle SQL processing mechanism that the insert statement should use the direct path. Some examples of the uses for direct path appear in the following code block:
INSERT /*+APPEND */
INTO employees
AS SELECT /*+PARALLEL(people,5) */
FROM people;
INSERT /*+NOAPPEND */
INTO employees
AS SELECT /*+PARALLEL(people,5) */
FROM people;
INSERT /*+PARALLEL(employees,5) */
INTO employees
AS SELECT /*+PARALLEL(people,5) */
FROM people;
Parallelism is determined in light of several factors. The degree and instances options in the parallel clause of the create table statement set up default levels of parallelism, while the tablename and degree_parallel variables specified as part of the parallel hint for DML statements override the default parallelism. At the hardware level, the number of processors available on the machine hosting Oracle will influence parallelism as well. The number of partitions can also influence the parallelism of DML statements.
As stated earlier, parallel DML statements must be committed or rolled back before another select or data change operation can be issued in the session. No lock table or select for update statements can be run in the same transaction as one containing parallel DML. No self-referential integrity, on delete cascade, or deferred enforcement of integrity may occur during parallel DML operations either. Parallel insert statements cannot occur on tables with global indexes, nor can parallel update statements operate on columns for which there are unique indexes. No parallel DML operation can execute on a bitmap index, tables containing LOBs, or clustered tables. Triggers are not fired when parallel DML occurs, so some additional PL/SQL procedures or constraints may need to be created if enforcement of constraints or replication occurs as a result of a trigger.
Failure on a transaction during instance or system recovery containing a parallel DML statement causes SMON to roll back the transaction one I/O process at a time. This means that rollback can take longer than the original statement took to execute. To execute rollback in parallel, the parallel DML statement should be rerun. This will lock the resources that failed to allow recovery in parallel so that the statement can execute again. When the parallel DML operation completes again, the user can either commit or roll back as necessary. If single or multiple I/O processes running in parallel fail, PMON rolls back the work of those processes one at a time while the rest of the I/O processes execute their own rollback. If the coordinating process fails, PMON recovers that process while all the I/O processes recover their own work in parallel.
There are several dictionary views with which the user can find information about parallel DML. The V$ performance view V$PQ_SYSSTAT can be used to find out information about parallel DML in addition to parallel queries in Oracle8. This view now contains a new statistic called "DML Initiated." The value for this statistic identifies how many parallel DML operations are running on the database. The V$PQ_SESSTAT view also has a new statistic that it captures, called "DML Parallelized," which tracks both whether parallel DML was used on the last query and on how many parallel DML statements have been issued, total, for the session. The V$SESSION view also contains a new column, called PDML_ENABLED, listing whether parallel DML is enabled for the session.
A useful, though sometimes dangerous, method can be used to speed the operation of parallel DML insert operations. This involves the use of the logging or nologging options, and they are set for a table—not for a transaction—using the alter table name logging. The logging keyword can be substituted with nologging to turn off the creation of redo log information for insert operations on this table. Although this process will speed the insert operation at hand, it will also make it impossible for the DBA to recover the transaction from archived redo log information. For compatibility with Oracle7, the unrecoverable option can still be specified for many operations to turn off redo log entry creation, as well.
In this section, you will cover the following topics related to LOB datatypes:
| Creating and altering the LOB datatypes | |
| Comparing LONG and LOB datatypes | |
| Data and object management with internal and external LOBs | |
| Using the DBMS_LOB package |
There are several drawbacks inherent in the use of LONG and LONG RAW datatypes in Oracle7 database tables. First, the use of either datatype is limited to only one column in the database table. If the object is large, the storage of that object inline with other table data almost invariably leads to chaining, which has its own host of performance issues, already discussed. Passing LONG and LONG RAW data back and forth between client and server, or between PL/SQL procedures and functions, proves difficult as well. Oracle has answered these issues by creating new and different datatypes for the storage of large objects—the LOB datatypes. This section will cover the usage and function of each of the LOB datatypes, the benefits and restrictions of each, and also some dictionary views that can be used in order to find information about the LOB datatypes used in the Oracle8 database.
Four new datatypes for storing large objects exist in Oracle8: BLOB for binary large object, CLOB for character large object, NCLOB character large object for multibyte character sets (similar to NCHAR and NVARCHAR2), and BFILE for binary files stored outside the database. All LOBs are stored within the database, except for BFILE. Thus, BLOB, CLOB, and NCLOB large objects are all considered internal LOBs while the BFILE large object is an external LOB. LOBs have two components: the value and the locator. The LOB value is the actual data that comprises the large object, while the locator is a pointer to the actual location in Oracle8 or external to Oracle8 where the data is actually stored. In cases where the LOB value is more than 4,000 bytes, only the LOB locator is stored in a table, and the value is stored in another segment external to the table—except for BFILE, which is stored outside the Oracle8 database. For LOB values less than 4,000 bytes, the value is stored inline with the rest of the table data.
LOB datatypes are used in table and variable declarations in the same way as other object types, with the definition of the type followed by the use of it. For more information on creating object types, review Chapter 22. Several attributes in an object type or table can be defined as LOBs. To populate a LOB, the DBMS_LOB package can be used, or an external application can do it with the Oracle Call Interface (OCI). LOBs can be used in table definitions, user-defined types, bind variables in SQL, host variables in programs, PL/SQL variables, and return values. The following code block illustrates the use of LOBs in object types and table definition:
CREATE TYPE vacation_grafx_type AS OBJECT
(picture BLOB);
CREATE TABLE vacation_planner (
location VARCHAR2(40),
picture vacation_grafx_type,
itinerary CLOB);
The VACATION_PLANNER table is then represented by five different segments: one each for the inline table data like the LOCATION column, PICTURE locator, and ITINERARY locator, and both a LOB and a LOB index segment for PICTURE and ITINERARY. The index segment is used to store locations for pieces of each LOB stored in different data blocks of the segment. Since the LOBs in this table definition are all internal, the tablespaces to store each of the identified segments and other storage options can be defined in an additional clause called lob. The options in this clause are defined as follows:
| chunk Identifies a contiguous number of blocks that will be chained to store information for the LOB. A LOB can be stored in several chunks of equal size. | |
| pctversion Identifies an amount of the LOB that must be changed before Oracle will attempt to reuse empty chunk space; it is designed to replace rollback segment usage in conjunction with LOBs. | |
| cache Tells Oracle to use the buffer cache for reading and writing LOB information. | |
| nocache logging Tells Oracle not to use the buffer cache for reading and writing LOB information, but to write changes to the redo log. | |
| nocache nologging Tells Oracle not to use the buffer cache for reading and writing LOB information and not to write changes to the redo log. | |
| tablespace Identifies a tablespace into which LOB value information should be placed. | |
| storage Standard storage clause, allows for definition of pctfree, pctused, and other storage clauses. | |
| index Storage clauses for the related index used to manage LOB storage can be identified, including inittrans num, maxtrans num, tablespace name and storage storage_clause. |
When data changes in LOBs, Oracle treats the chunk with the same read consistency as the block is treated for other database objects. For all intents and purposes, a chunk is the base unit of storage in a LOB, even though each chunk consists of many blocks. The following code block illustrates these clauses in action in the definition of LOB storage for a table:
CREATE TABLE book
(title VARCHAR2(40),
author VARCHAR2(40),
text CLOB,
author_pic BLOB)
LOB(text,author_pic) STORE AS(
STORAGE(INITIAL 1M NEXT 1M PCTINCREASE 0)
CHUNK 50
PCTVERSION 30
NOCACHE LOGGING
INDEX (STORAGE (INITIAL 1M NEXT 1M))
);
Oracle is able to access data outside of its own management control with the use of BFILEs. However, Oracle may only read this data. Read access to this data must be given at the operating system level to Oracle. If a change needs to be made to the data, the user must use whatever mechanisms are required outside of Oracle to make the change. This may include text editors, graphics editors, a sound clip editor, and so on. The creation of a BFILE within the database is similar to the creation of other columns in tables of LOB types. The following code block demonstrates the use of BFILE:
CREATE TABLE word_processing_docs
(doc_name VARCHAR2,
doc_content BFILE);
Since the BFILE storage is managed by the operating system and the modification by another software component, there is no need to allocate storage for a column or object of type BFILE. However, the location of the data in the BFILE must be identified to Oracle as a new object called a directory. The directory object specifies the pathname used to access the external object, and it can be granted to Oracle users as other object privileges are, enabling an additional layer of filesystem access security managed by Oracle. The creation of a directory object is done with the create or replace directory statement. Removal is done with the drop directory statement. The creation and removal of a directory are demonstrated in the following code block:
CREATE OR REPLACE DIRECTORY wp_docs
AS ‘/DISK01/usr/docs/wp_docs’;
DROP DIRECTORY wp_docs;
As with the creation of library objects, there is no check at the time of directory creation that the pathname is valid. Oracle will give an error only when the directory and external file are accessed. If the directory doesn’t exist when the directory object is created, Oracle will NOT create it. Access to that directory is managed by the operating system; the DBA should make sure Oracle has access to it before allowing users to refer to the LOB. System privileges to create and remove directories are consistent with other privileges: create any directory and drop any directory. There is only one object privilege, read, granted to users who will be able to access the BFILE. To grant the object privilege, the grant read on directory name to user statement should be used. Creation and granting read privileges on directories can both be audited as well.
There are several key differences between LONG and LOB types that make LOB types more versatile and helpful in large object management in Oracle databases. The first difference relates to the number of columns per table and the LONG and LOB types. There can be only one LONG column in a table, because the LONG column data is stored inline. In contrast, there can be many LOB columns in a table, because in situations where the LOB value is over 4,000 bytes, only the locator data for the LOB type is stored inline with the table data—in other words, no LOB will ever require more than 4,000 bytes of space inline with other table data. Thus, select statements on LONG columns return the actual data, while the same statement on a LOB column returns only the locator. Oracle supports use of the LOB types in object types except NCLOB, while LONG does not. LOBs can also be larger than LONGs—4G for LOBs vs. 2G for LONGs. LOB data can also be accessed piecewise while LONG access is sequential; only the entire value in the LONG column can be obtained, while parts of the LOB can be obtained.
Interaction with LOBs is provided in SQL, the DBMS_LOB package, and OCI release 8. The most extensive interaction with LOBs in Oracle is provided through the OCI and DBMS_LOB route, while only limited interaction is provided by SQL. The most effective way to manage access to internal LOBs is to lock the row with a select for update statement and access the LOB via DBMS_LOB. If the user would like to create a row in the table by populating the LOB column with NULL, the empty_blob( ) or empty_clob( ) operations can be used. The following code block can be used to show the population of LOB data:
INSERT INTO book VALUES
(‘Death in Venice’, ‘Thomas Mann’, EMPTY_CLOB(), EMPTY_BLOB());
Later, other rows can be updated with that NULL value by referencing the LOB in the row already populated. Alternately, a host variable in embedded SQL can be used to assign the LOB to a value, so long as the type of the host variable matches the LOB type for the table column. However, the OCILobWrite( ) operation is the fastest method to populate data to an LOB type. PL/SQL allows manipulation of LOBs directly as well. Using the DBMS_LOB.write( ) procedure, the developer can create a PL/SQL process that updates data in the LOB. The following code block illustrates this:
DECLARE
my_text_handle CLOB;
my_buffer VARCHAR2(4000);
my_amount NUMBER := 0;
my_offset INTEGER := 1;
BEGIN
my_buffer := ‘Gustave Aschenbach—or von Aschenbach, as he had been known
officially since his fiftieth birthday—had set out alone from his house in Prince
Regent Street, Munich, for an extended walk.’;
my_add_amt := length(my_buffer);
SELECT text
INTO my_text_handle
FROM book
WHERE title = ‘Death in Venice’ FOR UPDATE;
DBMS_LOB.WRITE(my_text_handle, my_add_amt, my_offset, my_buffer);
COMMIT;
END;
Notice the select statement to obtain the locator information for the LOB. The my_text_handle variable doesn’t actually contain the LOB data—remember, the table only stores the locator to the data. Removal of LOB data can be accomplished with the same SQL statements as used in other situations. The alter table truncate and delete statements are both useful for eliminating the LOB along with the rest of the row, or, again, the empty_clob( ) or the empty_blob( ) operations can be used simply to eliminate the LOB data. Dropping the table also removes the LOB. One exception is the removal of BFILE information. Even though the BFILE locator is eliminated in any of the three options put forth for deleting LOB data, the actual BFILE will still exist after they are deleted and can only be eliminated using operating system commands.
The DBMS_LOB package handles LOB operations. It is created with the dbmslob.sql and prvtlob.plb files, which are executed by running the catproc.sql script when the database is first created. For more information on creating a database, see Chapters 6 and 25. The maximum size for LOBs is also defined when DBMS_LOB is created to be 4,294,967,294, measured in characters for CLOB and NCLOB and in bytes for BFILE and BLOB. All locks for manipulating data in LOB columns other than BFILE need to be acquired before the call is made to a DBMS_LOB procedure. No special security is provided with DBMS_LOB; all procedures and functions in the DBMS_LOB package are run with the privileges of the owner of the procedure calling them. There are two categories for functions and procedures in this package: mutators and observers. The difference is that mutators change data in the LOB column while observers only read the LOB.
Special conditions apply to the variables used for the procedures and functions in DBMS_LOB. If a NULL value is passed as value for any variable to a function, NULL will be the return value. If a negative offset, amount, or range number is passed in, the function or procedure will return a corresponding error. The default value for offset is 1, which is the first byte or character in the LOB. Several of the procedures and functions in the DBMS_LOB package are overloaded to support CLOB, BLOB, or NCLOB types.
This procedure allows the user to add the contents of one LOB to another. Both LOBs must be the same type. A destination BLOB or CLOB and a source BLOB or CLOB must be passed to append( ) in the form append(destination,source). The return data from append( ) will be the destination LOB.
This procedure allows the direct comparison of LOBs of the same type or BFILEs to one another for equality. The call to compare( ) looks like the following: compare(obj1,obj2, amount). The objects passed can be BLOB, CLOB, or BFILE datatypes. The amount variable defines a maximum number of bytes (BLOB,BFILE) or characters (CLOB) to compare, and defaults to the maximum value permitted, 4,294,967,294. It returns an integer result: 0 if the two objects are equal, -1 if the first object is larger, and 1 if the second object is larger.
This function copies data from one LOB to another, either in its entirety or partially. Calls to copy( ) look like copy(destination, source, amount, destination_offset, source_offset). If no value is specified for either object’s offset, a default value of 1, for the beginning of the LOB, is used. The amount specifies the amount of each LOB to copy. If the offset specified for the destination is larger than the actual size of the LOB, then zero-byte or space filler is written from the end of the BLOB or CLOB to the beginning of the new data copied, respectively.
This procedure eliminates a specified amount of data from the BLOB or CLOB. Calls to erase( ) look like erase(lob, amount, offset). The amount is the number of bytes or characters that will be erased from the BLOB or CLOB, respectively. The offset tells erase( ) where to start. The default for offset is 1. If there is to be data left at the end of the BLOB or CLOB when erase( ) is done, either zero-byte or space filler will be substituted for the original data.
This closes a specified open BFILE. The call to fileclose( ) is fileclose(bfile).
This closes all open BFILEs. The call to filecloseall( ) is filecloseall( ).
This determines if the file exists that is pointed to by BFILE. It returns 1 if it exists, 0 if not. The call to fileexists( ) is fileexists(bfile).
This identifies the directory object name and the operating system filename for a given BFILE. The call to filegetname( ) is filegetname(bfile, directory_obj, filename). The directory_obj and filename variables are output variables, so they needn’t have values set for them.
This determines if the given BFILE is open. The call to fileisopen( ) is fileisopen(bfile).
This opens a given BFILE. The call to fileopen( ) is fileopen(bfile, openmode). The openmode variable defaults to read only access, because BFILEs cannot be modified in Oracle8.
This copies data in an external BFILE into an internal LOB. The call to loadfromfile( ) is loadfromfile(destination, bfile, amount, destination_offset, source_offset). The source and destination offsets default to 1 if not specified. The amount variable must be specified.
This determines the length of BLOB, CLOB, or BFILE large object. The call to getlength( ) is getlength(lob_or_bfile).
This obtains the corresponding position of a pattern match in a given LOB or BFILE. The call to instr( ) is instr(lob_or_bfile, pattern, offset, occurrence). Both offset and occurrence default to 1 if none are specified. The pattern can either be of type VARCHAR2 for CLOB or RAW for BLOB.
This obtains data from the BFILE or LOB starting from an offset position and continuing for a specified amount of blocks. Data is then placed in a buffer. Data returned is type VARCHAR2 for CLOB and RAW for BLOB and BFILE. The call to read( ) is read(lob_or_bfile, amount, offset, buffer).
This returns a substring of data from the LOB or BFILE starting at the offset, including the number of bytes or characters specified by amount. It is identical in concept to the single-row operation of the same name covered in Chapter 1. The call to substr( ) is substr(lob_or_bfile, offset, amount).
This changes the amount of data in the LOB by the amount specified by new_length. All data past that new length is cut off. The call to trim( ) is trim(lob, new_length).
This places a specified buffer of data of size amount into the LOB starting at the position specified by offset. The call to write( ) is write(lob, amount, offset, buffer).
In this section, you will cover the following topics related to advanced queuing with DBMS_QUEUE:
| Defining advanced queuing concepts | |
| Creating and sending messages with enqueue( ) | |
| Processing messages with dequeue( ) | |
| Administering the queues and the queue table |
Consider the most obvious fact about an online application—you issue a command, and the application executes it immediately. This is known as synchronous, or online, processing because of the synchronization of cause and effect. You say do it, and the application does it—hence, you have an online system. Another concept in data processing is the batch processing system. Instead of happening immediately, a batch process happens as an event. Mainframe users are familiar with the idea of submitting a job to be processed later. Both mainframe and UNIX users may also be familiar with a similar concept—job scheduling. You take a batch process, schedule it to run at a specific time via CRON or another scheduling utility, and the operating system executes the job at the appropriate time. However, without the right tool to manage scheduling, take note of any runtime errors or exceptions, and notify the appropriate person or process, no developer may ever notice when a batch job has failed until the user notices—and by then its too late. Oracle has built on concepts of job scheduling and sending messages between processes to notify others of progress. The result is advanced queuing—the topic of this section.
Queuing makes it possible to handle complex business process dependencies to complete or defer work. Many times, it is important that a process complete its task on time even when systems go down or other processes don’t complete their work in time. Queuing is designed to fulfill this task by allowing advanced interprocess communication along with transaction monitoring capability. The result is an efficient queuing architecture within the Oracle database—eliminating the need for middleware in the delivery of effective business processing management and workflow software using Oracle8, because the software tools needed for messaging are built into the database.
In systems that don’t use Oracle8 for queuing, the task of developing interprocess message flow is complex. Error checking must be coded into each component of the entire application, and connections must be built from each component into a separate message repository. The resultant "application within an application" is complex, prone to breakage, and entirely dependent on technology that may not even be designed to handle this type of work. Thus, even well-designed systems may not provide all the support an organization needs for business processing. If components are provided for messaging from different vendors, it is usually up to the buyer to design the interface between the application and the messaging software. And support burdens fall entirely on the organization that designed it.
With advanced queuing in Oracle, all application logic can exist within the Oracle database and application. Each component of the application connects to the other components with a messaging system integrated into the kernel. What is a message? A message is the most atomic unit of work executed within a transaction. A message consists of two parts: data and control information. The user process or application provides the data used in executing the transaction. Control information consists of the time to execute, priority, process dependencies, and other things. This control information comes from the application. Figure 23-2 illustrates the concept of advanced queuing.
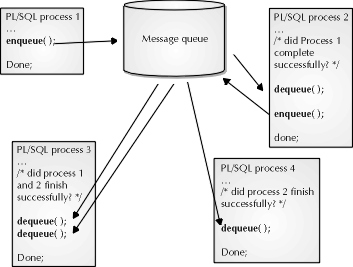
Figure 2: Pictorial representation of advanced queuing
This information is queued by the application and read by other applications using procedures called enqueue( ) and dequeue( ), which are found in a PL/SQL package called DBMS_AQ. Messages are placed in a message queue for review by enqueue( ) and read by other components with dequeue( ). A message queue is stored in a queue table in the database designed to store messages. Several queues can exist in each queue table, and several queue tables can exist in the database. The creation and management of queues and queue tables is handled by another package called DBMS_AQADM, which will be discussed later in the section.
The benefits of queuing are many. First, queuing and queue tables allow the identification of discrete units of work and their execution status. This information can be retained by the queue table for as long as needed, effectively keeping a repository or "message warehouse" of this information. This repository forms the foundation for event tracking and tracking relationships between messages. The business processes modeled by the application are more evident and thus more traceable. Patterns in data processing can be detected, leading to "message mining," which can then be used to identify improvements to streamline processes. A more complete list of the advantages of Oracle8 advanced queuing is given here.
| The ordering and prioritizing of messages is possible | |
| Identifiers can be used to correlate different messages | |
| Reply queues can be used, along with exception queues, to identify when there are problems | |
| Applications can browse messages, specify multiple recipients, group messages to form a thread, differentiate between transactions and queries, use object types, and even mark time constraints. |
Before using enqueue( ) or dequeue( ), the DBA may want to set the AQ_TM_PROCESSES initialization parameter to 1 to create one time manager process to support time management on the queues on the Oracle8 instance. Several options depend on the use of a time manager, such as the expiration, delay, and timed retention. The default value is 0. In future versions, Oracle may support the use of more than one time manager, but for the time being, setting AQ_TM_PROCESSES to a value higher than 1 results in error.
There are several dictionary views available for finding information about the queues in the Oracle database. These dictionary views include DBA_ or USER_QUEUE_TABLES, which lists the queue tables available on the entire database or those queue tables owned by the user issuing the query. Also, information about individual queues in the database can be found in the DBA_ or USER_QUEUES dictionary view. Finally, each queue table has its own special view that can be used to access queue information. The name for that view will depend on the queue table, but the general format for the view name is AQ$QUEUE_TABLE_NAME.
DBMS_AQ contains the enqueue( ) procedure used to handle the placement of messages on a message queue. Privileges for using the DBMS_AQ package are given initially only to SYS, but can be granted to others in the database who have the role AQ_USER_ROLE granted to them. A call to the DBMS_AQ.enqueue( ) procedure looks like DBMS_AQ.enqueue(queue_name, enqueue_options, message_properties, payload, msg_id). All variables identified are input, except msg_id, which is the handle for the message enqueued and is returned by the enqueue( ) procedure. The usage of each variable is given here.
This is a VARCHAR2 datatype, and it specifies the name of the queue to which this message should be enqueued. The value for queue_name specified should not be an exception queue, because messages are moved to the exception queue only by the queuing system itself.
This is a DBMS_AQ.ENQUEUE_OPTIONS_T type. This variable is really three variables in one, because this type is a record. When using the DBMS_AQ package, the application should declare the variable used to pass values into this variable with the DBMS_AQ.ENQUEUE_OPTIONS_T type. The three subvariables are visibility, relative_msgid, and sequence_deviation. A sample definition of this variable appears in the following code block, and the explanation of their use and values follows the block:
DECLARE
my_enq_opts := DBMS_AQ.ENQUEUE_OPTIONS_T;
BEGIN
my_enq_opts.VISIBILITY := DBMS_AQ.IMMEDIATE;
my_enq_opts.RELATIVE_MSGID := ‘02AB9AD2FG4859C5’;
my_enq_opts.SEQUENCE_DEVIATION := DBMS_AQ.TOP;
…
| visibility Defines transactional behavior of the queued request. Can be set to on_commit, meaning the enqueued message is part of the current transaction and that the operation will be complete when the transaction commits. On_commit is default value. Alternately, can be set to immediate such that the enqueued message is its own transaction, not part of the current transaction. | |
| relative_msgid Only relevant when before is used in sequence_deviation. This variable defines the message identifier referenced in sequence_deviation. | |
| sequence_deviation Identifies whether the message enqueued should be dequeued before other messages in the queue. One of the values permitted is before, meaning that this message should be dequeued before the message defined by relative_msgid above. Alternately, top can be specified for this variable, meaning this message is dequeued before any other messages. Alternately, NULL says this message is dequeued in regular order. NULL is default value. |
DBMS_AQ.MESSAGE_PROPERTIES_T type. In the same way as enqueue_options, the message_properties variable has several subvariables used to define its meaning. When using the DBMS_AQ package, the developer should declare a variable to populate with the values required for this structure using the same type as this structure uses. This variable has nine subvariables: priority, delay, expiration, correlation, attempts, recipient_list, exception_queue, enqueue_time, and state. An example for defining this variable appears in the following code block, and a description of the subvariables appears after that. In the example, a message called "DINNER TIME" is enqueued with a priority of –3 to consumers DINAH, ATHENA, and SPANKY, immediately available for their dequeuing. The message will be available for five minutes, after which time it will be placed in the NOT_HUNGRY_EXCEPTION_Q.
DECLARE
my_msg_props := DBMS_AQ.MESSAGE_PROPERTIES_T;
subscriber := DBMS_AQ.AQ$_RECIPIENT_LIST_T;
my_enq_opts := DBMS_AQ.ENQUEUE_OPTIONS_T;
BEGIN
my_msg_props.PRIORITY := -3;
my_msg_props.DELAY := DBMS_AQ.NO_DELAY;
my_msg_props.EXPIRATION := 300;
my_msg_props.CORRELATION := ‘DINNER TIME’
-- my_msg_props.ATTEMPTS not set at time of enqueue
subscriber := SYS.AQ$_AGENT(‘DINAH’,NULL,NULL);
subscriber := SYS.AQ$_AGENT(‘SPANKY’,NULL,NULL);
subscriber := SYS.AQ$_AGENT(‘ATHENA’,NULL,NULL);
my_msg_props.RECIPIENT_LIST := subscriber;
my_msg_props.EXCEPTION_QUEUE := ‘NOT_HUNGRY_EXCEPTION_Q’;
-- my_msg_props.ENQUEUE_TIME not set by user
-- my_msg_props.STATE not set by user
my_enq_opts.VISIBILITY := DBMS_AQ.IMMEDIATE;
my_enq_opts.RELATIVE_MSGID := ‘02AB9AD2FG4859C5’;
my_enq_opts.SEQUENCE_DEVIATION := DBMS_AQ.TOP;
…
| priority Specifies the priority of the message numerically. Both negatives and positives are allowed; the lower the number, the higher the priority. | |
| delay Identifies a delay, in seconds, during which time the message may not be dequeued. Alternately, no_delay may be specified for this variable. It relies on the setting of the time manager. | |
| expiration Defines how long the message is available for dequeuing, in seconds, after which time the message expires. Alternately, never may be specified for this variable. | |
| correlation Identifies the message with a name. | |
| attempts Number of times other consumers attempted to dequeue( ) the message. This is not set at time of enqueue( ). | |
| recipient_list Can be used only for queues allowing multiple consumers. Default recipients are the subscribers to the queue. Values for this variable cannot be returned in a dequeue( ). The recipient list can be defined with another variable, of type SYS.AQ$_AGENT, which takes three variables: name, address, and protocol, of datatypes VARCHAR2, VARCHAR2, and NUMBER, respectively. | |
| exception_queue Messages moved to the exception queue after value for expiration has passed, or if attempts exceed the maximum number of attempts allowed for the queue. | |
| enqueue_time Set internally by the system as the time enqueue( ) deposited the message. | |
| state The current state of the message. This has four possible values: waiting if the message is still in delay, ready if the message can be obtained via dequeue( ), processed if the message is processed and retained, and expired if the message moved to the location defined by exception_queue. |
Either an object type correlated to the column of the queue table, where it will be stored, or RAW. This is the actual "message." When enqueued, the queue returns a unique message identifier to the processes using enqueue( ).
-- payload type declaration
CREATE TYPE message_type
AS object (name VARCHAR2(10), text VARCHAR2(100));
-- anonymous PL/SQL block
DECLARE
my_msg_props := DBMS_AQ.MESSAGE_PROPERTIES_T;
subscriber := DBMS_AQ.AQ$_RECIPIENT_LIST_T;
my_enq_opts := DBMS_AQ.ENQUEUE_OPTIONS_T;
my_message message_type;
my_msgid RAW;
BEGIN
my_msg_props.PRIORITY := -3;
my_msg_props.DELAY := DBMS_AQ.NO_DELAY;
my_msg_props.EXPIRATION := 300;
my_msg_props.CORRELATION := ‘DINNER TIME’
-- my_msg_props.ATTEMPTS not set at time of enqueue
subscriber := SYS.AQ$_AGENT(‘DINAH’,NULL,NULL);
subscriber := SYS.AQ$_AGENT(‘SPANKY’,NULL,NULL);
subscriber := SYS.AQ$_AGENT(‘ATHENA’,NULL,NULL);
my_msg_props.RECIPIENT_LIST := subscriber;
my_msg_props.EXCEPTION_QUEUE := ‘NOT_HUNGRY_EXCEPTION_Q’;
-- my_msg_props.ENQUEUE_TIME not set by user
-- my_msg_props.STATE not set by user
my_enq_opts.VISIBILITY := DBMS_AQ.IMMEDIATE;
my_enq_opts.RELATIVE_MSGID := ‘02AB9AD2FG4859C5’;
my_enq_opts.SEQUENCE_DEVIATION := DBMS_AQ.TOP;
my_message := message_type(‘clause’,’We are hungry!’);
DBMS_AQ.ENQUEUE(‘MY_QUEUE’,
enqueue_options=>my_enq_opts,
message_properties=>my_msg_props,
payload=>my_message,
my_msgid);
…
MSGID is a RAW datatype. This is the handle by which the process enqueuing or dequeuing can refer to the message.
The dequeue( ) procedure retrieves messages from the message queue. Privileges for use of this procedure are initially only granted to SYS, but can be given to other users with the AQ_USER_ROLE. Calls to dequeue( ) have the following variables defined: DBMS_AQ.dequeue(queue_name, dequeue_options, message_properties, payload, msgid). The queue_name and dequeue_options variables are input, while the other three are output. The messages to be dequeued are determined by the consumer attempting to dequeue( ) the message and several subvariables of dequeue_options. Only messages in the ready state may be dequeued unless a specific msgid is given as a subvariable for dequeue_options. Order of messages dequeued is determined by the queue table unless the order was overridden in the enqueue( ) for that message.
This is a VARCHAR2 datatype used to identify the name of the queue from which messages are dequeued.
This is a DBMS_AQ.DEQUEUE_OPTIONS_T type. When creating variables to be passed to dequeue( ) in the application, use the same type this variable is declared with. Seven subvariables exist for this type: consumer_name, dequeue_mode, navigation, visibility, wait, msgid, and correlation. An example for the definition of the dequeue_options variable is listed in the following code block, and then after that the subvariables are explained.
DECLARE
my_dq_options := DBMS_AQ.DEQUEUE_OPTIONS_T;
BEGIN
my_dq_options.CONSUMER_NAME := ‘DINAH’;
my_dq_options.DEQUEUE_MODE := DBMS_AQ.REMOVE;
my_dq_options.NAVIGATION := DBMS_AQ.FIRST_MESSAGE;
my_dq_options.VISIBILITY := DBMS_AQ.IMMEDIATE;
my_dq_options.WAIT := DBMS_AQ.NO_WAIT;
my_dq_options.MSGID := NULL;
my_dq_options.CORRELATION := ‘DINNER TIME’;
…
| consumer_name Name of the application, process, or user receiving the message. Should be NULL for queues not set up to handle more than one consumer. | |
| dequeue_mode Specifies locks, if any, to be acquired on the message by the dequeue( ) process. Can be browse for read only access similar to that used in select statements; locked for the ability to write to the message during the transaction, similar to a share lock acquired in a select for update statement; or remove for the ability to read the message, updating it or deleting it. The message is retained according to properties set in queue table creation. | |
| navigation Determines the position of the message to be retrieved, the first step in retrieving messages. The second step is applying search criteria. The navigation variable can have one of three values. The next_message value is used for retrieving the next message available that matches search criteria. Alternately, next_transaction is used to skip remaining messages in the current transaction group and retrieve the first message of the next transaction group. Alternately, first_message is used to retrieve the first message that fits the search criteria, resetting the position to the beginning of queue. | |
| visibility Defines visibility of the message within the transaction of the application dequeuing it. Values are on_commit if the message dequeued is part of the current transaction or immediate if the message is its own transaction. | |
| wait Specifies how long to wait if an attempt is made to dequeue( ) a message and there is no message to retrieve. Values are forever, no_wait, and num, where num represents the number of seconds it will wait. | |
| msgid The message identifier for the message to be dequeued. If specified, the message will be dequeued even if expired. | |
| correlation The name of the message to be dequeued. |
See the definition for message_properties in the discussion of enqueue( ). This is an output variable.
Defines the variable into which the actual dequeued message will be placed. Should be the same type as the column storing payload on the queue table.
The message identifier handle corresponding to the message dequeued.
Configuration of a queue table and the management of queues is handled with another package called DBMS_AQADM. This package defines several procedures and functions. Initially, only the SYS user can use the procedures and functions of DBMS_AQADM. However, additional users can be given access by granting them the role AQ_ADMINISTRATOR_ROLE. Configuration of a queue should be managed tightly, as improper configuration equals poor database performance. The role should be granted only to those users who really need it, such as the DBA, the queue administrator, or privileged users. A special procedure called grant_type_access( ) is included with Oracle8 that must be run as the first step in administering the appropriate privileges for advanced queue object types to other users. The call to grant_type_access( ) looks like grant_type_access(user), where user is the input variable specifying the name of the user that will have access to advanced queuing procedures and associated types.
There are two procedures for managing queue tables: create_queue_table( ) and drop_queue_table( ). All options for setup and removal of the queue tables into which all queues will be placed are handled with these procedures.
This procedure creates the queue table designed to store all queued messages for a queue or multiple queues with the same payload type. Objects created with a queue table include the table itself, a default exception queue called AQ$QUEUE_TABLE_NAME_E, a read only view for information on the queue table called AQ$QUEUE_TABLE_NAME, an index for time manager operations called AQ$QUEUE_TABLE_NAME_T, and an index or index-organized table to handle dequeuing on queues with multiple consumers called AQ$QUEUE_TABLE_NAME_I. A call to create_queue_table( ) looks like DBMS_AQADM.create_queue_table(queue_table, queue_payload_type, storage_clause, sort_list, multiple_consumers, message_grouping, comment, auto_commit).
This procedure removes an existing queue table from the database. The queues in the queue table must first be stopped and removed before the queue table can be dropped. The call looks like DBMS_AQADM.drop_queue_table(queue_table, force, auto_commit).
There are five procedures for managing the queues on a queue table. They are create_queue( ), alter_queue( ), start_queue( ), stop_queue( ) and drop_queue( ). The descriptions and general use of each procedure follows.
This procedure creates a queue and places it into a queue table. The queue table must first be created, or else this procedure will not be able to create the queue. There are two types of queues that can be created: normal queues and exception queues. The call to create_queue( ) looks like DBMS_AQADM.create_queue(queue_name, queue_table, queue_type, max_retries, retry_delay, retention_time, dependency_tracking, comment,auto_commit).
This procedure changes the definition for features of the queue. Calls to alter_queue( ) look like DBMS_AQADM.alter_queue(queue_name, max_retries, retry_delay, retention_time, auto_commit). Currently, only these variables are supported for change through the alter_queue( ) procedure.
Activates the queue for enqueuing only, dequeuing only, or both. The two variables for allowing either dequeues, enqueues, or both can be set to TRUE or FALSE. A call to start_queue( ) looks like start_queue(queue_name, enqueue, dequeue).
This procedure deactivates the queue for enqueuing or dequeuing usage. A queue cannot be stopped if there are active transactions against that queue. The two variables for allowing either dequeues, enqueues, or both can be set to TRUE or FALSE. A call to stop_queue( ) looks like stop_queue(queue_name, enqueue, dequeue).
This procedure removes a queue from the queue table if it has already been stopped. An active queue cannot be dropped from the queue table. A call to the drop_queue( ) procedure looks like drop_queue(queue_name, auto_commit).
The following procedures can be used to manage usage of time manager within the advanced queuing system. Available procedures are start_time_manager( ) and stop_time_manager( ). The actual time manager process is not started or stopped by these procedures, only the activity of time manager within the advanced queuing system is modified. The time manager process is actually started by specifying a value of 1 for the AQ_TM_PROCESSES initialization parameter before starting the Oracle instance. Once started, the process runs for the life of the instance.
This procedure causes the time manager to start operating. This process does not actually start the time manager process running; that function is handled with the AQ_TM_PROCESSES initialization parameter. There are no variables for this procedure, it is simply called with DBMS_AQADM.start_time_manager.
This procedure causes the time manager to stop operating. The actual time manager process will continue to run until the instance is shut down. There are no variables passed in the call to this procedure. The call looks like DBMS_AQADM.stop_time_manager.
The addition and removal of subscribers to a queue can be managed with two procedures in this set: add_subscriber( ) and remove_subscriber( ). Also, the set of subscribers for a particular queue can be found with the queue_subscribers( ) function.
A subscriber is added to a queue with this procedure. This operation is only allowed on queues that allow multiple consumers, and takes effect immediately. Calls to add_subscriber( ) look like DBMS_AQADM.add_subscriber(queue_name, subscriber).
A subscriber is removed from the queue with this procedure. This operation takes place immediately. The call is DBMS_AQADM.add_subscriber(queue_name, subscriber).
This function returns a PL/SQL table containing a list of subscribers for a named queue. The call is DBMS_AQADM.queue_subscriber(queue_name).
This chapter covered three important areas of Oracle8 new features, including the support of parallel DML in the database, new large object types, and the use of advanced queuing to provide for deferred execution of processes and messaging between processes. The material in this chapter will be tested on OCP Exam 5.
The first area covered was the use of parallel DML in the Oracle database. With the addition of partitioning on database tables, Oracle also provides improved facilities to handle DML operations like update, insert, and delete in parallel. Use of parallel DML offers several benefits to users and administrators, including increased performance for large-volume database changes. Oracle also handles parallelism automatically, which simplifies the use of parallel operations. In situations where partitioning is used, the parallelism of DML operations necessitates the use of partition-to-device mapping. This coordinating operation is handled implicitly, which frees the user from having to know the relationships of instance to disk to partition explicitly.
There are three types of parallelism available. They are parallelism by ROWID, parallelism by partitions, and parallelism by I/O processes. Parallelism by ROWID ranges are used when Oracle divides the work of selecting data from the database into several ranges by ROWID, and spawns multiple I/O processes to search each range. The ranges in turn may not span a partition. Another option is parallelism by partitions. This may only be used for partitioned tables. An I/O process is spawned to work in one and only one partition. This parallelism is used for update and delete statements in partitioned tables as of Oracle8. The final option is parallelism by parallel I/O processes. This process of parallelism is used for insert statements on either partitioned or nonpartitioned tables. Since inserted data does not have a ROWID yet, the data is divided equitably between the I/O processes spawned. Each process inserts data above the table’s highwatermark, which is then altered by the commit statement later.
Parallel DML must be enabled in the session before Oracle allows the user to use it. There is no instance-wide method for setup of parallel DML. The statement used to enable parallel DML is alter session enable parallel DML. Once enabled, parallel DML can be used for the entire session, or until the alter session disable parallel DML statement is issued to disable it. If a transaction contains parallel DML, the transaction must be committed or rolled back after issuing the parallel DML and before issuing another select or DML statement, or else an error will ensue. The DML statement may not always operate in parallel without the further issuance of a hint in the actual statement. Hints used are parallel for select, update, insert, and delete statements, and the append and noappend hints for insert statements to use direct load or not use it, respectively. One final performance improvement for parallel DML can be specified in a table. The table can be altered to specify that no redo log entries will be created by or DML statements issued on that table. The syntax for this statement is alter table name logging to turn redo logging on, or alter table name nologging to turn it off.
There are several dictionary views used to find information about parallel DML operations. The V$SESSION view contains a new column called PDML_ENABLED, which identifies if parallel DML is being used in that session. The V$PQ_SESSTAT has a new row called "DML Parallelized" to track statistics for parallel DML in sessions. Finally, a new row called "DML Initiated" has been added to V$PQ_SYSSTAT, to track system statistics in this category. Finally, transaction and process recovery for parallel DML can take a great deal more time to complete than the actual parallel DML operation. This is because the parallel DML statement must be rolled back serially in many cases.
This chapter also covered the new datatypes in Oracle8 for large objects. There are several new datatypes to support large objects in Oracle8, called binary large object (BLOB), character large object/NLS character large object (CLOB, NCLOB), and external binary file (BFILE). The differences between LONG/LONG RAW and the LOB/BFILE types are many, including twice the size allowed for LOBs, support for many LOB table and object columns(except for NCLOB), nonsequential access to data in the LOB, and storage out of line with the table data for LOBs.
A LOB consists of two components: a locator and the value. The locator is stored inline with the rest of table data, while the value is stored in another segment (BLOB/CLOB) if the size of the value is over 4,000 bytes, or external to Oracle (BFILE). LOBs have several storage aspects to be defined, such as the tablespace in which to store the LOB tablespace, the LOB index tablespace, and a host of other new storage options. Oracle supports a new unit of storage for LOBs, called a chunk. The chunk is composed of several contiguous blocks bound together in a segment. The number of blocks used in a chunk is specified by the chunk option. Although the blocks of a chunk need to be stored together, the LOB can be stored in noncontiguous chunks. If the data in a LOB is changed beyond a percentage threshold specified by the pctversion clause, then Oracle will reclaim unused space from the object for reuse. The use of the buffer cache in LOB read/write processing can also be specified with the cache or nocache options. Further, the redo logging of transactions that modify LOBs can be turned on or off if the nocache option is used with either logging or nologging.
BFILE objects are read only, because Oracle cannot manage the storage for the objects. For BFILE large objects, only the locator for the external object is stored in the Oracle database. An additional object is created for BFILEs, called a directory object, to identify the pathname to locate and read the object. A directory object is created with the create or replace directory name as ‘path’ statement. The path specified is operating system specific, and there may be some issues with migrating Oracle8 database directory objects from one operating system to another. On creation, Oracle will not verify whether the directory referenced by the directory object exists. If the filesystem directory doesn’t exist, Oracle will not create it. An error will be produced only at the time when the BFILE is referenced. Oracle recommends not creating directory objects that reference directories containing Oracle datafiles, redo logs, control files, password files, or the init.ora file.
To access the data in a LOB, the DBMS_LOB package or Oracle Call Interface can be used. An empty value can be placed in a LOB with the use of the empty_blob( ) or empty_clob( ) procedures. Several other procedures and functions are available in the DBMS_LOB package, divided into two categories: mutators and observers. Mutator procedures and functions include append( ), copy( ), erase( ), trim( ), write( ), fileclose( ), filecloseall( ), fileopen( ), and loadfromfile( ). The observer procedures include compare( ), filegetname( ), instr( ), getlength( ), read( ), substr( ), fileexists( ), and fileisopen( ).
The final area covered in this chapter is the use of Oracle advanced queuing. Queuing is the use of messages in the database to defer certain operations and to communicate execution status between two or more processes. The result is a seamless blend of database storage, application transaction processing, and messages—all managed within the Oracle architecture. A message is composed of two parts: user data and control information. The data is the actual transaction with its related data, and the control information determines things like when the message will run. Messages are stored in special database objects called queues, and they are placed into and read from queues with the use of two procedures in another new package of the Oracle architecture, called DBMS_AQ. The procedures of DBMS_AQ include enqueue( ) and dequeue( ), used for putting messages into queues and reading them from queues, respectively. Several of the variables for these procedures have their own user-defined types, coming from the package as well.
As stated, queues are stored in queue tables. The management of queue tables is handled with procedures and functions in another PL/SQL package called DBMS_AQADM. The procedures of this package fall into four categories: management of queue tables, management of queues, management of time manager, and management of subscribers. The procedures and functions of this package are create_queue_table( ), drop_queue_table( ), create_queue( ), drop_queue( ), alter_queue( ), start_queue( ), stop_queue( ), start_time_manager( ), stop_time_manager, start_time_manager, add_subscriber( ), remove_subscriber( ), and queue_subscribers( ). Two areas related to queuing are the use of the time manager and the dictionary views for use with queuing. The time manager is used in conjunction with several features of queuing, such as delayed dequeuing and message expiration. Time manager is a process that runs as part of the Oracle instance when the AQ_TM_PROCESSES initialization parameter is set to 1. The start_time_manager and stop_time_manager processes activate and deactivate the already running time manager. The advanced queuing feature has a few dictionary views available in conjunction with its use. One is DBA_QUEUE_TABLES, to identify information about all the queue tables on the database. Another is DBA_QUEUES, to identify information about the queues on the database. The last set of views are for every queue table on the database, called AQ$QUEUE_TABLE_NAME, where the name of the queue table is part of the view name.
| Oracle8 allows DML operations to run in parallel. | |
| Parallel DML offers performance benefits, automatic parallelism, and affinity between partitions and disks. | |
| There are three types of parallelism: parallelism by ROWID range, parallelism by partition, and parallelism by I/O process. | |
| Parallelism by ROWID range is used in select statements. | |
| Parallelism by partition is used in parallel update and delete statements. | |
| Parallelism by I/O process is used in parallel insert statements. | |
| The alter session enable parallel DML statement is used to enable parallel DML in a session. | |
| There is no way to institute parallel DML for an entire instance. | |
| When using parallelism by partition, only one I/O process can operate on a partition. | |
| When using parallelism by I/O process or by ROWID range, multiple I/O processes can access a single partition, or a nonpartitioned table, at once. | |
| Only one parallel DML operation is allowed per transaction. | |
| No DML or select statements may be issued after a successful parallel DML operation in a transaction. | |
| Even though all DML statements issued after parallel DML is enabled are considered for parallelism, not all statements will be executed in parallel. To guarantee parallelism in a DML statement, use the parallel hint, specified with the /*+parallel (tablename, degree_parallel) */ syntax. | |
| The degree of parallelism defined in the create table statement specifies the default degree of parallelism in DML and select statements issued on that table later. | |
| Parallel hints can be specified for both the insert and the select statement in an insert as select statement. | |
| The append or noappend hints are also available for insert statements, telling Oracle to use the insert direct path or not, respectively. | |
| The insert direct path is similar to the direct path available in SQL*Loader. | |
| New features have been added in support of parallel DML to the V$SESSION, V$PQ_SESSTAT, and V$PQ_SYSSTAT views in the form of new statistics collected in the latter two views and a new PDML_ENABLED column in the former view. | |
| Redo logging can be turned on and off on a per-table basis for insert statements only with the alter table name logging and alter table name nologging statements, respectively. | |
| Transaction and process recovery takes longer for parallel DML because usually the rollback process executes serially. | |
| No parallel DML is allowed on bitmap indexes, tables with LOBs or object types, or clustered tables, and parallel DML must be committed or rolled back before executing another DML statement. | |
| No parallel update on global unique indexes, and no parallel insert on any global index. | |
| The new LOB datatypes available on Oracle8 databases are BLOB, CLOB, NCLOB, and BFILE. There is no implicit conversion between LOB datatypes. | |
| LOBs have two components: value and locator. | |
| Differences between LONG/LONG RAW datatypes and LOB datatypes are size (2G vs. 4G), multiple LOB columns per table vs. one LONG/LONG RAW, LONG data is stored inline in the table vs. only LOB locators stored inline, and object types support LOBs (except NCLOB), not LONG/LONG RAW. Finally, access to LOB data is nonsequential, while LONG/LONG RAW data only permits sequential access to data in the column. | |
| LOBs have several storage considerations over and above normal objects. LOBs may have a tablespace defined to store the LOB value and another tablespace for the associated index. | |
| Oracle supports data storage for LOB datatypes with a new structure—a chunk. A chunk is a collection of blocks used to store LOB data. The blocks in the chunk must be contiguous, but the chunks used to store LOB data needn’t be. | |
| The number of blocks in a chunk is defined with the object containing the LOB. | |
| Oracle will attempt to reclaim unused blocks in a chunk if the amount of data changed in the space of the chunk exceeds a certain threshold. | |
| The LOB column can have a NULL value assigned to it with either the empty_blob( ) or empty_clob( ) procedure. | |
| Access to internal LOB data is managed by the DBMS_LOB PL/SQL package or the Oracle Call Interface. | |
| DBMS_LOB procedures and functions are divided into mutators and observers. | |
| The mutators include append( ), copy( ), erase( ), trim( ), write( ), fileclose( ), fileloseall( ), fileopen( ), and loadfromfile( ). | |
| The observer procedures include compare( ), filegetname( ), instr( ), getlength( ), read( ), substr( ), fileexists( ), fileisopen( ). | |
| The BFILE type is not stored in the Oracle database. Only the locator is stored in the database. BFILE objects are read only. | |
| To access an external object, a directory object must be created to identify its filesystem location. Creation of a directory object is done with create or replace directory name as ‘path’ statement. | |
| Creating a directory object in Oracle doesn’t create the underlying directory path in the operating system. There is also no check at the time the directory object is created to verify if the path exists. An error only occurs at the time the BFILE is referenced. | |
| Oracle8 supports advanced queuing of messages between multiple processes and the deferral of executing database operations. | |
| The fundamental unit of queuing is a message. | |
| Messages have two components: user data and control information. | |
| Messages are stored in a queue. | |
| Queues are stored in a queue table. | |
| Messages are put into a queue with procedures from the DBMS_AQ package. | |
| Grant_type_access( ) must be executed by SYS in order to manage access to advanced queue object types. | |
| The two procedures available in DBMS_AQ are enqueue( ) and dequeue( ). | |
| The management of queues and queue tables is done with the DBMS_AQADM package. The procedures of this package are create_queue_table( ), drop_queue_table( ), create_queue( ), drop_queue( ), alter_queue( ), start_queue( ), stop_queue( ), start_time_manager( ), stop_time_manager, add_subscriber( ), remove_subscriber( ), and queue_subscribers( ). | |
| The roles used for managing access to the DBMS_AQ and the DBMS_AQADM packages are AQ_USER_ROLE and AQ_ADMINISTRATOR_ROLE. | |
| Certain features of messaging such as dequeue delay and message expiration depend on the use of the time manager process. The time manager must be turned on as part of the start of the Oracle instance, by setting the AQ_TM_PROCESSES initialization parameter to 1. | |
| Available dictionary views for queuing are DBA_QUEUE_TABLES for queue tables, DBA_QUEUES for queues, and AQ$QUEUE_TABLE_NAME for each queue table in the database. |